Automated Data Visualization from Natural Language via Large Language Models: An Exploratory Study
2404.17136
0
0
Abstract
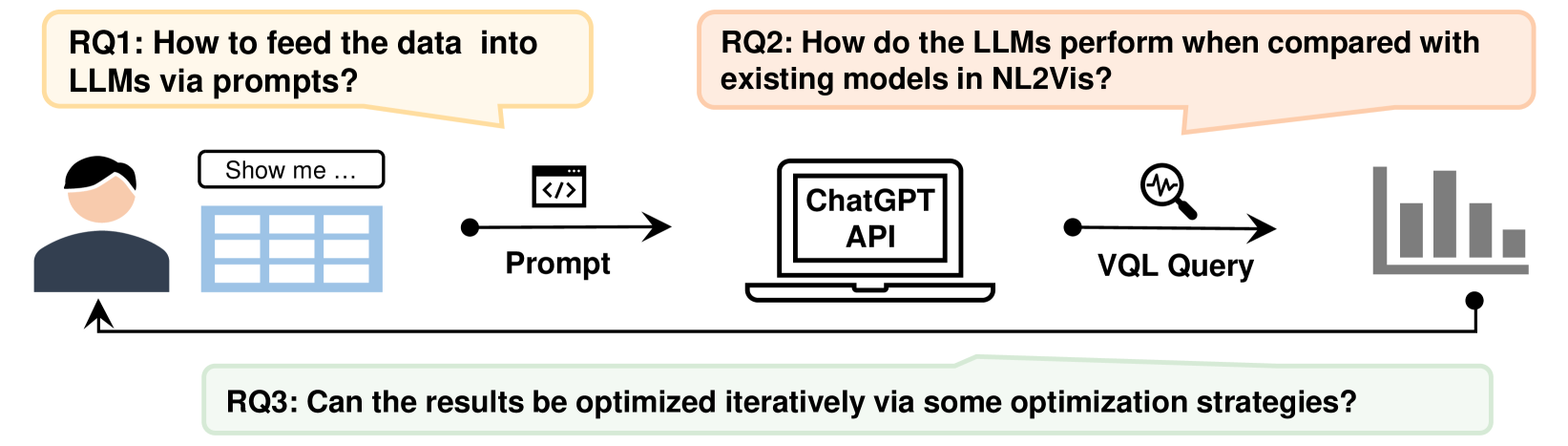
The Natural Language to Visualization (NL2Vis) task aims to transform natural-language descriptions into visual representations for a grounded table, enabling users to gain insights from vast amounts of data. Recently, many deep learning-based approaches have been developed for NL2Vis. Despite the considerable efforts made by these approaches, challenges persist in visualizing data sourced from unseen databases or spanning multiple tables. Taking inspiration from the remarkable generation capabilities of Large Language Models (LLMs), this paper conducts an empirical study to evaluate their potential in generating visualizations, and explore the effectiveness of in-context learning prompts for enhancing this task. In particular, we first explore the ways of transforming structured tabular data into sequential text prompts, as to feed them into LLMs and analyze which table content contributes most to the NL2Vis. Our findings suggest that transforming structured tabular data into programs is effective, and it is essential to consider the table schema when formulating prompts. Furthermore, we evaluate two types of LLMs: finetuned models (e.g., T5-Small) and inference-only models (e.g., GPT-3.5), against state-of-the-art methods, using the NL2Vis benchmarks (i.e., nvBench). The experimental results reveal that LLMs outperform baselines, with inference-only models consistently exhibiting performance improvements, at times even surpassing fine-tuned models when provided with certain few-shot demonstrations through in-context learning. Finally, we analyze when the LLMs fail in NL2Vis, and propose to iteratively update the results using strategies such as chain-of-thought, role-playing, and code-interpreter. The experimental results confirm the efficacy of iterative updates and hold great potential for future study.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the potential of large language models to automatically generate data visualizations from natural language descriptions.
- The researchers investigate the feasibility and performance of this approach, as well as its limitations and areas for further research.
- The study provides insights into the current state of language model-driven data visualization and its future applications.
