AutoHall: Automated Hallucination Dataset Generation for Large Language Models

0
🛸
Sign in to get full access
Overview
- Large language models (LLMs) have become widely used across many applications due to their powerful language understanding and generation capabilities.
- However, detecting when LLMs generate non-factual or "hallucinatory" content remains a challenge.
- Manual annotation of hallucinations is time-consuming and expensive, making it difficult to build datasets for training hallucination detection models.
Plain English Explanation
The paper addresses the problem of detecting when large language models generate content that is not factual or truthful. These inaccurate outputs, known as "hallucinations," can be difficult to identify, especially at a large scale.
The key idea is to automatically create datasets of hallucinations that can be used to train models to detect this type of content. The researchers developed a method called AutoHall that can generate these datasets by leveraging existing fact-checking datasets. This avoids the need for expensive and time-consuming manual annotation of hallucinations.
The paper also proposes a new hallucination detection method that does not require any training data. Instead, it looks for self-contradictions in the language model's output as a signal of potential hallucinations. This "zero-resource" approach can be applied to any language model, without the need for a dedicated hallucination dataset.
The experiments in the paper show that this new detection method outperforms existing techniques. The results also reveal differences in the types and proportions of hallucinations produced by different language models, which could be valuable insights for model developers and users.
Technical Explanation
The paper presents two main contributions to address the challenge of hallucination detection in large language models (LLMs):
-
AutoHall: A method for automatically constructing model-specific hallucination datasets by leveraging existing fact-checking datasets. This avoids the need for expensive and time-consuming manual annotation of hallucinations.
-
A zero-resource and black-box hallucination detection method based on self-contradiction. This approach does not require any training data and can be applied to any LLM.
The researchers conducted experiments on prevalent open-source and closed-source LLMs, evaluating the performance of their proposed hallucination detection method against existing baselines. Their results show superior hallucination detection performance compared to the baselines.
Additionally, the experiments reveal variations in hallucination proportions and types across different language models, which could provide valuable insights for model developers and users.
Critical Analysis
The paper presents a promising approach to address the challenge of hallucination detection in LLMs. The AutoHall method for automatically generating hallucination datasets is a significant contribution, as it avoids the need for manual annotation, which is both time-consuming and expensive.
The self-contradiction-based hallucination detection method is also noteworthy, as it does not require any training data and can be applied to any LLM. This makes it a versatile and accessible solution for users who may not have the resources to build dedicated hallucination detection models.
However, the paper does not explore the potential limitations or caveats of the proposed methods. For example, it is unclear how the quality and reliability of the automatically generated hallucination datasets may compare to manually curated ones. Additionally, the robustness of the self-contradiction-based detection method under different types of hallucinations or model architectures could be further investigated.
It would also be valuable to see a more in-depth analysis of the detected hallucinations, including the potential underlying causes and their implications for real-world applications of LLMs.
Conclusion
The paper presents two significant contributions to the challenge of hallucination detection in large language models:
-
AutoHall, a method for automatically constructing model-specific hallucination datasets, which addresses the issue of expensive and time-consuming manual annotation.
-
A zero-resource and black-box hallucination detection method based on self-contradiction, which can be applied to any language model without the need for a dedicated hallucination dataset.
The experiments in the paper demonstrate the superior performance of the proposed methods compared to existing baselines, as well as reveal interesting insights about the variations in hallucination proportions and types across different language models.
These findings could have important implications for the development and deployment of large language models, as well as the broader challenge of ensuring the reliability and trustworthiness of AI-generated content. Further research exploring the limitations and real-world applications of these techniques could help advance the field of hallucination detection and contribute to the responsible use of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Zouying Cao, Yifei Yang, Hai Zhao
While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.
