Distantly-Supervised Joint Extraction with Noise-Robust Learning
2310.04994
0
0
⛏️
Abstract
Joint entity and relation extraction is a process that identifies entity pairs and their relations using a single model. We focus on the problem of joint extraction in distantly-labeled data, whose labels are generated by aligning entity mentions with the corresponding entity and relation tags using a knowledge base (KB). One key challenge is the presence of noisy labels arising from both incorrect entity and relation annotations, which significantly impairs the quality of supervised learning. Existing approaches, either considering only one source of noise or making decisions using external knowledge, cannot well-utilize significant information in the training data. We propose DENRL, a generalizable framework that 1) incorporates a lightweight transformer backbone into a sequence labeling scheme for joint tagging, and 2) employs a noise-robust framework that regularizes the tagging model with significant relation patterns and entity-relation dependencies, then iteratively self-adapts to instances with less noise from both sources. Surprisingly, experiments on two benchmark datasets show that DENRL, using merely its own parametric distribution and simple data-driven heuristics, outperforms large language model-based baselines by a large margin with better interpretability.
Create account to get full access
Overview
- Joint entity and relation extraction identifies entity pairs and their relationships using a single model
- This paper focuses on joint extraction in distantly-labeled data, where labels are generated by aligning mentions with knowledge base tags
- A key challenge is the presence of noisy labels from incorrect entity and relation annotations, which degrades supervised learning
Plain English Explanation
The paper discusses joint entity and relation extraction, which is the process of identifying pairs of entities and the relationships between them using a single machine learning model. The researchers focus on a specific type of data called "distantly-labeled data," where the labels (the information about the entities and their relationships) are generated automatically by matching the text with a knowledge base, rather than being manually labeled by humans.
One of the main problems with this type of data is that the labels can be noisy or inaccurate, containing errors in both the identification of the entities and the relationships between them. This noise can significantly degrade the performance of the machine learning model that is trained on this data.
Existing approaches have tried to address this issue, either by only considering one source of noise (either in the entities or the relationships) or by using external knowledge to help the model make decisions. However, these methods don't fully utilize the valuable information that is present in the training data itself.
The researchers propose a new framework called DENRL that aims to address these limitations. DENRL has two key elements:
-
It uses a lightweight transformer-based neural network architecture for the joint extraction task, which allows it to effectively process the input text.
-
It employs a "noise-robust" training approach that uses the patterns and dependencies in the data itself to regularize the model, helping it to adapt to instances with less noise from both the entity and relation annotations.
Surprisingly, the researchers found that DENRL, using just its own internal mechanisms and simple data-driven heuristics, outperformed large language model-based baseline methods by a significant margin, while also providing better interpretability of its decisions.
Technical Explanation
The DENRL framework consists of a lightweight transformer backbone that is used for joint sequence labeling of entities and relations. The key innovation is in the noise-robust training process:
-
The model is regularized by incorporating significant relation patterns and entity-relation dependencies, which help it learn to be more robust to noisy labels.
-
The model then iteratively self-adapts, identifying instances with less noise from both entity and relation annotations, and focusing more on these higher-quality examples during training.
The researchers evaluated DENRL on two benchmark datasets for joint entity and relation extraction. Surprisingly, they found that DENRL, using only its own parametric distribution and simple data-driven heuristics, outperformed large language model-based baselines by a significant margin. This suggests that DENRL is able to effectively leverage the valuable information present in the distantly-labeled training data, despite the noise, through its noise-robust training approach.
Critical Analysis
The paper presents a novel and promising approach to the problem of joint entity and relation extraction from distantly-labeled data. The key strengths are the use of a lightweight transformer backbone, the noise-robust training framework, and the ability to outperform larger language model-based baselines.
However, the paper does not fully address the potential limitations of the DENRL approach. For example, it is unclear how DENRL would perform on datasets with more severe label noise or a different distribution of entity and relation types. Additionally, the paper does not explore the scalability of the approach to larger datasets or more complex relation types.
It would also be valuable to see a more in-depth analysis of the interpretability and explainability of DENRL's decisions, as this is cited as an advantage over the baseline methods. Providing concrete examples or case studies of how DENRL's behavior can be better understood would strengthen the claims about its interpretability.
Overall, the DENRL framework represents an interesting and promising step forward in the field of joint entity and relation extraction. Further research is needed to fully understand its limitations, potential use cases, and broader applicability.
Conclusion
This paper presents DENRL, a novel framework for joint entity and relation extraction from distantly-labeled data. DENRL combines a lightweight transformer-based architecture with a noise-robust training approach to effectively leverage the valuable information present in the training data, despite the presence of noisy labels.
The key innovations of DENRL are its ability to regularize the tagging model using relation patterns and entity-relation dependencies, and its iterative self-adaptation to focus on instances with less noise. Surprisingly, DENRL outperforms large language model-based baselines, while also providing better interpretability of its decisions.
