Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
2404.00399
0
0
Abstract
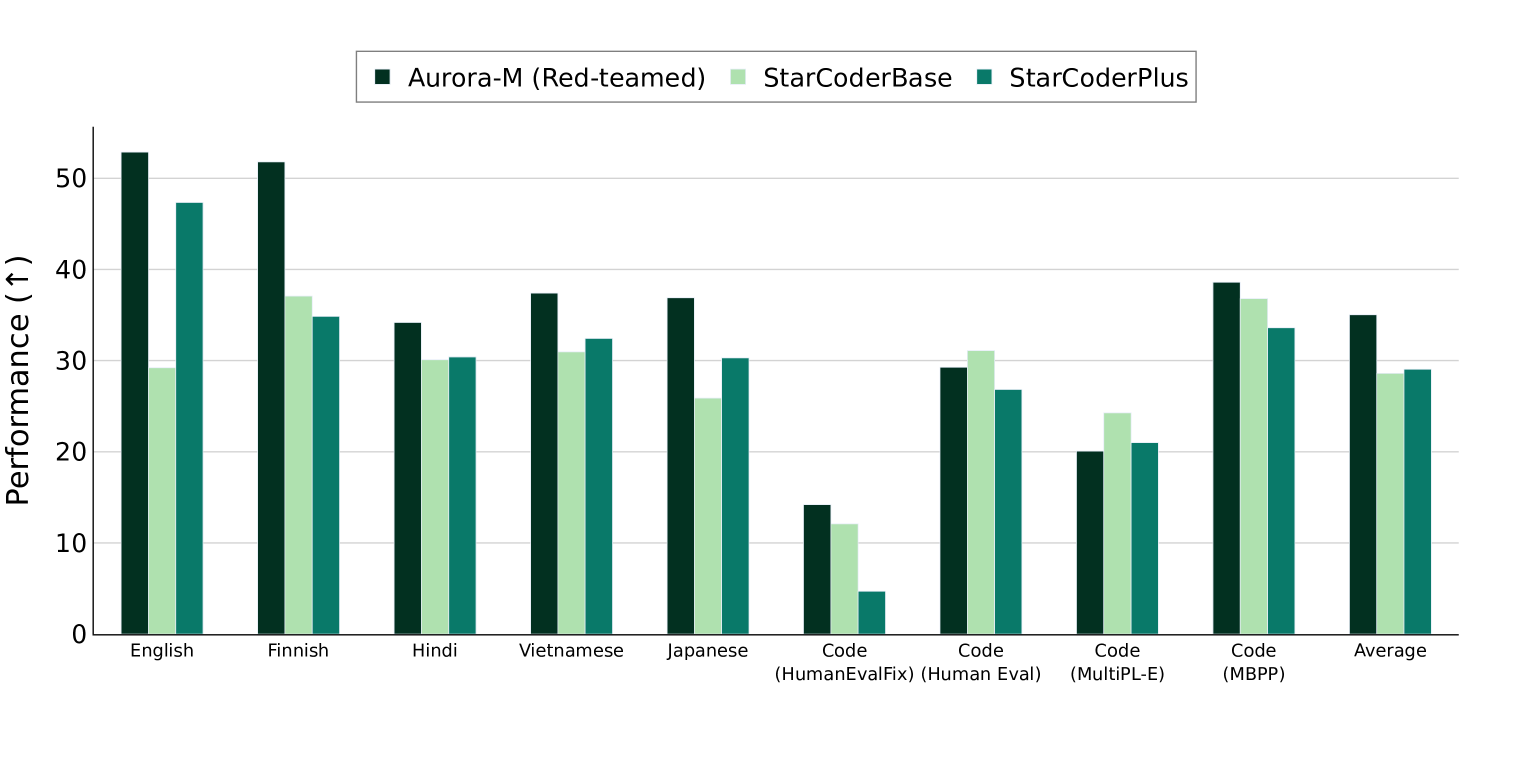
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces "Aurora-M", the first open-source multilingual language model that has been "red-teamed" according to the U.S. Executive Order.
- Red-teaming is a security assessment process where a team tries to find vulnerabilities in a system from an adversarial perspective.
- The researchers curated a diverse dataset and used it to train Aurora-M, a large language model capable of performing well on a variety of multilingual tasks.
- The model was then extensively tested by a red team to identify potential misuses or security issues, as per the Executive Order.
