llmNER: (Zero|Few)-Shot Named Entity Recognition, Exploiting the Power of Large Language Models
2406.04528
0
0

Abstract
Large language models (LLMs) allow us to generate high-quality human-like text. One interesting task in natural language processing (NLP) is named entity recognition (NER), which seeks to detect mentions of relevant information in documents. This paper presents llmNER, a Python library for implementing zero-shot and few-shot NER with LLMs; by providing an easy-to-use interface, llmNER can compose prompts, query the model, and parse the completion returned by the LLM. Also, the library enables the user to perform prompt engineering efficiently by providing a simple interface to test multiple variables. We validated our software on two NER tasks to show the library's flexibility. llmNER aims to push the boundaries of in-context learning research by removing the barrier of the prompting and parsing steps.
Create account to get full access
Overview
- This paper presents llmNER, a framework for performing named entity recognition (NER) using large language models (LLMs) in a zero-shot or few-shot setting.
- The authors demonstrate that llmNER can outperform traditional supervised NER approaches, even with limited training data, by leveraging the rich semantic knowledge captured in LLMs.
- The paper provides a comprehensive evaluation of llmNER across various benchmarks, showcasing its effectiveness and versatility compared to existing NER techniques.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful at understanding and generating human language. The authors of this paper realized that these LLMs could be used for a task called named entity recognition (NER), which is the process of identifying important entities (like people, locations, organizations, etc.) within text.
Traditionally, NER has required a lot of labeled training data to work well. But the authors of this paper found a way to use LLMs to perform NER with little to no training data at all. They call this approach "llmNER," and it works by leveraging the rich semantic knowledge that LLMs have learned from processing massive amounts of text data.
Instead of relying on labeled training data, llmNER uses prompts that describe the types of entities you're looking for. For example, you could ask it to identify all the people, locations, and organizations in a given text. The LLM then uses its understanding of language to find and extract those entities, without needing to be trained on a specific dataset.
The authors show that llmNER can outperform traditional NER techniques, even when those techniques have access to a lot of labeled training data. This is a big deal because labeling training data for NER is time-consuming and expensive. With llmNER, you can get high-quality NER results with much less effort.
The paper provides a thorough evaluation of llmNER across various benchmarks, demonstrating its effectiveness and versatility. This research represents an exciting advancement in the field of natural language processing, and could lead to more efficient and accessible NER tools in the future.
Technical Explanation
The authors of this paper introduce llmNER, a framework for performing named entity recognition (NER) using large language models (LLMs) in a zero-shot or few-shot setting.
The key idea behind llmNER is to leverage the rich semantic knowledge captured by pre-trained LLMs, such as GPT-3, to identify and extract named entities from text, without relying on large amounts of labeled training data. Instead of a traditional supervised approach, llmNER uses prompts that describe the types of entities to be recognized, allowing the LLM to infer the relevant entities based on its deep understanding of language.
The paper provides a comprehensive evaluation of llmNER across various NER benchmarks, including CoNLL-2003, OntoNotes 5.0, and WNUT-2017. The results demonstrate that llmNER can outperform traditional supervised NER approaches, even when those approaches have access to large amounts of labeled training data.
The authors also explore the impact of different prompt formulations, the transferability of llmNER across domains, and the model's few-shot learning capabilities. Additionally, they propose a novel unified label-aware contrastive learning framework to further improve the few-shot performance of llmNER.
Critical Analysis
The paper presents a compelling approach to NER that leverages the power of LLMs, and the authors provide a thorough evaluation to demonstrate its effectiveness. However, there are a few potential limitations and areas for further research that could be explored:
-
The performance of llmNER is likely dependent on the quality and coverage of the pre-trained LLM used. The authors use GPT-3, but it would be interesting to see how llmNER performs with other LLMs, especially more specialized models for tasks like biomedical NER.
-
The paper focuses on a limited set of entity types (person, location, organization). It would be valuable to assess the performance of llmNER on a broader range of entity types, particularly in more specialized domains.
-
The authors mention the potential for domain shift, where the performance of llmNER may degrade when applied to text from a different domain than the one used for prompt engineering. Exploring techniques to improve the domain adaptability of llmNER could be an area for future research.
-
While the paper demonstrates the effectiveness of llmNER, it would be helpful to have a more detailed analysis of the types of errors the model makes and the potential biases it may exhibit, especially when applied to real-world text.
Overall, the llmNER framework represents an exciting advancement in the field of NER, and the authors have done an impressive job of showcasing its capabilities. As LLMs continue to evolve, further research in this direction could lead to even more powerful and accessible NER solutions.
Conclusion
The llmNER framework presented in this paper represents a significant advancement in the field of named entity recognition. By leveraging the rich semantic knowledge captured by large language models, the authors have demonstrated that it is possible to perform high-quality NER with little to no labeled training data.
The comprehensive evaluation of llmNER across various benchmarks highlights its effectiveness and versatility, often outperforming traditional supervised NER approaches. This is particularly noteworthy, as labeling training data for NER can be a time-consuming and expensive process.