The DENRL framework represents an important step forward in addressing the challenges of joint entity and relation extraction, particularly in the context of distantly-labeled data. Further research is needed to fully understand its limitations and potential applications, but the results presented in this paper suggest that DENRL is a promising approach that warrants further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
New!Augmenting Document-level Relation Extraction with Efficient Multi-Supervision
Xiangyu Lin, Weijia Jia, Zhiguo Gong
0
0
Despite its popularity in sentence-level relation extraction, distantly supervised data is rarely utilized by existing work in document-level relation extraction due to its noisy nature and low information density. Among its current applications, distantly supervised data is mostly used as a whole for pertaining, which is of low time efficiency. To fill in the gap of efficient and robust utilization of distantly supervised training data, we propose Efficient Multi-Supervision for document-level relation extraction, in which we first select a subset of informative documents from the massive dataset by combining distant supervision with expert supervision, then train the model with Multi-Supervision Ranking Loss that integrates the knowledge from multiple sources of supervision to alleviate the effects of noise. The experiments demonstrate the effectiveness of our method in improving the model performance with higher time efficiency than existing baselines.
7/2/2024
⛏️
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
Yao Wang, Xin Liu, Weikun Kong, Hai-Tao Yu, Teeradaj Racharak, Kyoung-Sook Kim, Minh Le Nguyen
0
0
Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
5/15/2024
💬
Mix of Experts Language Model for Named Entity Recognition
Xinwei Chen, Kun Li, Tianyou Song, Jiangjian Guo
0
0
Named Entity Recognition (NER) is an essential steppingstone in the field of natural language processing. Although promising performance has been achieved by various distantly supervised models, we argue that distant supervision inevitably introduces incomplete and noisy annotations, which may mislead the model training process. To address this issue, we propose a robust NER model named BOND-MoE based on Mixture of Experts (MoE). Instead of relying on a single model for NER prediction, multiple models are trained and ensembled under the Expectation-Maximization (EM) framework, so that noisy supervision can be dramatically alleviated. In addition, we introduce a fair assignment module to balance the document-model assignment process. Extensive experiments on real-world datasets show that the proposed method achieves state-of-the-art performance compared with other distantly supervised NER.
5/1/2024
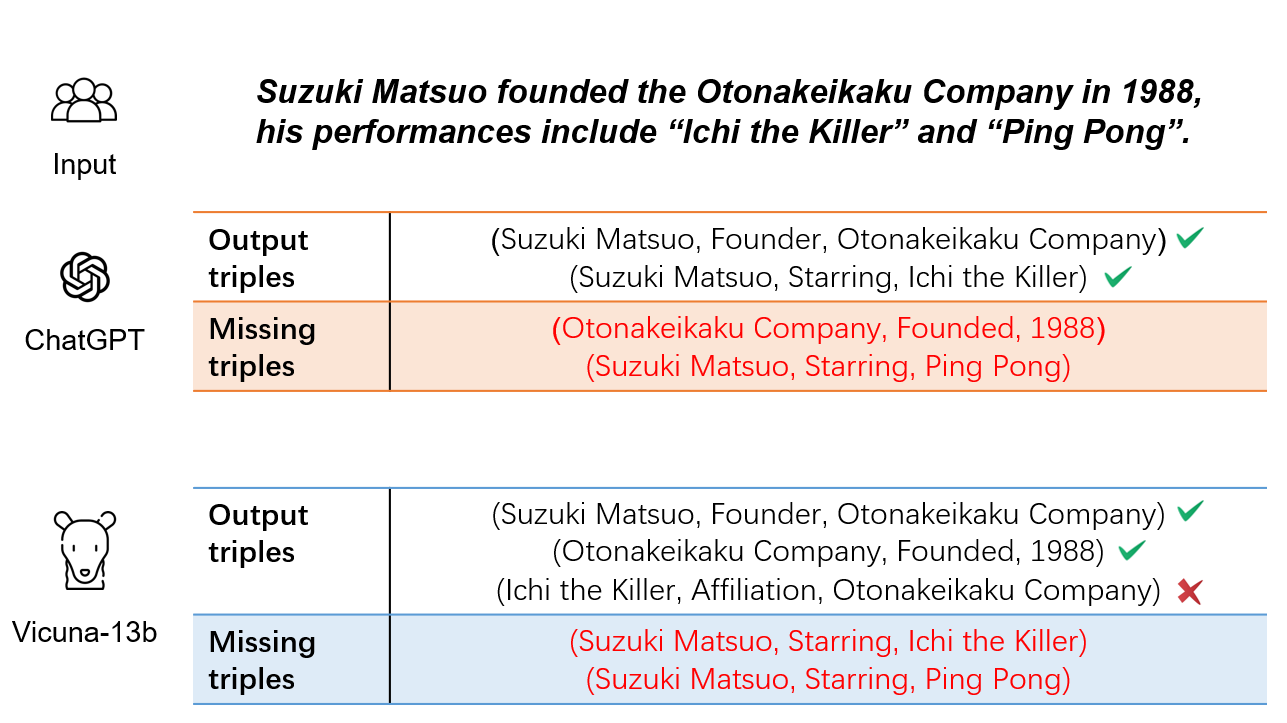
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
0
0
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
4/16/2024