Mix of Experts Language Model for Named Entity Recognition
2404.19192
0
0
💬
Abstract
Named Entity Recognition (NER) is an essential steppingstone in the field of natural language processing. Although promising performance has been achieved by various distantly supervised models, we argue that distant supervision inevitably introduces incomplete and noisy annotations, which may mislead the model training process. To address this issue, we propose a robust NER model named BOND-MoE based on Mixture of Experts (MoE). Instead of relying on a single model for NER prediction, multiple models are trained and ensembled under the Expectation-Maximization (EM) framework, so that noisy supervision can be dramatically alleviated. In addition, we introduce a fair assignment module to balance the document-model assignment process. Extensive experiments on real-world datasets show that the proposed method achieves state-of-the-art performance compared with other distantly supervised NER.
Create account to get full access
Overview
- Named Entity Recognition (NER) is a crucial step in natural language processing (NLP)
- Existing distantly supervised NER models can suffer from incomplete and noisy annotations, which can negatively impact model training
- To address this issue, the researchers propose a robust NER model called BOND-MoE, which uses a Mixture of Experts (MoE) approach
Plain English Explanation
The paper discusses a challenge in the field of natural language processing called Named Entity Recognition (NER). NER is the task of identifying and classifying important things like people, places, and organizations in text. Many NER models are trained using "distant supervision," which means they are trained on data that has been automatically labeled, rather than manually labeled by humans. While this approach can be effective, it can also introduce errors and inconsistencies in the training data, which can then mislead the model during training.
To address this problem, the researchers propose a new NER model called BOND-MoE. Instead of relying on a single NER model, BOND-MoE uses a "Mixture of Experts" (MoE) approach, where multiple NER models are trained and combined together. This helps to compensate for the noisy and incomplete training data that can come from distant supervision. Additionally, the researchers introduce a "fair assignment" module to help balance how the training data is assigned to the different expert models.
The researchers test their BOND-MoE approach on real-world datasets and find that it achieves state-of-the-art performance compared to other distantly supervised NER models. This suggests that their approach is an effective way to address the limitations of distant supervision in NER tasks.
Technical Explanation
The key insight behind BOND-MoE is that instead of relying on a single NER model, the researchers train multiple NER models (called "experts") and then ensemble them together using the Expectation-Maximization (EM) framework. This helps to mitigate the impact of noisy and incomplete annotations that can result from distant supervision.
In addition, the researchers introduce a "fair assignment" module that balances how the training data is assigned to the different expert models. This helps to ensure that each expert model is trained on a diverse and representative subset of the data, rather than having certain experts specialize in only certain types of entities.
The BOND-MoE model is evaluated on several real-world NER datasets, and the results show that it outperforms other state-of-the-art distantly supervised NER approaches. This suggests that the MoE-based ensemble approach and the fair assignment module are effective at handling the noise and incompleteness inherent in distantly supervised training data.
Critical Analysis
The researchers acknowledge that their BOND-MoE approach relies on the assumption that the different expert models will be able to learn complementary representations of the entities in the training data. If this assumption does not hold, and the expert models end up learning very similar representations, then the benefits of the ensemble approach may be limited.
Additionally, the fair assignment module introduced in the paper is a heuristic-based approach, and the researchers do not provide a theoretical analysis of its optimality or convergence properties. It would be interesting to see if there are more principled ways to balance the assignment of training data to the expert models.
Finally, the experiments in the paper are conducted on a relatively small set of NER datasets, and it would be valuable to see how the BOND-MoE approach performs on a wider range of NER tasks and datasets, including multilingual and multimodal scenarios.
Conclusion
The BOND-MoE model proposed in this paper represents an interesting approach to addressing the challenges of distant supervision in named entity recognition tasks. By using a Mixture of Experts ensemble approach and a fair assignment module, the researchers are able to achieve state-of-the-art performance on several real-world NER datasets.
While the paper has some limitations, the core idea of using an ensemble of NER models to compensate for noisy and incomplete training data is a promising direction for further research in this area. If the approach can be extended to handle a wider range of NER scenarios, it could have significant implications for improving the robustness and reliability of NLP systems in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
0
0
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
4/29/2024

DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Somnath Banerjee, Avik Dutta, Aaditya Agrawal, Rima Hazra, Animesh Mukherjee
0
0
With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
6/21/2024
Few-shot Name Entity Recognition on StackOverflow
Xinwei Chen, Kun Li, Tianyou Song, Jiangjian Guo
0
0
StackOverflow, with its vast question repository and limited labeled examples, raise an annotation challenge for us. We address this gap by proposing RoBERTa+MAML, a few-shot named entity recognition (NER) method leveraging meta-learning. Our approach, evaluated on the StackOverflow NER corpus (27 entity types), achieves a 5% F1 score improvement over the baseline. We improved the results further domain-specific phrase processing enhance results.
4/30/2024
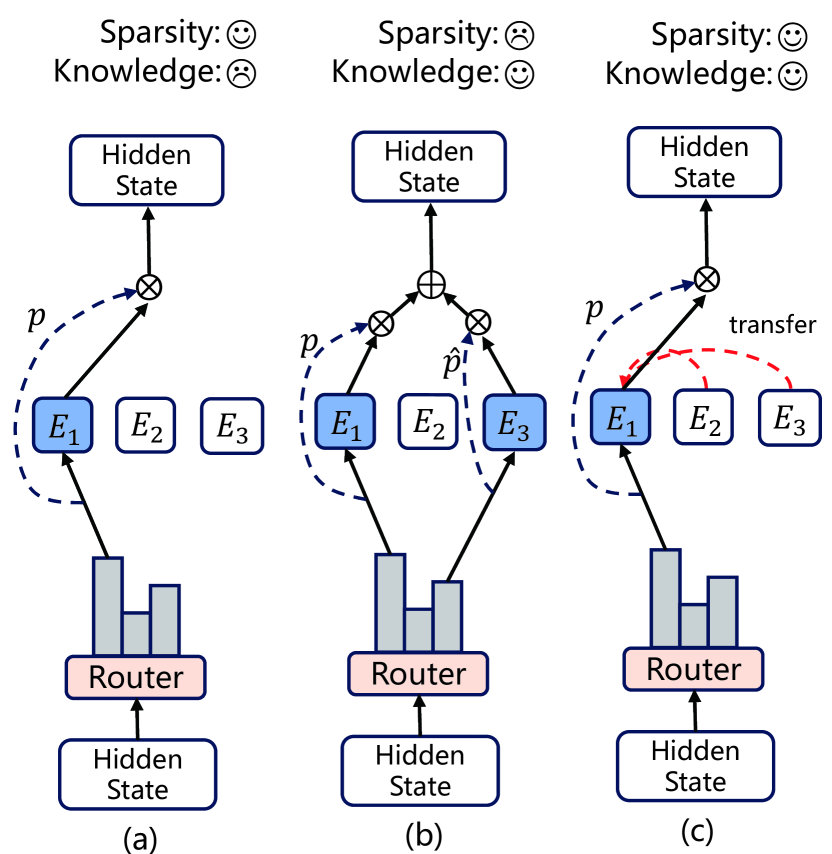
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024