Poro 34B and the Blessing of Multilinguality
2404.01856
0
0
Abstract
The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces Poro 34B, a large multilingual language model capable of understanding and generating text in over 100 languages.
- The researchers show that by pre-training on a diverse corpus of web data in many languages, Poro 34B can outperform monolingual models on a variety of language tasks, including translation, question-answering, and text generation.
- A key finding is that Poro 34B's multilingual capabilities provide "the blessing of multilinguality" - it can leverage knowledge from one language to benefit performance in another, without requiring separate models for each language.
Plain English Explanation
Poro 34B is a very large artificial intelligence system that can understand and produce text in over 100 different languages. The researchers who created it started by training it on a huge amount of online data across many languages, rather than just focusing on one language.
This multilingual pre-training allows Poro 34B to do a variety of language-related tasks very well, like translating between languages, answering questions, and generating coherent text. The key insight is that by learning from such a diverse set of languages, Poro 34B can leverage knowledge gained in one language to improve its performance in another. This "blessing of multilinguality" means the model doesn't need to be separately trained for each individual language - it can draw on its multilingual understanding to excel at all of them.
Imagine a human polyglot who is fluent in many languages. They can often learn a new language faster by drawing on the patterns and knowledge they've gained from the other languages they know. Poro 34B works in a similar way - its exposure to a wealth of linguistic diversity allows it to become an exceptionally capable language model, without the need to start from scratch for each new language.
Technical Explanation
The key innovation of this work is the development of Poro 34B, a large-scale multilingual language model trained on a diverse corpus of web data in over 100 languages. The researchers used a combination of web crawling, curation, and filtering to assemble a high-quality pretraining dataset spanning a wide range of linguistic diversity.
The Poro 34B model architecture builds on the Transformer paradigm, with modifications to enable effective multilingual learning. This includes techniques like language-specific token embeddings and cross-attention mechanisms that allow the model to reason across languages.
Extensive evaluation on a battery of language tasks demonstrates the power of Poro 34B's multilingual capabilities. It outperforms monolingual models on challenges like machine translation, question answering, and text generation - sometimes by a substantial margin. The researchers attribute this "blessing of multilinguality" to the model's ability to leverage knowledge learned from one language to aid performance in another.
Critical Analysis
The researchers acknowledge several important limitations and caveats of this work. First, the pretraining dataset, while large and diverse, may still underrepresent certain languages and linguistic domains. Additionally, the multilingual capabilities of Poro 34B, while impressive, are not uniformly strong across all language pairs and tasks.
There are also open questions about the interpretability and transparency of such a large, complex multilingual model. Understanding the inner workings and decision-making of Poro 34B remains a challenge, which could limit its trusted deployment in high-stakes applications.
Finally, the environmental and computational costs of training models like Poro 34B are substantial, raising concerns about the sustainability and accessibility of such advanced language technologies. Further research is needed to address these practical constraints.
Conclusion
The Poro 34B model represents an important step forward in multilingual natural language processing, demonstrating the potential for language models to leverage linguistic diversity to become exceptionally capable across a wide range of language-related tasks. By embracing the "blessing of multilinguality," the researchers have created a powerful AI system that can communicate fluently in over 100 languages, opening up new opportunities for cross-cultural exchange, knowledge sharing, and global communication.
While challenges remain, the success of Poro 34B highlights the value of multilingual approaches in AI and suggests that continued progress in this direction could have transformative implications for how humans interact with technology and with each other in our increasingly interconnected world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
LlamaTurk: Adapting Open-Source Generative Large Language Models for Low-Resource Language
Cagri Toraman
0
0
Despite advancements in English-dominant generative large language models, further development is needed for low-resource languages to enhance global accessibility. The primary methods for representing these languages are monolingual and multilingual pretraining. Monolingual pretraining is expensive due to hardware requirements, and multilingual models often have uneven performance across languages. This study explores an alternative solution by adapting large language models, primarily trained on English, to low-resource languages. We assess various strategies, including continual training, instruction fine-tuning, task-specific fine-tuning, and vocabulary extension. The results show that continual training improves language comprehension, as reflected in perplexity scores, and task-specific tuning generally enhances performance of downstream tasks. However, extending the vocabulary shows no substantial benefits. Additionally, while larger models improve task performance with few-shot tuning, multilingual models perform worse than their monolingual counterparts when adapted.
