Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
2404.01334
0
0
Abstract
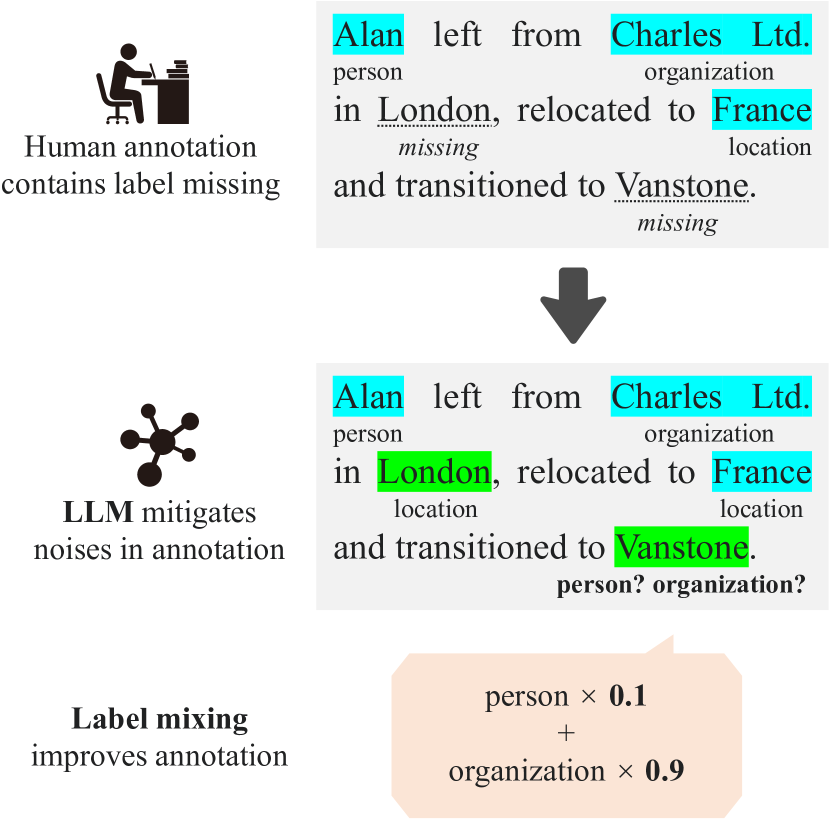
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
Create account to get full access
Overview
- Researchers propose a method to automatically and accurately annotate named entities in text using large language models (LLMs).
- Existing named entity recognition (NER) datasets often have quality issues due to manual annotation, which is time-consuming and prone to errors.
- The proposed approach leverages the capabilities of LLMs to generate high-quality annotations, potentially improving the reliability of NER datasets.
Plain English Explanation
Accurately identifying important names, places, organizations, and other entities in text is a crucial task for many language processing applications. However, creating high-quality datasets for training these systems, known as named entity recognition (NER), is challenging. Typically, this involves having human annotators manually label the entities in sample texts, which can be tedious and error-prone.
The researchers in this paper propose a new approach to improve the quality of NER datasets. Instead of relying solely on human annotators, they use powerful language models, which are AI systems trained on massive amounts of text data. These models have shown remarkable abilities to understand and generate human-like language.
The key idea is to use these large language models to automatically annotate entities in text, rather than having humans do it. The researchers hypothesize that the models' deep understanding of language will allow them to identify entities more accurately and consistently than manual annotation. This could lead to NER datasets with fewer errors and biases, ultimately improving the performance of downstream AI systems that rely on this data.
The paper describes experiments demonstrating the effectiveness of this approach, showing that the automated annotations from language models can match or even exceed the quality of human-created labels. This suggests a promising path forward for streamlining the creation of high-quality NER datasets to advance natural language processing capabilities.
Technical Explanation
The paper presents a method for augmenting existing named entity recognition (NER) datasets using large language models (LLMs). NER is the task of identifying and classifying named entities (such as people, organizations, and locations) in text, and reliable NER datasets are crucial for training accurate NER models.
