Augmenting Query and Passage for Retrieval-Augmented Generation using LLMs for Open-Domain Question Answering
2406.14277
0
0

Abstract
Retrieval-augmented generation (RAG) has received much attention for Open-domain question-answering (ODQA) tasks as a means to compensate for the parametric knowledge of large language models (LLMs). While previous approaches focused on processing retrieved passages to remove irrelevant context, they still rely heavily on the quality of retrieved passages which can degrade if the question is ambiguous or complex. In this paper, we propose a simple yet efficient method called question and passage augmentation via LLMs for open-domain QA. Our method first decomposes the original questions into multiple-step sub-questions. By augmenting the original question with detailed sub-questions and planning, we are able to make the query more specific on what needs to be retrieved, improving the retrieval performance. In addition, to compensate for the case where the retrieved passages contain distracting information or divided opinions, we augment the retrieved passages with self-generated passages by LLMs to guide the answer extraction. Experimental results show that the proposed scheme outperforms the previous state-of-the-art and achieves significant performance gain over existing RAG methods.
Create account to get full access
Overview
• This paper explores the use of retrieval-augmented generation, a technique that combines large language models (LLMs) with information retrieval, to improve open-domain question answering.
• The researchers propose two key innovations: augmenting the query to better match relevant passages, and jointly optimizing the retrieval and generation components.
• The goal is to leverage the strengths of both retrieval and generation to provide more accurate and informative answers to open-ended questions.
Plain English Explanation
The paper is about a new approach to open-domain question answering, which is the task of answering questions on a wide range of topics using information from the internet or other large data sources. The researchers combine two powerful AI techniques - information retrieval and large language models - to try to improve the quality and usefulness of the answers.
The key ideas are:
-
Enhancing the query: They find ways to modify the original question asked by the user to better match the relevant information in their database. This helps the system understand the question more accurately.
-
Joint optimization: They train the retrieval and generation components of the system together, so they can work in harmony to produce better answers. The retrieval part finds the most relevant information, and the generation part synthesizes that into a coherent response.
By using these techniques, the researchers aim to create an AI system that can answer open-ended questions more reliably and provide users with more complete and informative responses. This could be helpful in many real-world applications, such as search engines, virtual assistants, and educational tools.
Technical Explanation
The paper proposes two key innovations to improve retrieval-augmented generation (RAG) for open-domain question answering:
-
Query Augmentation: The researchers develop a method to dynamically expand the user's original query by identifying the most relevant passages from a large corpus. This helps the system better understand the context and intent behind the question, allowing it to retrieve more pertinent information.
-
Joint Optimization: Instead of training the retrieval and generation components separately, the paper introduces a "DuetRAG" architecture that jointly optimizes the two modules. This enables the system to learn how to best combine retrieval and generation for improved performance on the overall task.
The proposed methods are evaluated on several open-domain QA benchmarks, where they demonstrate improved results compared to previous RAG approaches as well as other state-of-the-art models. The authors also conduct detailed analyses to understand the strengths and limitations of their approach.
Critical Analysis
The paper makes valuable contributions to the field of retrieval-augmented generation for open-domain QA. The proposed query augmentation and joint optimization techniques are well-motivated and show promising empirical results. However, the authors acknowledge several limitations and areas for future work:
- The performance gains, while significant, may still fall short of human-level question answering abilities. Further improvements to the underlying retrieval and generation components are needed.
- The approach relies on a large corpus of text data, which may not be available or practical in all real-world settings. Exploring ways to adapt the system to smaller or more specialized knowledge bases is an important direction.
- The paper does not deeply examine the safety and reliability concerns that can arise when using large language models for open-ended tasks. Addressing these issues will be crucial for deploying such systems in high-stakes applications.
Overall, the research represents a valuable step forward in the quest to build more capable and trustworthy question answering systems. Continued advancements in this area could lead to significant benefits for a wide range of users and applications.
Conclusion
This paper proposes innovative techniques to enhance retrieval-augmented generation for open-domain question answering. By improving the way queries are matched to relevant passages and jointly optimizing the retrieval and generation components, the researchers demonstrate tangible improvements in QA performance.
While the work has limitations and further research is needed, it represents an important contribution to the field of AI-powered question answering. If these methods can be further refined and scaled, they could lead to more reliable and informative virtual assistants, search engines, and educational tools that can better support human users in finding answers to their questions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
New!MKRAG: Medical Knowledge Retrieval Augmented Generation for Medical Question Answering
Yucheng Shi, Shaochen Xu, Tianze Yang, Zhengliang Liu, Tianming Liu, Xiang Li, Ninghao Liu
0
0
Large Language Models (LLMs), although powerful in general domains, often perform poorly on domain-specific tasks like medical question answering (QA). Moreover, they tend to function as black-boxes, making it challenging to modify their behavior. To address the problem, our study delves into retrieval augmented generation (RAG), aiming to improve LLM responses without the need for fine-tuning or retraining. Specifically, we propose a comprehensive retrieval strategy to extract medical facts from an external knowledge base, and then inject them into the query prompt for LLMs. Focusing on medical QA using the MedQA-SMILE dataset, we evaluate the impact of different retrieval models and the number of facts provided to the LLM. Notably, our retrieval-augmented Vicuna-7B model exhibited an accuracy improvement from 44.46% to 48.54%. This work underscores the potential of RAG to enhance LLM performance, offering a practical approach to mitigate the challenges of black-box LLMs.