5/14/2024
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Taishi Nakamura, Mayank Mishra, Simone Tedeschi, Yekun Chai, Jason T Stillerman, Felix Friedrich, Prateek Yadav, Tanmay Laud, Vu Minh Chien, Terry Yue Zhuo, Diganta Misra, Ben Bogin, Xuan-Son Vu, Marzena Karpinska, Arnav Varma Dantuluri, Wojciech Kusa, Tommaso Furlanello, Rio Yokota, Niklas Muennighoff, Suhas Pai, Tosin Adewumi, Veronika Laippala, Xiaozhe Yao, Adalberto Junior, Alpay Ariyak, Aleksandr Drozd, Jordan Clive, Kshitij Gupta, Liangyu Chen, Qi Sun, Ken Tsui, Noah Persaud, Nour Fahmy, Tianlong Chen, Mohit Bansal, Nicolo Monti, Tai Dang, Ziyang Luo, Tien-Tung Bui, Roberto Navigli, Virendra Mehta, Matthew Blumberg, Victor May, Huu Nguyen, Sampo Pyysalo
0
0
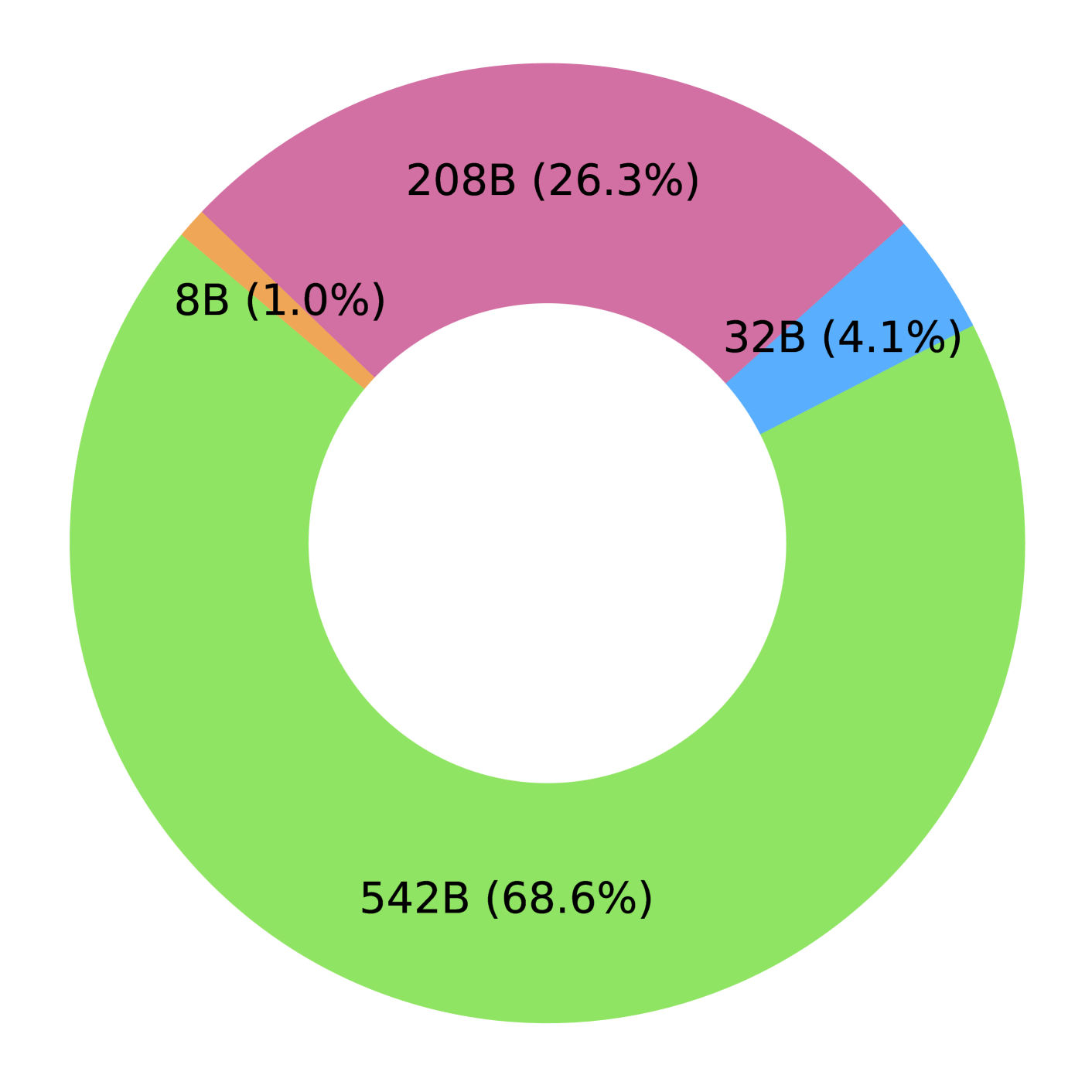
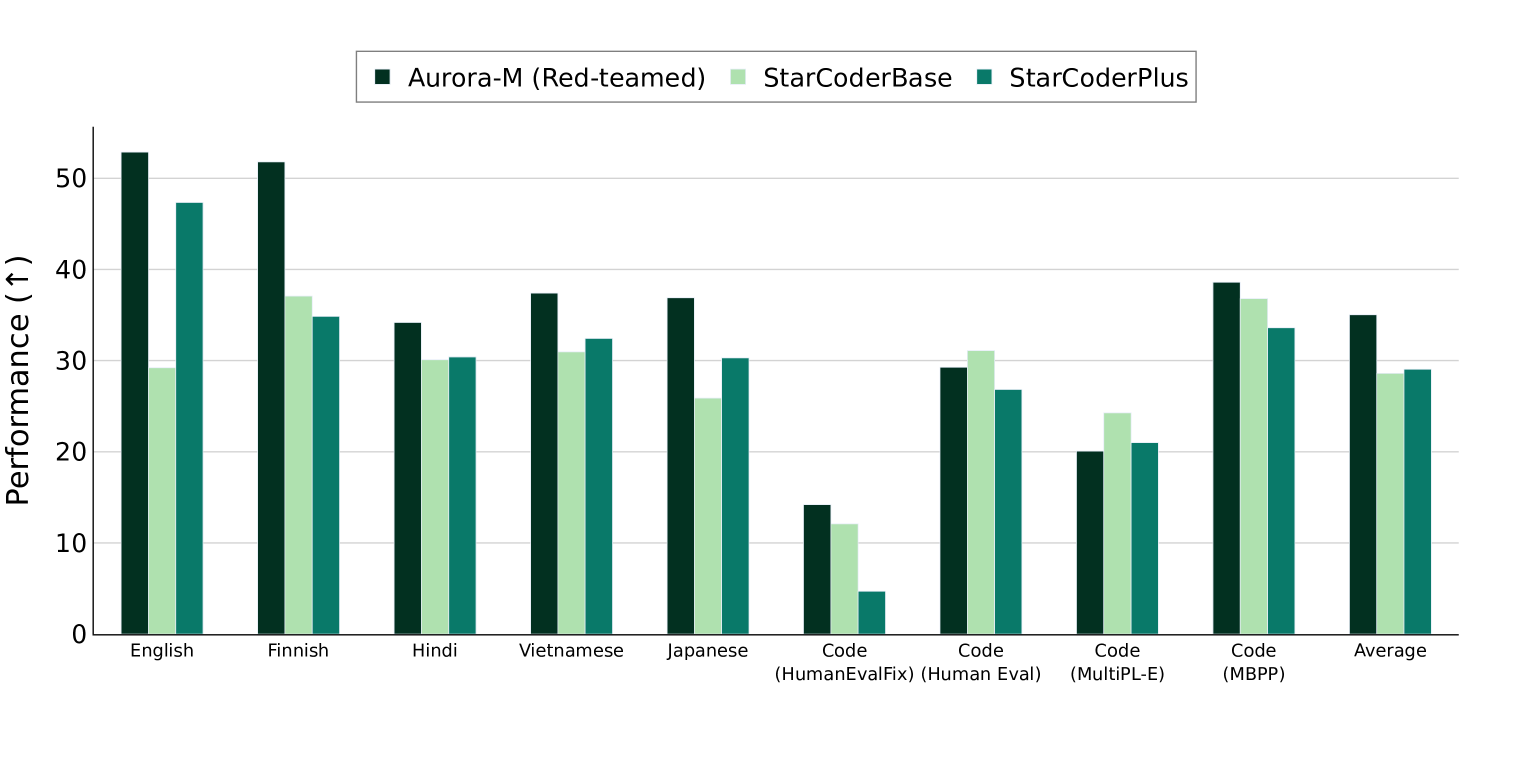
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
4/24/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024