Augmenting Document-level Relation Extraction with Efficient Multi-Supervision
2407.01026
0
0
Abstract
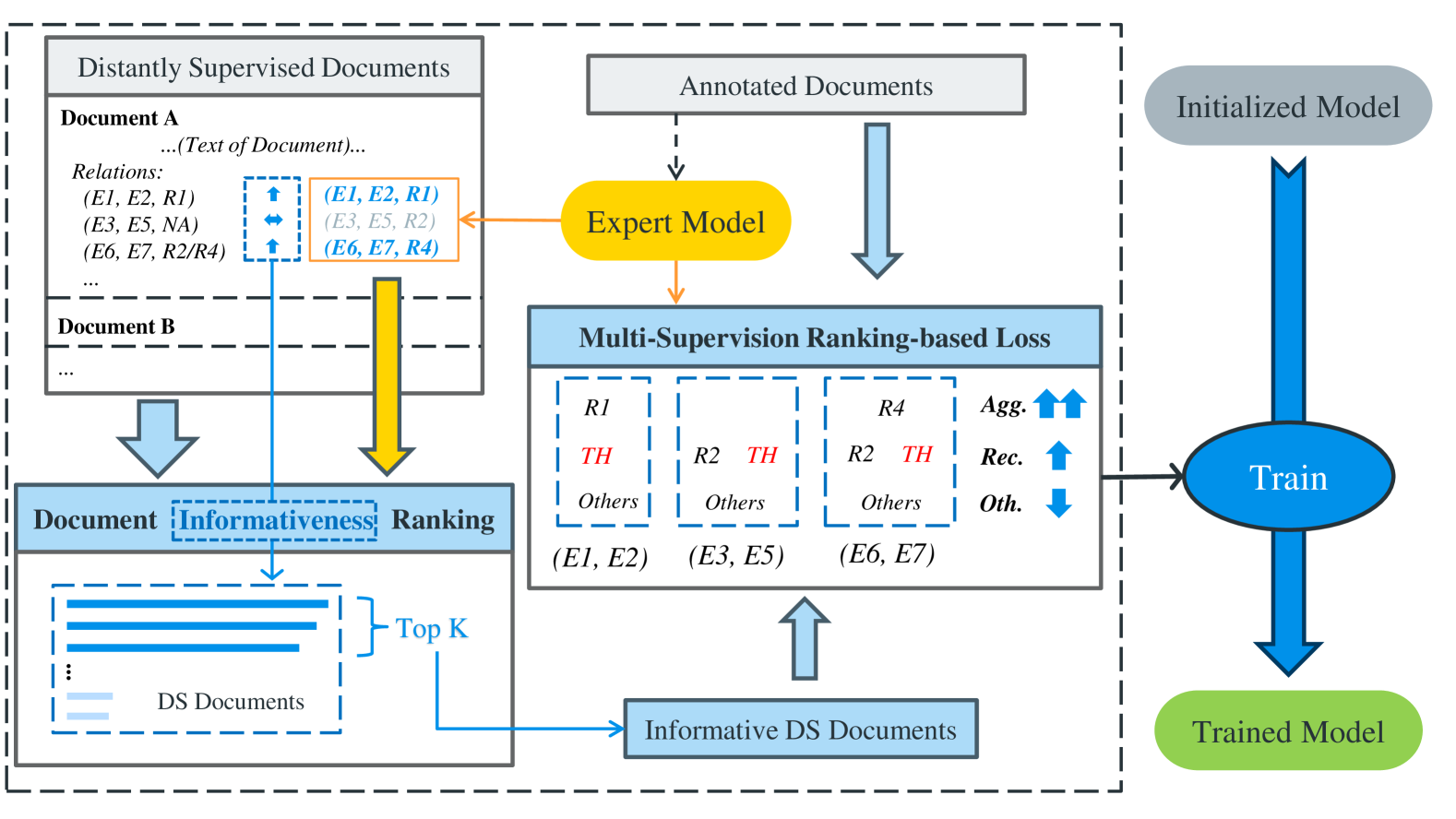
Despite its popularity in sentence-level relation extraction, distantly supervised data is rarely utilized by existing work in document-level relation extraction due to its noisy nature and low information density. Among its current applications, distantly supervised data is mostly used as a whole for pertaining, which is of low time efficiency. To fill in the gap of efficient and robust utilization of distantly supervised training data, we propose Efficient Multi-Supervision for document-level relation extraction, in which we first select a subset of informative documents from the massive dataset by combining distant supervision with expert supervision, then train the model with Multi-Supervision Ranking Loss that integrates the knowledge from multiple sources of supervision to alleviate the effects of noise. The experiments demonstrate the effectiveness of our method in improving the model performance with higher time efficiency than existing baselines.
