Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses

0
Sign in to get full access
Overview
- This research paper focuses on enhancing the detection of hallucinations, which are outputs from large language models that do not accurately reflect the input data.
- The authors propose a method to generate synthetic data using perturbation-based techniques, which can be used to train models to better identify hallucinations in system responses.
- The work has potential applications in improving the reliability and trustworthiness of language models used in various real-world applications.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become increasingly powerful in generating human-like text. However, these models can sometimes produce outputs that are factually incorrect or do not accurately reflect the input data, a phenomenon known as "hallucination." Detecting Hallucinations in Large Language Model Generation Token and Detecting and Mitigating Hallucination in Large Vision-Language Models have explored this issue in depth.
The authors of this paper propose a novel approach to enhance the detection of hallucinations. They develop a method to generate synthetic data by perturbing existing examples, creating a diverse set of inputs that can be used to train models to better identify hallucinated outputs. This approach is inspired by techniques used in SMURFCAT at SemEval-2024 Task 6: Leveraging Synthetic Data for Enhanced Hallucination Detection and SLPL-Shroom at SemEval2024 Task 06: A Comprehensive Approach to Hallucination Detection.
By training models on this synthetic data, the authors aim to improve their ability to distinguish between reliable and unreliable outputs from language models. This could have significant implications for the real-world deployment of these models, where it is crucial to ensure the trustworthiness and accuracy of the information they provide.
Technical Explanation
The research paper presents a novel approach to enhance the detection of hallucinations in language model outputs. The authors propose a perturbation-based synthetic data generation method to create a diverse set of examples that can be used to train models to better identify hallucinated outputs.
The key steps of the methodology are as follows:
- Data Collection: The authors start with a dataset of human-written text and corresponding system responses.
- Perturbation: They apply various perturbation techniques to the input text, such as word substitution, insertion, and deletion, to generate synthetic examples.
- Hallucination Annotation: The authors manually annotate the synthetic examples as either hallucinated or non-hallucinated, creating a labeled dataset.
- Model Training: Using the labeled synthetic data, the authors train a classification model to distinguish between hallucinated and non-hallucinated system responses.
The authors evaluate their approach on a benchmark dataset and demonstrate that the models trained on the synthetic data outperform those trained on the original dataset alone in terms of hallucination detection performance.
Critical Analysis
The research presented in this paper is a valuable contribution to the ongoing efforts to enhance the reliability and trustworthiness of large language models. The authors' approach of using perturbation-based synthetic data generation to improve hallucination detection is a novel and promising technique.
One potential limitation of the study is the reliance on manual annotation of the synthetic examples, which can be time-consuming and potentially subjective. The authors acknowledge this issue and suggest exploring semi-supervised or unsupervised methods for hallucination annotation as an area for future research, as highlighted in ANAH-V2: Scaling Analytical Hallucination Annotation for Large Language Models.
Additionally, the authors focus primarily on textual inputs and outputs, and it would be interesting to see how their approach could be extended to multimodal settings, where language models are combined with vision models to generate more complex outputs.
Conclusion
This research paper presents a novel approach to enhancing the detection of hallucinations in language model outputs. By leveraging perturbation-based synthetic data generation, the authors demonstrate that models can be trained to more reliably identify unreliable or factually incorrect outputs from large language models.