Plain English Explanation
In this paper, the researchers investigate whether large language models like GPT-3 can be used to automatically generate data visualizations from natural language descriptions. This is an exciting idea because it could make it much easier for people to create visualizations without needing specialized technical skills.
The researchers wanted to see if these powerful language models, which are trained on vast amounts of text data, could understand the meaning and intent behind natural language descriptions of data and then translate that into appropriate visual representations. This could be a game-changer for data analysis and communication, allowing more people to create effective visualizations to explore and share insights.
The study examines the performance and limitations of this approach, providing valuable insights into the current state of the technology and areas for future improvement. For example, the researchers found that the language models were generally able to generate relevant visualizations, but struggled with more complex data and descriptions. There is still work to be done to make this technology more robust and accurate.
Overall, this research represents an important step forward in the quest to make data visualization more accessible and democratized. By leveraging the incredible capabilities of large language models, we may be able to breathe new life into existing visualizations and discover new insights from conversational contexts. This could have profound implications for how we understand and communicate data in the years to come.
Technical Explanation
The researchers in this study explored the feasibility of using large language models, such as GPT-3, to automatically generate data visualizations from natural language descriptions. They trained a series of models on a dataset of natural language prompts and corresponding visualizations, and then evaluated the models' ability to generate appropriate visualizations given new prompts.
The experiment design involved several key components:
- Dataset: The researchers compiled a dataset of natural language prompts and corresponding data visualizations, covering a diverse range of topics and visualization types.
- Model Architecture: They fine-tuned large language models, such as GPT-3, on the dataset to create a custom model capable of generating visualizations from text.
- Evaluation: The researchers tested the model's performance on a held-out set of prompts, assessing the relevance, accuracy, and quality of the generated visualizations.
The results of the study showed that the language models were generally able to generate relevant and appropriate visualizations, but struggled with more complex data and prompts. The researchers identified several areas for improvement, such as enhancing the models' understanding of data semantics and improving their ability to handle more sophisticated visualization types.
The insights from this research suggest that large language models can automatically engineer features and generate synthetic tabular data to support data visualization, opening up new possibilities for democratizing data exploration and communication.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their study. One key limitation is the relatively small size and scope of the dataset used for training and evaluation. Expanding the dataset to include a wider range of data types, visualization styles, and natural language prompts could help improve the models' performance and generalization capabilities.
Additionally, the study focuses primarily on the ability to generate relevant visualizations, but does not extensively evaluate the quality, interpretability, and usefulness of the generated visualizations. Further research could investigate user-centric metrics and user studies to better understand the practical impact and usability of this technology.
Another potential area for improvement is the models' understanding of data semantics and relationships. The researchers note that the language models sometimes struggled with more complex data and prompts, suggesting a need for better integration of data understanding and reasoning capabilities.
Finally, the paper does not address potential biases or ethical considerations that may arise from using large language models for automated data visualization. As these models become more widely deployed, it will be crucial to investigate and mitigate any biases or unintended consequences that could arise from their use in data analysis and communication.
Conclusion
This exploratory study on using large language models for automated data visualization represents an important step forward in democratizing data analysis and communication. By leveraging the remarkable capabilities of these language models, the researchers have demonstrated the potential to breathe new life into existing visualizations and discover new insights from conversational contexts.