Create account to get full access
Overview
- This paper proposes a novel approach to document-level relation extraction that leverages efficient multi-supervision to improve performance.
- The method combines distant supervision, self-supervision, and supervised learning to capture different aspects of the task and achieve better results.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, outperforming state-of-the-art models.
Plain English Explanation
Relation extraction is the task of identifying and classifying the relationships between entities (e.g., people, organizations, locations) in a given text. This is an important problem in natural language processing with applications in areas like information retrieval, knowledge base construction, and question answering.
Traditional relation extraction methods have focused on extracting relations at the sentence level, but real-world texts often contain information spread across multiple sentences or even the entire document. Document-level context-few-shot relation extraction and TTM-RE: Memory-Augmented Document-Level Relation Extraction are examples of recent work that has looked at addressing this challenge.
This paper takes a different approach by leveraging a combination of different learning signals to improve document-level relation extraction. Specifically, the authors use:
- Distant supervision: Automatically aligning text with existing knowledge bases to generate weakly-labeled training data.
- Self-supervision: Training the model to perform auxiliary tasks, like predicting the next sentence in the document, to learn useful representations.
- Supervised learning: Using a small amount of manually-annotated data to fine-tune the model.
By combining these different types of supervision, the model can capture various aspects of the task and achieve better performance than using any single approach in isolation. The authors show that this "efficient multi-supervision" technique outperforms state-of-the-art models on several benchmark datasets for document-level relation extraction.
Technical Explanation
The authors propose a multi-supervision framework for document-level relation extraction that combines distant supervision, self-supervision, and supervised learning. The key components of their approach are:
-
Distant Supervision: The model is first pre-trained on a large corpus of text using distant supervision, where entity pairs with known relations in a knowledge base are automatically aligned with the text to generate weakly-labeled training data.
-
Self-Supervision: The pre-trained model is then fine-tuned using self-supervised objectives, such as predicting the next sentence in the document, to learn useful representations for the downstream task.
-
Supervised Fine-Tuning: Finally, the model is further fine-tuned on a small amount of manually-annotated data using a supervised learning objective for document-level relation extraction.
The authors evaluate their approach on several benchmark datasets, including DocRED, and show that it outperforms state-of-the-art models like Mix-Experts: A mixture-of-experts language model for robust named entity recognition and Fusion Makes Perfection: Efficient Multi-Grained Matching for Document-level Relation Extraction.
The key insight is that by combining different learning signals, the model can capture more aspects of the task and achieve better generalization. The distant supervision provides broad coverage of relation types, the self-supervision helps learn useful representations, and the supervised fine-tuning enables the model to adapt to the specific dataset and task.
Critical Analysis
The authors have presented a compelling approach to document-level relation extraction that leverages efficient multi-supervision. However, there are a few potential limitations and areas for further research:
-
Generalization to other datasets: While the method shows strong performance on the evaluated benchmarks, it would be important to test its generalization to a wider range of datasets and domains to ensure the robustness of the approach.
-
Interpretability and explainability: As with many modern deep learning models, the multi-supervision approach can be seen as a "black box," making it difficult to understand the specific mechanisms by which it arrives at its predictions. Incorporating more interpretability could be a valuable direction for future work.
-
Computational efficiency: The multi-supervision framework involves several pre-training and fine-tuning steps, which could be computationally expensive, particularly for large-scale real-world applications. Exploring ways to improve the efficiency of the method would be an important area for further research.
-
Handling ambiguous and conflicting relations: The paper does not explicitly address the challenge of dealing with ambiguous or conflicting relations within a document, which can be a common issue in real-world data. Developing robust techniques to handle such cases could enhance the practical applicability of the approach.
Overall, the authors have presented a well-designed and promising approach to document-level relation extraction. By carefully combining different learning signals, they have demonstrated significant improvements over the state of the art. With further research to address the potential limitations, this work could have important implications for a wide range of natural language processing applications.
Conclusion
This paper introduces an efficient multi-supervision framework for document-level relation extraction that combines distant supervision, self-supervision, and supervised learning. The authors show that this approach outperforms state-of-the-art models on several benchmark datasets, highlighting the value of leveraging diverse learning signals to capture the complexities of real-world texts.
