AustroTox: A Dataset for Target-Based Austrian German Offensive Language Detection

0

Sign in to get full access
Overview
- This paper introduces a new dataset called AustroTox for target-based offensive language detection in Austrian German.
- The dataset includes annotations for offensive language and the target of the offense, such as individuals, groups, or institutions.
- The authors benchmark several machine learning models on the dataset and provide insights into the characteristics of offensive language in Austrian German.
Plain English Explanation
The researchers created a new dataset called AustroTox to help identify offensive language in Austrian German text. This dataset includes examples of offensive statements, along with information about what or who the offensive language is targeting, such as a person, a group of people, or an organization.
The researchers then tested various machine learning models on the AustroTox dataset to see how well these models could detect offensive language and recognize the target of the offense. Their findings provide useful insights into the unique characteristics of offensive language used in the Austrian German context.
This research is important because it can help develop better tools for monitoring and addressing online harassment and hate speech, which is a growing concern, especially in multilingual societies like Austria. By creating specialized datasets and models for different language varieties, researchers can build more accurate and culturally-relevant solutions for identifying and mitigating the spread of offensive content.
Technical Explanation
The paper introduces the AustroTox dataset, which was created to enable target-based offensive language detection in Austrian German. The dataset contains 14,000 annotated social media comments, where each comment is labeled for the presence of offensive language and the specific target (e.g., individual, group, institution) of the offense.
The authors benchmark several machine learning models on the AustroTox dataset, including logistic regression, support vector machines, and transformer-based models like BERT. They evaluate the models' performance on offensive language detection and target classification tasks, and provide detailed analyses of the results.
The key findings indicate that transformer-based models like BERT outperform traditional machine learning approaches on both tasks. The authors also observe that certain linguistic features, such as the use of dialectal vocabulary and code-switching, are particularly predictive of offensive language in the Austrian German context.
Critical Analysis
The AustroTox dataset and the authors' benchmarking efforts represent a valuable contribution to the field of offensive language detection, particularly for under-resourced language varieties like Austrian German.
One potential limitation of the study is the reliance on social media comments, which may not fully capture the nuances of offensive language use in other domains, such as news articles or user forums. Additionally, the dataset could be expanded to include a more diverse set of targets beyond individuals, groups, and institutions.
Further research could explore the transferability of models trained on the AustroTox dataset to other German-speaking regions or languages, as well as the interpretability of the models in terms of identifying the specific linguistic cues that lead to offensive language detection.
Conclusion
The AustroTox dataset and the authors' research provide important insights into the detection of offensive language in Austrian German. By creating specialized datasets and benchmarking state-of-the-art models, the researchers have laid the groundwork for more accurate and culturally-relevant tools to address online harassment and hate speech, which is a growing concern in multilingual societies.
This work also highlights the need for continued efforts to develop language-specific and target-aware offensive language detection models, as a one-size-fits-all approach may not be sufficient in capturing the nuances of offensive language use across different contexts and communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AustroTox: A Dataset for Target-Based Austrian German Offensive Language Detection
Pia Pachinger, Janis Goldzycher, Anna Maria Planitzer, Wojciech Kusa, Allan Hanbury, Julia Neidhardt
Model interpretability in toxicity detection greatly profits from token-level annotations. However, currently such annotations are only available in English. We introduce a dataset annotated for offensive language detection sourced from a news forum, notable for its incorporation of the Austrian German dialect, comprising 4,562 user comments. In addition to binary offensiveness classification, we identify spans within each comment constituting vulgar language or representing targets of offensive statements. We evaluate fine-tuned language models as well as large language models in a zero- and few-shot fashion. The results indicate that while fine-tuned models excel in detecting linguistic peculiarities such as vulgar dialect, large language models demonstrate superior performance in detecting offensiveness in AustroTox. We publish the data and code.
Read more6/13/2024
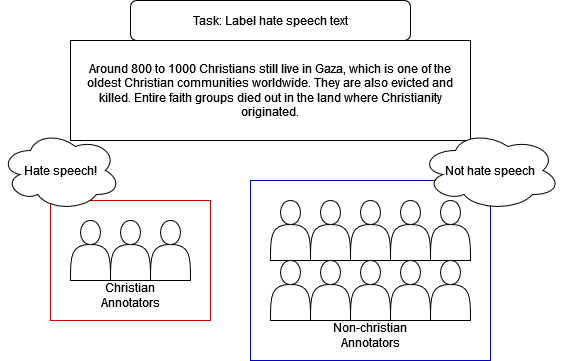
0
IndoToxic2024: A Demographically-Enriched Dataset of Hate Speech and Toxicity Types for Indonesian Language
Lucky Susanto, Musa Izzanardi Wijanarko, Prasetia Anugrah Pratama, Traci Hong, Ika Idris, Alham Fikri Aji, Derry Wijaya
Hate speech poses a significant threat to social harmony. Over the past two years, Indonesia has seen a ten-fold increase in the online hate speech ratio, underscoring the urgent need for effective detection mechanisms. However, progress is hindered by the limited availability of labeled data for Indonesian texts. The condition is even worse for marginalized minorities, such as Shia, LGBTQ, and other ethnic minorities because hate speech is underreported and less understood by detection tools. Furthermore, the lack of accommodation for subjectivity in current datasets compounds this issue. To address this, we introduce IndoToxic2024, a comprehensive Indonesian hate speech and toxicity classification dataset. Comprising 43,692 entries annotated by 19 diverse individuals, the dataset focuses on texts targeting vulnerable groups in Indonesia, specifically during the hottest political event in the country: the presidential election. We establish baselines for seven binary classification tasks, achieving a macro-F1 score of 0.78 with a BERT model (IndoBERTweet) fine-tuned for hate speech classification. Furthermore, we demonstrate how incorporating demographic information can enhance the zero-shot performance of the large language model, gpt-3.5-turbo. However, we also caution that an overemphasis on demographic information can negatively impact the fine-tuned model performance due to data fragmentation.
Read more6/28/2024

0
MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Marta R. Costa-juss`a, Mariano Coria Meglioli, Pierre Andrews, David Dale, Prangthip Hansanti, Elahe Kalbassi, Alex Mourachko, Christophe Ropers, Carleigh Wood
Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
Read more6/28/2024

0
Towards Generalized Offensive Language Identification
Alphaeus Dmonte, Tejas Arya, Tharindu Ranasinghe, Marcos Zampieri
The prevalence of offensive content on the internet, encompassing hate speech and cyberbullying, is a pervasive issue worldwide. Consequently, it has garnered significant attention from the machine learning (ML) and natural language processing (NLP) communities. As a result, numerous systems have been developed to automatically identify potentially harmful content and mitigate its impact. These systems can follow two approaches; (1) Use publicly available models and application endpoints, including prompting large language models (LLMs) (2) Annotate datasets and train ML models on them. However, both approaches lack an understanding of how generalizable they are. Furthermore, the applicability of these systems is often questioned in off-domain and practical environments. This paper empirically evaluates the generalizability of offensive language detection models and datasets across a novel generalized benchmark. We answer three research questions on generalizability. Our findings will be useful in creating robust real-world offensive language detection systems.
Read more7/29/2024