However, the authors note that manually annotating NER datasets can be time-consuming and prone to errors and biases. To address this, they propose leveraging the powerful language understanding capabilities of LLMs to automatically generate entity annotations. Specifically, they use the GPT-3 language model to annotate entities in existing NER datasets, and then evaluate the quality of the automatically generated annotations compared to human-created labels.
The researchers conduct experiments on several standard NER datasets, including CoNLL-2003 and OntoNotes 5.0. They find that the automatically generated annotations from GPT-3 achieve comparable or even superior performance to human annotations, as measured by standard NER evaluation metrics like F1 score.
Furthermore, the authors analyze the types of errors made by the human annotators versus the language model, finding that the model is better able to capture nuanced entity boundaries and resolve ambiguities. They also demonstrate how the automatically annotated data can be used to fine-tune NER models, leading to improved performance compared to models trained solely on the original human-annotated datasets.
Critical Analysis
The proposed approach of using LLMs for automating NER dataset annotation is a promising direction that could help address the quality challenges of manual annotation. The authors provide compelling evidence that the language model-generated annotations can match or exceed human performance, which is an encouraging result.
However, the paper does not fully explore potential limitations or caveats of the approach. For instance, the experiments are conducted on a limited set of datasets, and it's unclear how the method would scale to more diverse or domain-specific text. Additionally, the paper does not delve into potential biases or systematic errors that the language model may introduce, which could be an important consideration for real-world applications.
Further research could investigate the robustness of the approach across a wider range of datasets and genres, as well as explore ways to combine human and machine-generated annotations to further improve the reliability of NER datasets. Investigating the interpretability and transparency of the language model's annotation decisions could also be a valuable direction, as this could help build trust and accountability in the automated annotation process.
Conclusion
This paper presents a novel approach to augmenting named entity recognition (NER) datasets using the capabilities of large language models (LLMs). By leveraging the deep language understanding of models like GPT-3, the researchers demonstrate that it is possible to automatically generate high-quality entity annotations that can match or even exceed the performance of manual human labeling.
This work has the potential to significantly streamline the creation of reliable NER datasets, which are essential for developing accurate and robust natural language processing systems. By reducing the reliance on time-consuming and error-prone manual annotation, the proposed method could pave the way for more efficient and scalable dataset curation, ultimately advancing the state of the art in named entity recognition and related language understanding tasks.
While the paper provides a solid foundation, further research is needed to fully understand the limitations and potential biases of the automated annotation approach. Nonetheless, this study represents an important step towards more intelligent and automated dataset creation, with promising implications for the broader field of artificial intelligence and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024
💬
LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking
Faren Yan, Peng Yu, Xin Chen
0
0
The use of LLMs for natural language processing has become a popular trend in the past two years, driven by their formidable capacity for context comprehension and learning, which has inspired a wave of research from academics and industry professionals. However, for certain NLP tasks, such as NER, the performance of LLMs still falls short when compared to supervised learning methods. In our research, we developed a NER processing framework called LTNER that incorporates a revolutionary Contextualized Entity Marking Gen Method. By leveraging the cost-effective GPT-3.5 coupled with context learning that does not require additional training, we significantly improved the accuracy of LLMs in handling NER tasks. The F1 score on the CoNLL03 dataset increased from the initial 85.9% to 91.9%, approaching the performance of supervised fine-tuning. This outcome has led to a deeper understanding of the potential of LLMs.
4/9/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024

llmNER: (Zero|Few)-Shot Named Entity Recognition, Exploiting the Power of Large Language Models
Fabi'an Villena, Luis Miranda, Claudio Aracena
0
0
Large language models (LLMs) allow us to generate high-quality human-like text. One interesting task in natural language processing (NLP) is named entity recognition (NER), which seeks to detect mentions of relevant information in documents. This paper presents llmNER, a Python library for implementing zero-shot and few-shot NER with LLMs; by providing an easy-to-use interface, llmNER can compose prompts, query the model, and parse the completion returned by the LLM. Also, the library enables the user to perform prompt engineering efficiently by providing a simple interface to test multiple variables. We validated our software on two NER tasks to show the library's flexibility. llmNER aims to push the boundaries of in-context learning research by removing the barrier of the prompting and parsing steps.
6/10/2024