LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking
2404.05624
0
0
💬
Abstract
The use of LLMs for natural language processing has become a popular trend in the past two years, driven by their formidable capacity for context comprehension and learning, which has inspired a wave of research from academics and industry professionals. However, for certain NLP tasks, such as NER, the performance of LLMs still falls short when compared to supervised learning methods. In our research, we developed a NER processing framework called LTNER that incorporates a revolutionary Contextualized Entity Marking Gen Method. By leveraging the cost-effective GPT-3.5 coupled with context learning that does not require additional training, we significantly improved the accuracy of LLMs in handling NER tasks. The F1 score on the CoNLL03 dataset increased from the initial 85.9% to 91.9%, approaching the performance of supervised fine-tuning. This outcome has led to a deeper understanding of the potential of LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have shown impressive performance in natural language processing (NLP) tasks, but their accuracy on certain tasks, like named entity recognition (NER), still lags behind supervised learning methods.
- Researchers developed a NER framework called LTNER that incorporates a novel Contextualized Entity Marking Gen Method.
- By leveraging the cost-effective GPT-3.5 and a context learning approach that avoids additional training, LTNER significantly improved LLM accuracy on NER tasks, approaching the performance of supervised fine-tuning.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. They've become very popular in the past couple years for all sorts of natural language processing tasks. LLMs are great at picking up on context and learning complex patterns in language.
However, for certain NLP tasks like named entity recognition (NER), LLMs still don't perform as well as traditional supervised learning methods. NER is the process of identifying and classifying key entities (like people, organizations, locations, etc.) within text.
The researchers developed a new NER framework called LTNER that incorporates a new technique called Contextualized Entity Marking Gen Method. By using the GPT-3.5 language model along with this new context learning approach, they were able to significantly boost the accuracy of LLMs on NER tasks.
The F1 score, a common metric for evaluating NER performance, went up from 85.9% to 91.9% on a standard benchmark dataset. This is approaching the level of accuracy seen with supervised fine-tuning, but without requiring the same amount of labeled training data.
This research helps us better understand the limits and potential of LLMs. While they excel at many language tasks, there are still some areas where traditional methods can outperform them. But with the right frameworks and techniques, the capabilities of LLMs can be expanded.
Technical Explanation
The researchers developed a named entity recognition (NER) processing framework called LTNER that incorporates a novel Contextualized Entity Marking Gen Method. This approach leverages the capabilities of the cost-effective GPT-3.5 language model along with a context learning strategy that does not require additional training.
The key innovation of the Contextualized Entity Marking Gen Method is that it learns to annotate entities within the input text in a way that provides useful contextual information to the language model. This allows the model to better understand and extract the named entities, without needing to fine-tune on labeled NER datasets.
Experiments on the CoNLL03 NER benchmark dataset showed that this framework was able to significantly boost the F1 score from the initial 85.9% up to 91.9% - approaching the performance of supervised fine-tuning methods, but without the same data requirements.
The researchers argue that this outcome represents a deeper understanding of the strengths and limitations of large language models. While LLMs excel at many NLP tasks due to their robust context comprehension, there are still specific challenges like NER where additional techniques are required to fully harness their potential.
Critical Analysis
The paper presents a compelling approach for enhancing the performance of LLMs on named entity recognition tasks. The Contextualized Entity Marking Gen Method is an innovative strategy that appears to effectively leverage the language understanding capabilities of models like GPT-3.5 without the need for extensive fine-tuning.
However, the authors acknowledge that their framework still falls short of the best supervised learning methods on NER benchmarks. There may be inherent limitations in how LLMs process and represent entities that prevent them from fully matching the performance of models trained directly on annotated NER data.
Additionally, the paper does not provide a detailed analysis of the types of entities or domains where the LTNER framework excels or struggles. Further research would be needed to understand the broader applicability and generalization of this approach.
It would also be valuable to see comparisons to other recent techniques for improving LLM performance on NER, such as AnnolLM or entity-centric pretraining. This could help contextualize the relative merits and limitations of the LTNER framework.
Overall, this research represents a meaningful step forward in bridging the gap between LLMs and supervised learning for NER. However, there remain open questions and areas for further investigation to fully unlock the potential of large language models for this and other specialized NLP tasks.
Conclusion
This research demonstrates that large language models, while extremely powerful for many natural language processing tasks, still have room for improvement when it comes to named entity recognition. By developing the LTNER framework and the novel Contextualized Entity Marking Gen Method, the researchers were able to significantly boost LLM performance on NER, approaching the level of supervised fine-tuning.