Read more7/22/2024
0
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
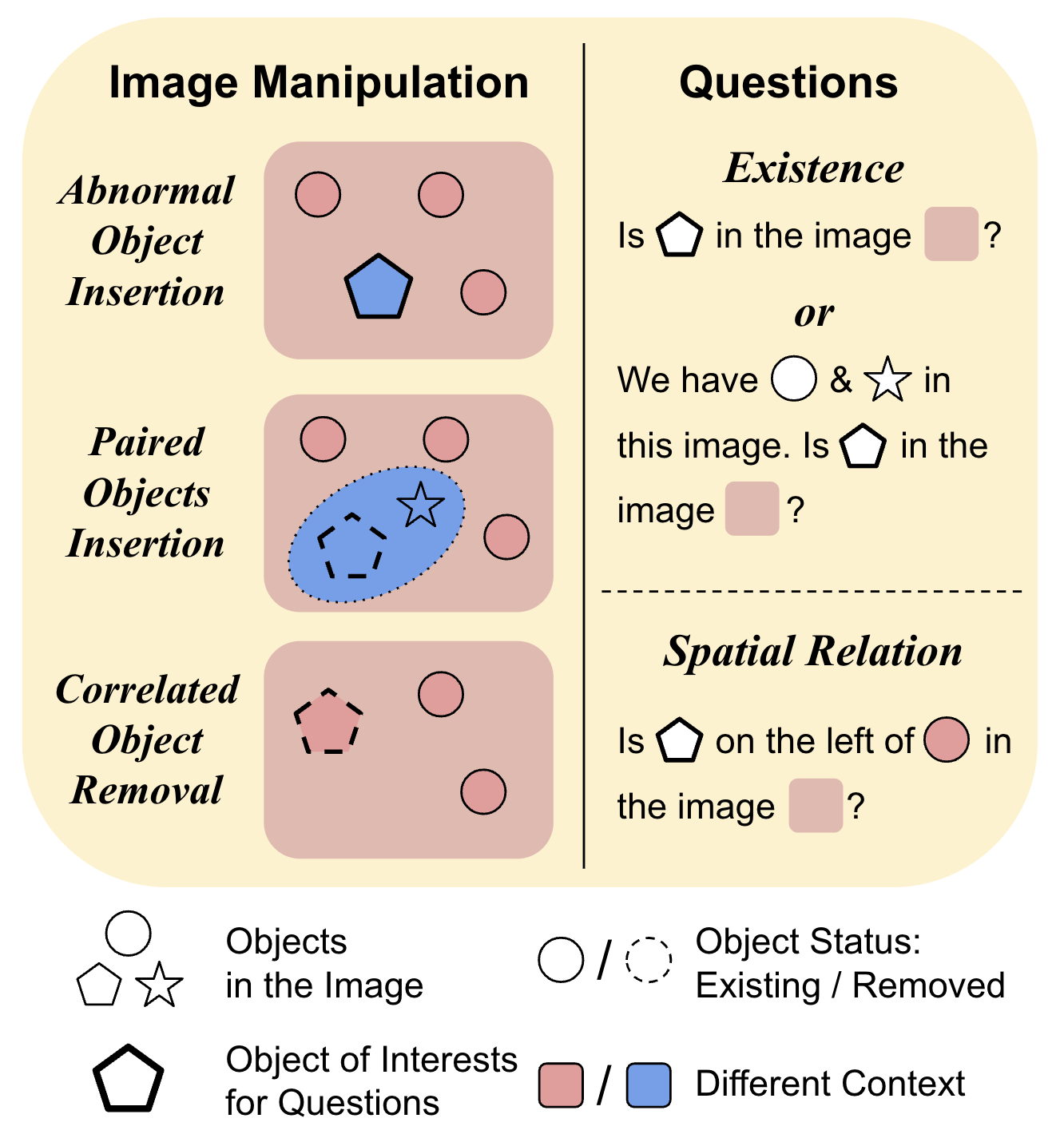
Xiyang Wu, Tianrui Guan, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, Tianyi Zhou, Dinesh Manocha
Large vision-language models (LVLMs) hallucinate: certain context cues in an image may trigger the language module's overconfident and incorrect reasoning on abnormal or hypothetical objects. Though a few benchmarks have been developed to investigate LVLM hallucinations, they mainly rely on hand-crafted corner cases whose fail patterns may hardly generalize, and finetuning on them could undermine their validity. These motivate us to develop the first automatic benchmark generation approach, AUTOHALLUSION, that harnesses a few principal strategies to create diverse hallucination examples. It probes the language modules in LVLMs for context cues and uses them to synthesize images by: (1) adding objects abnormal to the context cues; (2) for two co-occurring objects, keeping one and excluding the other; or (3) removing objects closely tied to the context cues. It then generates image-based questions whose ground-truth answers contradict the language module's prior. A model has to overcome contextual biases and distractions to reach correct answers, while incorrect or inconsistent answers indicate hallucinations. AUTOHALLUSION enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AUTOHALLUSION, paving the way for a long battle against hallucinations.