The work has important implications for advancing the field of relation extraction, which is a crucial task for building knowledge-rich applications like information retrieval, question answering, and knowledge base construction. By extending relation extraction to the document level, this research enables the extraction of more comprehensive and contextual knowledge from unstructured text, paving the way for more powerful and versatile natural language processing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Distantly-Supervised Joint Extraction with Noise-Robust Learning
Yufei Li, Xiao Yu, Yanghong Guo, Yanchi Liu, Haifeng Chen, Cong Liu
0
0
Joint entity and relation extraction is a process that identifies entity pairs and their relations using a single model. We focus on the problem of joint extraction in distantly-labeled data, whose labels are generated by aligning entity mentions with the corresponding entity and relation tags using a knowledge base (KB). One key challenge is the presence of noisy labels arising from both incorrect entity and relation annotations, which significantly impairs the quality of supervised learning. Existing approaches, either considering only one source of noise or making decisions using external knowledge, cannot well-utilize significant information in the training data. We propose DENRL, a generalizable framework that 1) incorporates a lightweight transformer backbone into a sequence labeling scheme for joint tagging, and 2) employs a noise-robust framework that regularizes the tagging model with significant relation patterns and entity-relation dependencies, then iteratively self-adapts to instances with less noise from both sources. Surprisingly, experiments on two benchmark datasets show that DENRL, using merely its own parametric distribution and simple data-driven heuristics, outperforms large language model-based baselines by a large margin with better interpretability.
5/28/2024
⛏️
Document-Level In-Context Few-Shot Relation Extraction via Pre-Trained Language Models
Yilmazcan Ozyurt, Stefan Feuerriegel, Ce Zhang
0
0
Document-level relation extraction aims at inferring structured human knowledge from textual documents. State-of-the-art methods for this task use pre-trained language models (LMs) via fine-tuning, yet fine-tuning is computationally expensive and cannot adapt to new relation types or new LMs. As a remedy, we leverage the generalization capabilities of pre-trained LMs and present a novel framework for document-level in-context few-shot relation extraction. Our framework has three strengths: it eliminates the need (1) for named entity recognition and (2) for human annotations of documents, and (3) it can be updated to new LMs without re-training. We evaluate our framework using DocRED, the largest publicly available dataset for document-level relation extraction, and demonstrate that our framework achieves state-of-the-art performance. We further show that our framework actually performs much better than the original labels from the development set of DocRED. Finally, we demonstrate that our complete framework yields consistent performance gains across diverse datasets and across different pre-trained LMs. To the best of our knowledge, we are the first to reformulate the document-level relation extraction task as a tailored in-context few-shot learning paradigm.
5/24/2024
💬
Mix of Experts Language Model for Named Entity Recognition
Xinwei Chen, Kun Li, Tianyou Song, Jiangjian Guo
0
0
Named Entity Recognition (NER) is an essential steppingstone in the field of natural language processing. Although promising performance has been achieved by various distantly supervised models, we argue that distant supervision inevitably introduces incomplete and noisy annotations, which may mislead the model training process. To address this issue, we propose a robust NER model named BOND-MoE based on Mixture of Experts (MoE). Instead of relying on a single model for NER prediction, multiple models are trained and ensembled under the Expectation-Maximization (EM) framework, so that noisy supervision can be dramatically alleviated. In addition, we introduce a fair assignment module to balance the document-model assignment process. Extensive experiments on real-world datasets show that the proposed method achieves state-of-the-art performance compared with other distantly supervised NER.
5/1/2024

TTM-RE: Memory-Augmented Document-Level Relation Extraction
Chufan Gao, Xuan Wang, Jimeng Sun
0
0
Document-level relation extraction aims to categorize the association between any two entities within a document. We find that previous methods for document-level relation extraction are ineffective in exploiting the full potential of large amounts of training data with varied noise levels. For example, in the ReDocRED benchmark dataset, state-of-the-art methods trained on the large-scale, lower-quality, distantly supervised training data generally do not perform better than those trained solely on the smaller, high-quality, human-annotated training data. To unlock the full potential of large-scale noisy training data for document-level relation extraction, we propose TTM-RE, a novel approach that integrates a trainable memory module, known as the Token Turing Machine, with a noisy-robust loss function that accounts for the positive-unlabeled setting. Extensive experiments on ReDocRED, a benchmark dataset for document-level relation extraction, reveal that TTM-RE achieves state-of-the-art performance (with an absolute F1 score improvement of over 3%). Ablation studies further illustrate the superiority of TTM-RE in other domains (the ChemDisGene dataset in the biomedical domain) and under highly unlabeled settings.
6/11/2024