Plain English Explanation
The researchers have developed a new open-source language model called "Aurora-M" that can understand and generate text in multiple languages. This is significant because most existing language models tend to focus on a single language or a limited set of languages.
The key innovation here is that the researchers have put Aurora-M through a rigorous security assessment process called "red-teaming". This means they assembled a team to try and find vulnerabilities or potential misuses of the model, from the perspective of an adversary. This helps ensure the model is as secure and robust as possible before it is released for public use.
To create Aurora-M, the researchers curated a diverse dataset of text from a wide range of sources and used it to train the language model. The resulting model is able to perform well on a variety of multilingual tasks, such as translation, text generation, and question answering.
The red-teaming process involved extensively testing Aurora-M to identify any potential issues or ways it could be misused, as per the requirements of the U.S. Executive Order. This helps ensure the model is safe and can be responsibly deployed in real-world applications.
Technical Explanation
The paper introduces "Aurora-M", a new open-source multilingual language model that has undergone a rigorous security assessment process in accordance with the U.S. Executive Order.
To create Aurora-M, the researchers curated a diverse dataset from a variety of sources, including web pages, books, and social media in over 100 languages. This dataset was used to train a large-scale language model capable of performing well on a range of multilingual tasks.
After training, the model was subjected to a "red-teaming" process, where a dedicated team attempted to identify potential vulnerabilities or misuses of the model from an adversarial perspective. This involved extensive testing and evaluation to ensure the model's robustness and security before its public release.
The red-teaming process was carried out according to the requirements of the U.S. Executive Order, which aims to ensure that large language models are developed and deployed responsibly, with appropriate safeguards against potential misuse.
Critical Analysis
The researchers have taken an important step in developing a multilingual language model and subjecting it to a rigorous security assessment process. This is a valuable approach, as large language models can potentially be misused if not properly evaluated and secured.
However, the paper does not provide detailed information about the specific vulnerabilities or issues identified during the red-teaming process, nor does it discuss how these were addressed. Additionally, the paper does not mention any potential limitations or areas for further research.
While the red-teaming process is a commendable effort, it would be helpful to have more transparency around the methodology and findings to allow the broader research community to better understand the security challenges and best practices for developing secure language models.
Conclusion
The introduction of "Aurora-M", the first open-source multilingual language model that has undergone a security assessment in accordance with the U.S. Executive Order, is a significant step forward in the responsible development of large language models.
By curating a diverse dataset and subjecting the model to extensive red-teaming, the researchers have demonstrated a commitment to creating a secure and robust language model that can be deployed safely. This approach serves as a model for other researchers and developers working on large-scale language models, highlighting the importance of comprehensive security assessments to mitigate potential misuses or vulnerabilities.
While the paper could benefit from more detailed information about the red-teaming process and its findings, the overall effort represents a valuable contribution to the field of natural language processing and the ongoing efforts to ensure the responsible development and use of advanced AI systems.
Related Papers
Poro 34B and the Blessing of Multilinguality
Risto Luukkonen, Jonathan Burdge, Elaine Zosa, Aarne Talman, Ville Komulainen, Vaino Hatanpaa, Peter Sarlin, Sampo Pyysalo
0
0
The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
4/3/2024
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Iker Garc'ia-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata, Andrea Zaninello
0
0
Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
4/12/2024
🐍
Tele-FLM Technical Report
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, Tiejun Huang
0
0
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
4/26/2024
TeenyTinyLlama: open-source tiny language models trained in Brazilian Portuguese
Nicholas Kluge Corr^ea, Sophia Falk, Shiza Fatimah, Aniket Sen, Nythamar de Oliveira
0
0
Large language models (LLMs) have significantly advanced natural language processing, but their progress has yet to be equal across languages. While most LLMs are trained in high-resource languages like English, multilingual models generally underperform monolingual ones. Additionally, aspects of their multilingual foundation sometimes restrict the byproducts they produce, like computational demands and licensing regimes. In this study, we document the development of open-foundation models tailored for use in low-resource settings, their limitations, and their benefits. This is the TeenyTinyLlama pair: two compact models for Brazilian Portuguese text generation. We release them under the permissive Apache 2.0 license on GitHub and Hugging Face for community use and further development. See https://github.com/Nkluge-correa/TeenyTinyLlama
4/10/2024