This work provides valuable insights into the strengths and limitations of LLMs, and highlights the importance of continued innovation to adapt these models to specialized NLP challenges. As the field of natural language processing continues to advance, frameworks like LTNER may help unlock new capabilities and expand the practical applications of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
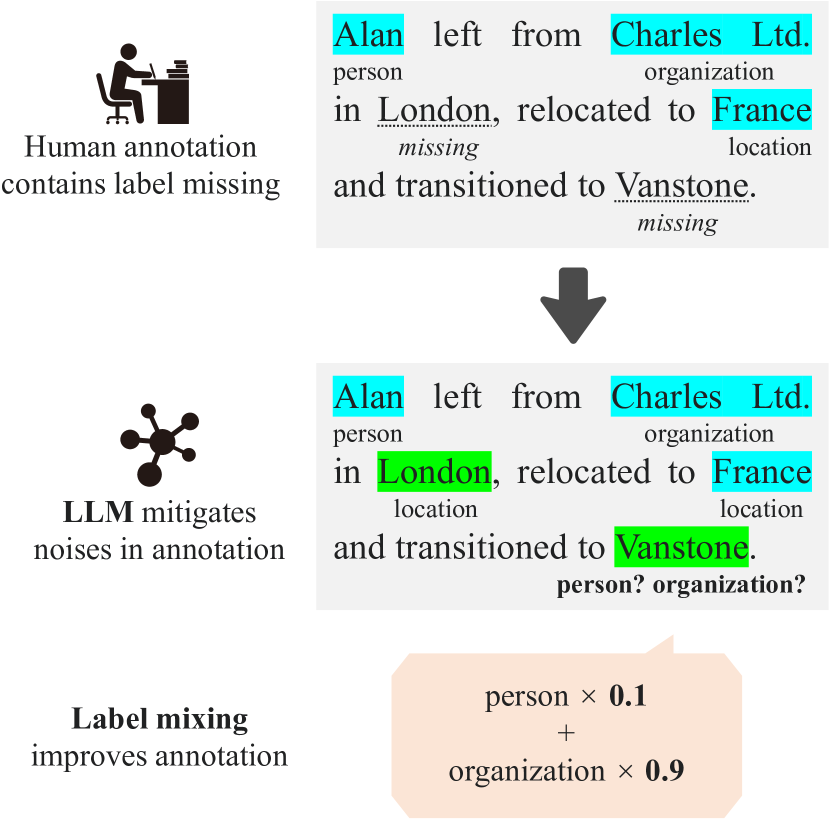
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024
How far is Language Model from 100% Few-shot Named Entity Recognition in Medical Domain
Mingchen Li, Rui Zhang
0
0
Recent advancements in language models (LMs) have led to the emergence of powerful models such as Small LMs (e.g., T5) and Large LMs (e.g., GPT-4). These models have demonstrated exceptional capabilities across a wide range of tasks, such as name entity recognition (NER) in the general domain. (We define SLMs as pre-trained models with fewer parameters compared to models like GPT-3/3.5/4, such as T5, BERT, and others.) Nevertheless, their efficacy in the medical section remains uncertain and the performance of medical NER always needs high accuracy because of the particularity of the field. This paper aims to provide a thorough investigation to compare the performance of LMs in medical few-shot NER and answer