The potential implications of this work are significant, as the ability to ensure the trustworthiness and accuracy of language model outputs is crucial for their widespread deployment in real-world applications. The authors' contributions pave the way for further advancements in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Hallucination Detection through Perturbation-Based Synthetic Data Generation in System Responses
Dongxu Zhang, Varun Gangal, Barrett Martin Lattimer, Yi Yang
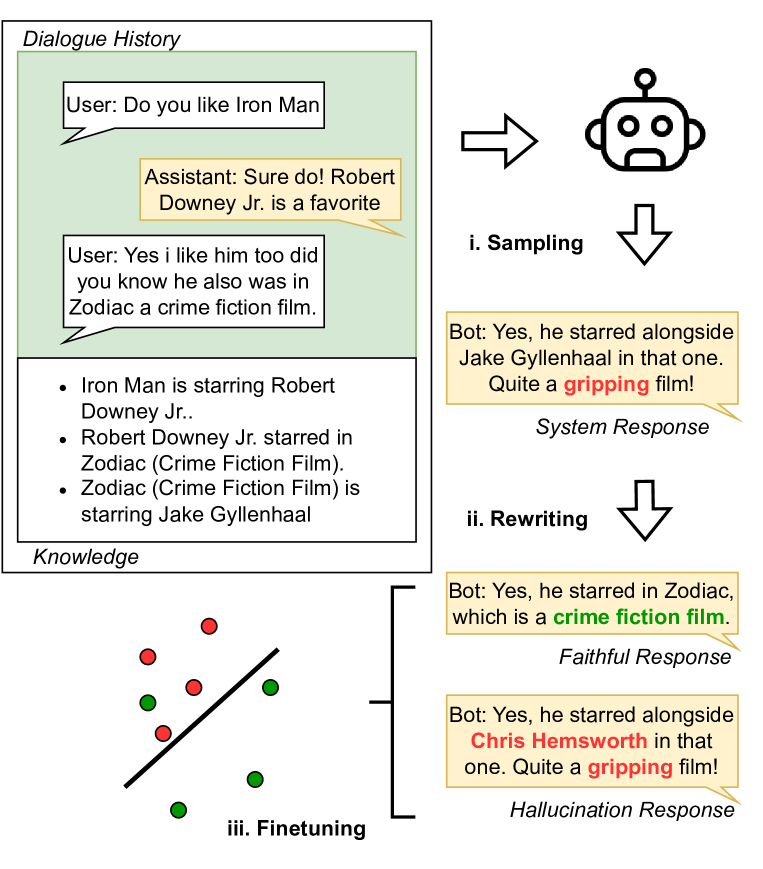
Detecting hallucinations in large language model (LLM) outputs is pivotal, yet traditional fine-tuning for this classification task is impeded by the expensive and quickly outdated annotation process, especially across numerous vertical domains and in the face of rapid LLM advancements. In this study, we introduce an approach that automatically generates both faithful and hallucinated outputs by rewriting system responses. Experimental findings demonstrate that a T5-base model, fine-tuned on our generated dataset, surpasses state-of-the-art zero-shot detectors and existing synthetic generation methods in both accuracy and latency, indicating efficacy of our approach.
Read more7/9/2024
🛸
0
AutoHall: Automated Hallucination Dataset Generation for Large Language Models
Zouying Cao, Yifei Yang, Hai Zhao
While Large language models (LLMs) have garnered widespread applications across various domains due to their powerful language understanding and generation capabilities, the detection of non-factual or hallucinatory content generated by LLMs remains scarce. Currently, one significant challenge in hallucination detection is the laborious task of time-consuming and expensive manual annotation of the hallucinatory generation. To address this issue, this paper first introduces a method for automatically constructing model-specific hallucination datasets based on existing fact-checking datasets called AutoHall. Furthermore, we propose a zero-resource and black-box hallucination detection method based on self-contradiction. We conduct experiments towards prevalent open-/closed-source LLMs, achieving superior hallucination detection performance compared to extant baselines. Moreover, our experiments reveal variations in hallucination proportions and types among different models.
Read more7/22/2024

0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024
0
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
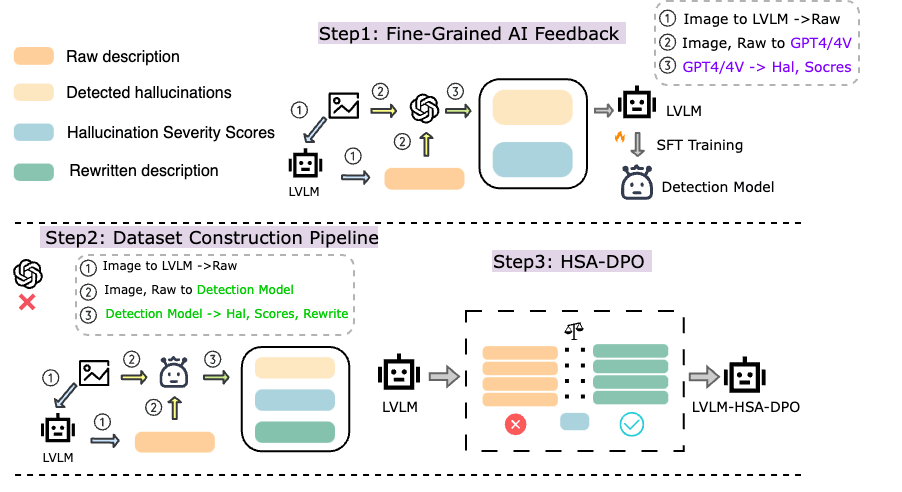
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024