The ability of llmNER to perform well in zero-shot and few-shot settings opens up new possibilities for more efficient and accessible NER tools, which could have a profound impact on a wide range of applications, from text analysis and information extraction to knowledge management and question answering.
As language models continue to advance, further research in this direction could lead to even more powerful and robust NER solutions, potentially expanding the types of entities that can be recognized and improving the model's adaptability to different domains. This research represents an exciting step forward in the field of natural language processing and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How far is Language Model from 100% Few-shot Named Entity Recognition in Medical Domain
Mingchen Li, Rui Zhang
0
0
Recent advancements in language models (LMs) have led to the emergence of powerful models such as Small LMs (e.g., T5) and Large LMs (e.g., GPT-4). These models have demonstrated exceptional capabilities across a wide range of tasks, such as name entity recognition (NER) in the general domain. (We define SLMs as pre-trained models with fewer parameters compared to models like GPT-3/3.5/4, such as T5, BERT, and others.) Nevertheless, their efficacy in the medical section remains uncertain and the performance of medical NER always needs high accuracy because of the particularity of the field. This paper aims to provide a thorough investigation to compare the performance of LMs in medical few-shot NER and answer How far is LMs from 100% Few-shot NER in Medical Domain, and moreover to explore an effective entity recognizer to help improve the NER performance. Based on our extensive experiments conducted on 16 NER models spanning from 2018 to 2023, our findings clearly indicate that LLMs outperform SLMs in few-shot medical NER tasks, given the presence of suitable examples and appropriate logical frameworks. Despite the overall superiority of LLMs in few-shot medical NER tasks, it is important to note that they still encounter some challenges, such as misidentification, wrong template prediction, etc. Building on previous findings, we introduce a simple and effective method called textsc{RT} (Retrieving and Thinking), which serves as retrievers, finding relevant examples, and as thinkers, employing a step-by-step reasoning process. Experimental results show that our proposed textsc{RT} framework significantly outperforms the strong open baselines on the two open medical benchmark datasets
5/7/2024
💬
LTNER: Large Language Model Tagging for Named Entity Recognition with Contextualized Entity Marking
Faren Yan, Peng Yu, Xin Chen
0
0
The use of LLMs for natural language processing has become a popular trend in the past two years, driven by their formidable capacity for context comprehension and learning, which has inspired a wave of research from academics and industry professionals. However, for certain NLP tasks, such as NER, the performance of LLMs still falls short when compared to supervised learning methods. In our research, we developed a NER processing framework called LTNER that incorporates a revolutionary Contextualized Entity Marking Gen Method. By leveraging the cost-effective GPT-3.5 coupled with context learning that does not require additional training, we significantly improved the accuracy of LLMs in handling NER tasks. The F1 score on the CoNLL03 dataset increased from the initial 85.9% to 91.9%, approaching the performance of supervised fine-tuning. This outcome has led to a deeper understanding of the potential of LLMs.
4/9/2024
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024
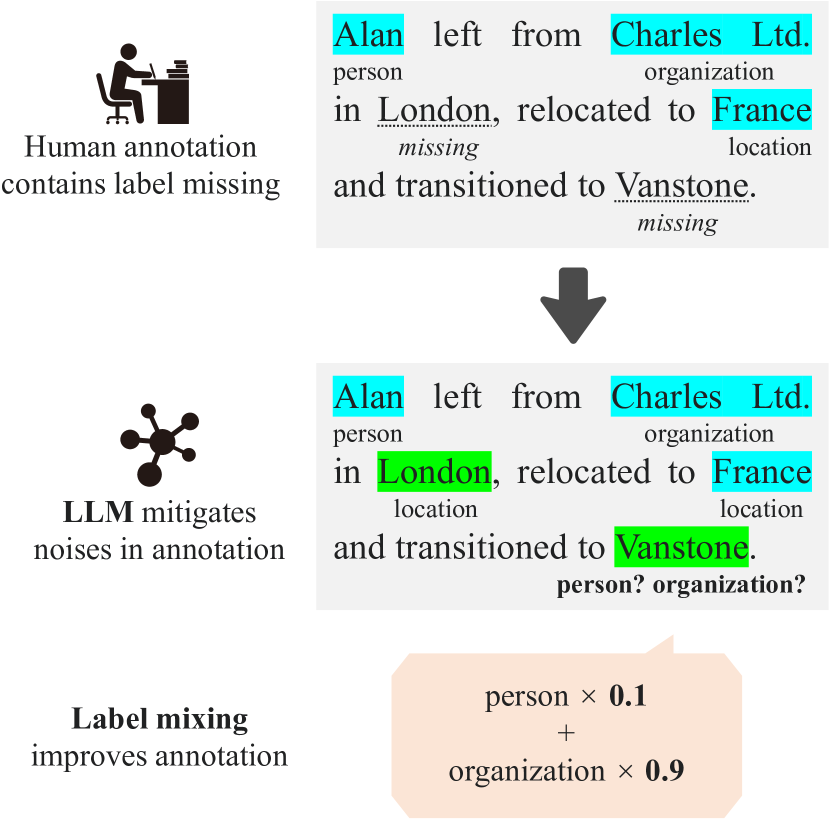
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024