Read more6/18/2024
0
Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses
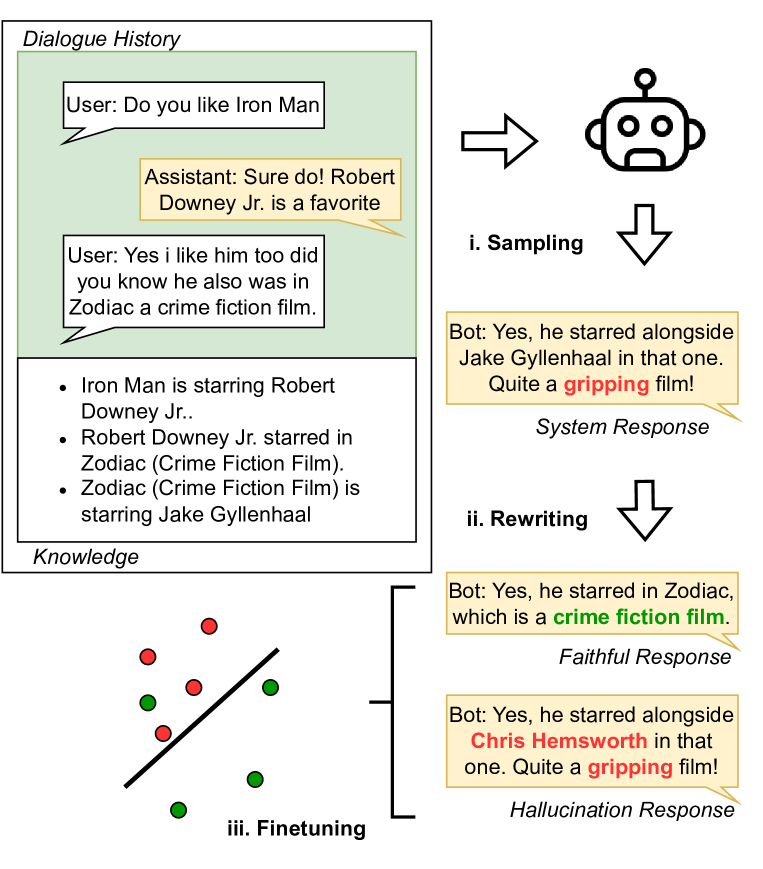
Dongxu Zhang, Varun Gangal, Barrett Martin Lattimer, Yi Yang
Detecting hallucinations in large language model (LLM) outputs is pivotal, yet traditional fine-tuning for this classification task is impeded by the expensive and quickly outdated annotation process, especially across numerous vertical domains and in the face of rapid LLM advancements. In this study, we introduce an approach that automatically generates both faithful and hallucinated outputs by rewriting system responses. Experimental findings demonstrate that a T5-base model, fine-tuned on our generated dataset, surpasses state-of-the-art zero-shot detectors and existing synthetic generation methods in both accuracy and latency, indicating efficacy of our approach.
Read more7/9/2024

0
Unsupervised Real-Time Hallucination Detection based on the Internal States of Large Language Models
Weihang Su, Changyue Wang, Qingyao Ai, Yiran HU, Zhijing Wu, Yujia Zhou, Yiqun Liu
Hallucinations in large language models (LLMs) refer to the phenomenon of LLMs producing responses that are coherent yet factually inaccurate. This issue undermines the effectiveness of LLMs in practical applications, necessitating research into detecting and mitigating hallucinations of LLMs. Previous studies have mainly concentrated on post-processing techniques for hallucination detection, which tend to be computationally intensive and limited in effectiveness due to their separation from the LLM's inference process. To overcome these limitations, we introduce MIND, an unsupervised training framework that leverages the internal states of LLMs for real-time hallucination detection without requiring manual annotations. Additionally, we present HELM, a new benchmark for evaluating hallucination detection across multiple LLMs, featuring diverse LLM outputs and the internal states of LLMs during their inference process. Our experiments demonstrate that MIND outperforms existing state-of-the-art methods in hallucination detection.
Read more6/11/2024