How far is LMs from 100% Few-shot NER in Medical Domain, and moreover to explore an effective entity recognizer to help improve the NER performance. Based on our extensive experiments conducted on 16 NER models spanning from 2018 to 2023, our findings clearly indicate that LLMs outperform SLMs in few-shot medical NER tasks, given the presence of suitable examples and appropriate logical frameworks. Despite the overall superiority of LLMs in few-shot medical NER tasks, it is important to note that they still encounter some challenges, such as misidentification, wrong template prediction, etc. Building on previous findings, we introduce a simple and effective method called textsc{RT} (Retrieving and Thinking), which serves as retrievers, finding relevant examples, and as thinkers, employing a step-by-step reasoning process. Experimental results show that our proposed textsc{RT} framework significantly outperforms the strong open baselines on the two open medical benchmark datasets
5/7/2024
VANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Junyi Biana, Weiqi Zhai, Xiaodi Huang, Jiaxuan Zheng, Shanfeng Zhu
0
0
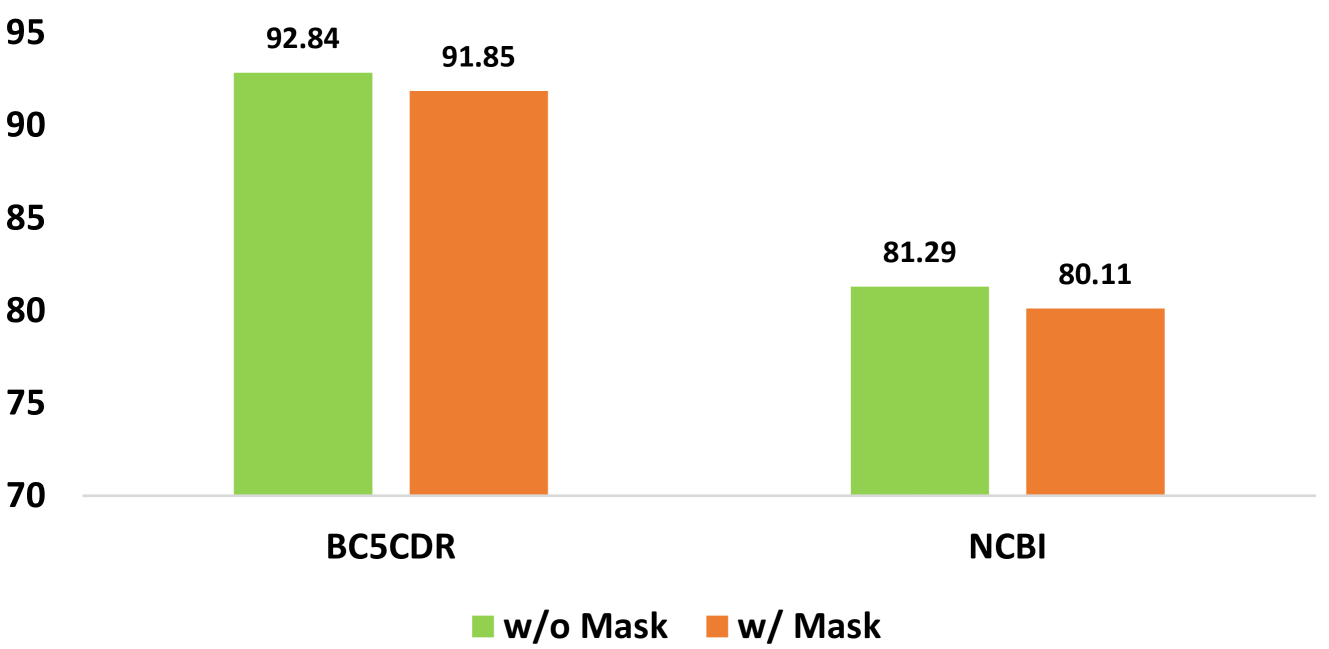
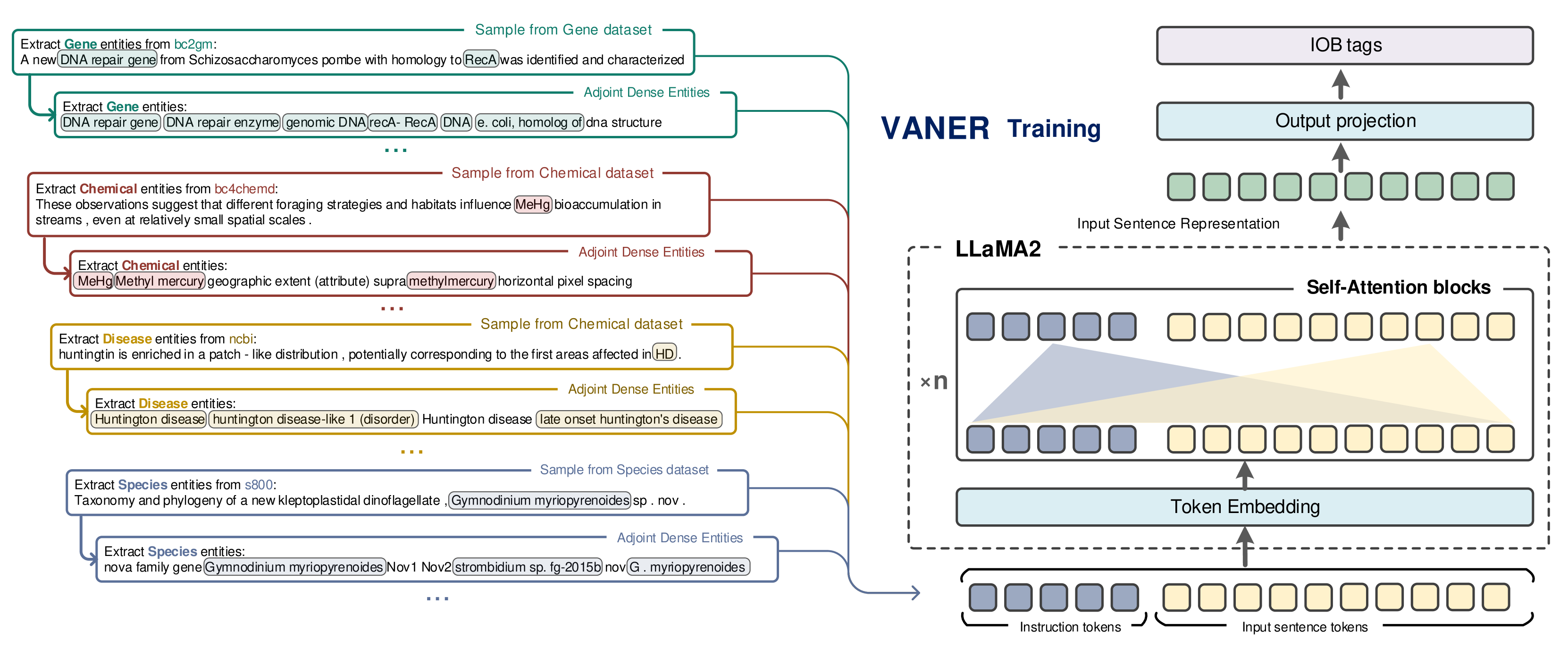
Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
4/30/2024
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024