7/1/2024
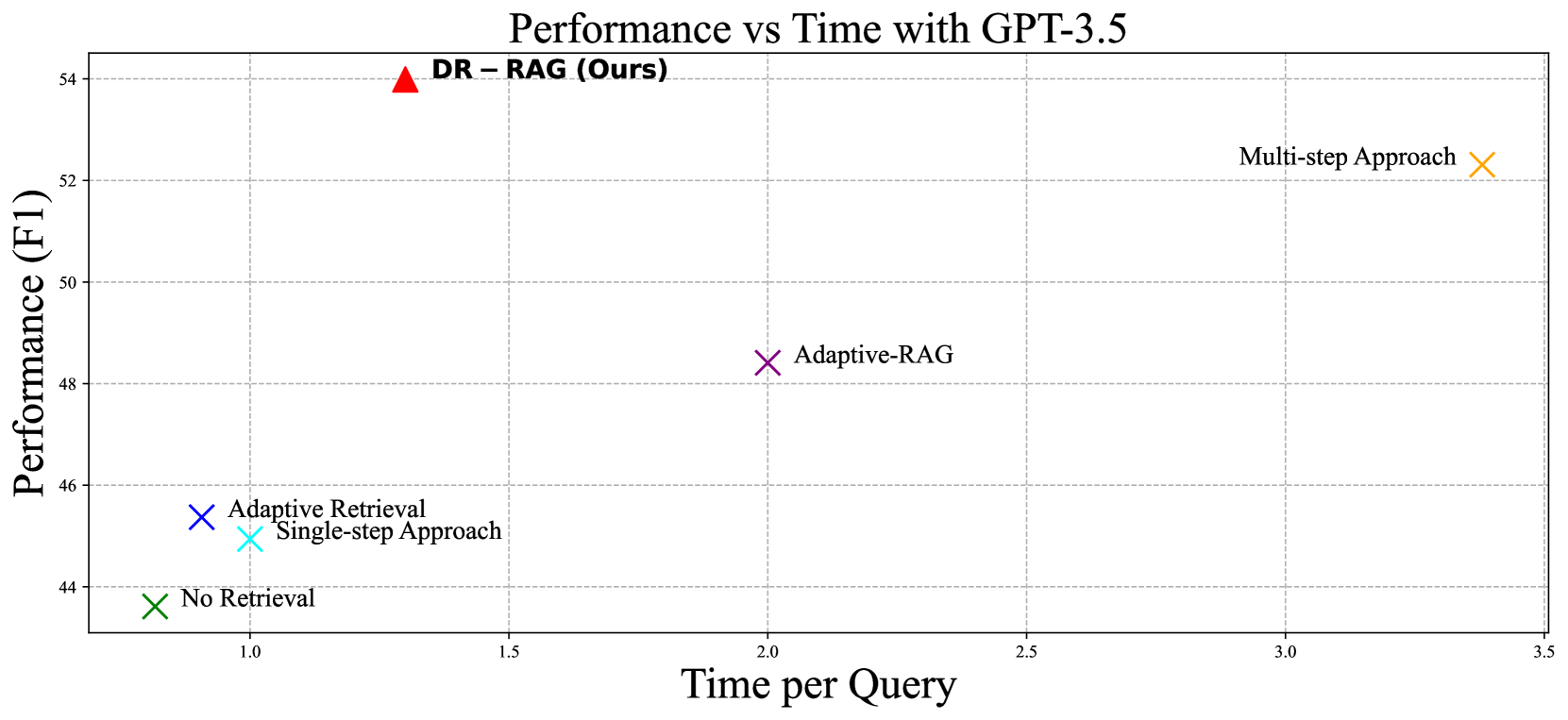
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Zijian Hei, Weiling Liu, Wenjie Ou, Juyi Qiao, Junming Jiao, Guowen Song, Ting Tian, Yi Lin
0
0
Retrieval-Augmented Generation (RAG) has recently demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We have found that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Additionally, a compact classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
6/18/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024
Improving Retrieval for RAG based Question Answering Models on Financial Documents
Spurthi Setty, Katherine Jijo, Eden Chung, Natan Vidra
0
0
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
4/12/2024