While the current results are promising, the research also highlights the need for further advancements in areas such as data understanding, visualization quality, and ethical considerations. As the field of language model-driven data visualization continues to evolve, it will be crucial to address these challenges to unlock the full potential of this technology and make data more accessible and insightful for all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Weixu Zhang, Yifei Wang, Yuanfeng Song, Victor Junqiu Wei, Yuxing Tian, Yiyan Qi, Jonathan H. Chan, Raymond Chi-Wing Wong, Haiqin Yang
0
0
The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
5/14/2024
💬
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
0
0
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
4/9/2024
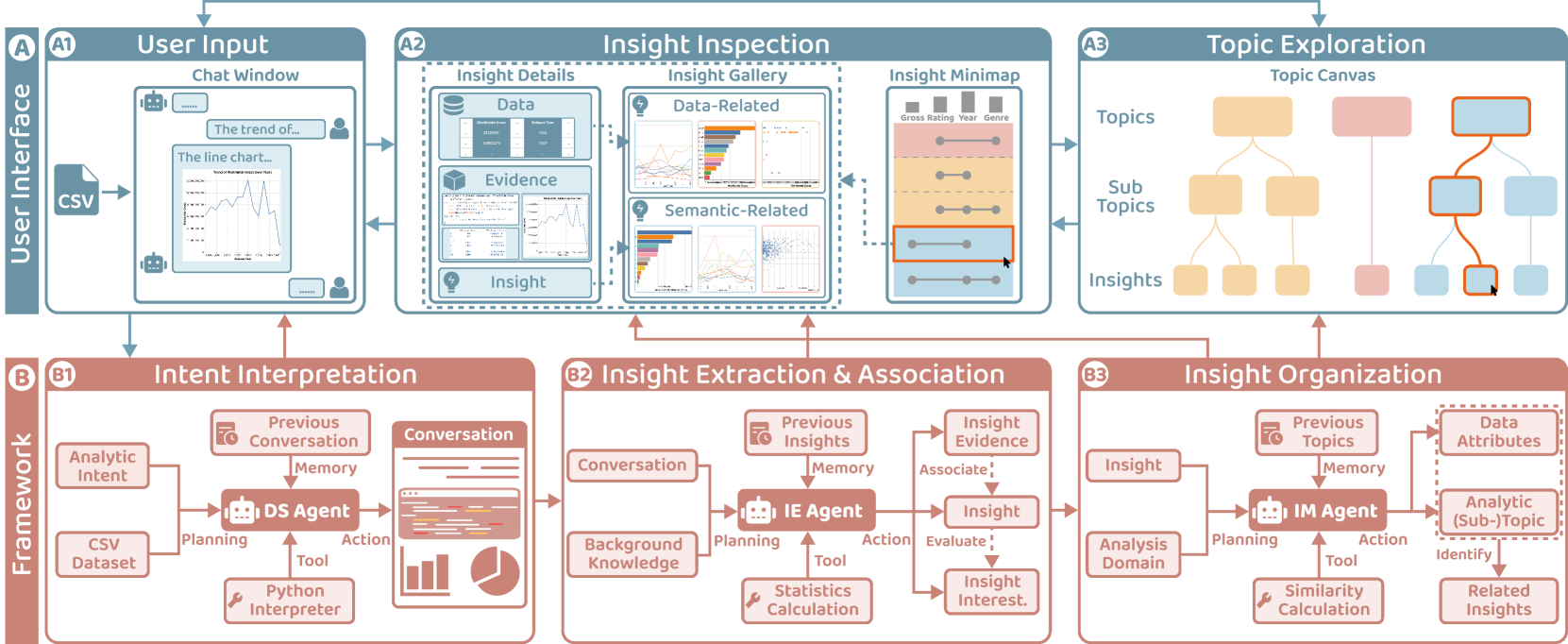
InsightLens: Discovering and Exploring Insights from Conversational Contexts in Large-Language-Model-Powered Data Analysis
Luoxuan Weng, Xingbo Wang, Junyu Lu, Yingchaojie Feng, Yihan Liu, Wei Chen
0
0
The proliferation of large language models (LLMs) has revolutionized the capabilities of natural language interfaces (NLIs) for data analysis. LLMs can perform multi-step and complex reasoning to generate data insights based on users' analytic intents. However, these insights often entangle with an abundance of contexts in analytic conversations such as code, visualizations, and natural language explanations. This hinders efficient identification, verification, and interpretation of insights within the current chat-based interfaces of LLMs. In this paper, we first conduct a formative study with eight experienced data analysts to understand their general workflow and pain points during LLM-powered data analysis. Then, we propose an LLM-based multi-agent framework to automatically extract, associate, and organize insights along with the analysis process. Based on this, we introduce InsightLens, an interactive system that visualizes the intricate conversational contexts from multiple aspects to facilitate insight discovery and exploration. A user study with twelve data analysts demonstrates the effectiveness of InsightLens, showing that it significantly reduces users' manual and cognitive effort without disrupting their conversational data analysis workflow, leading to a more efficient analysis experience.
4/3/2024
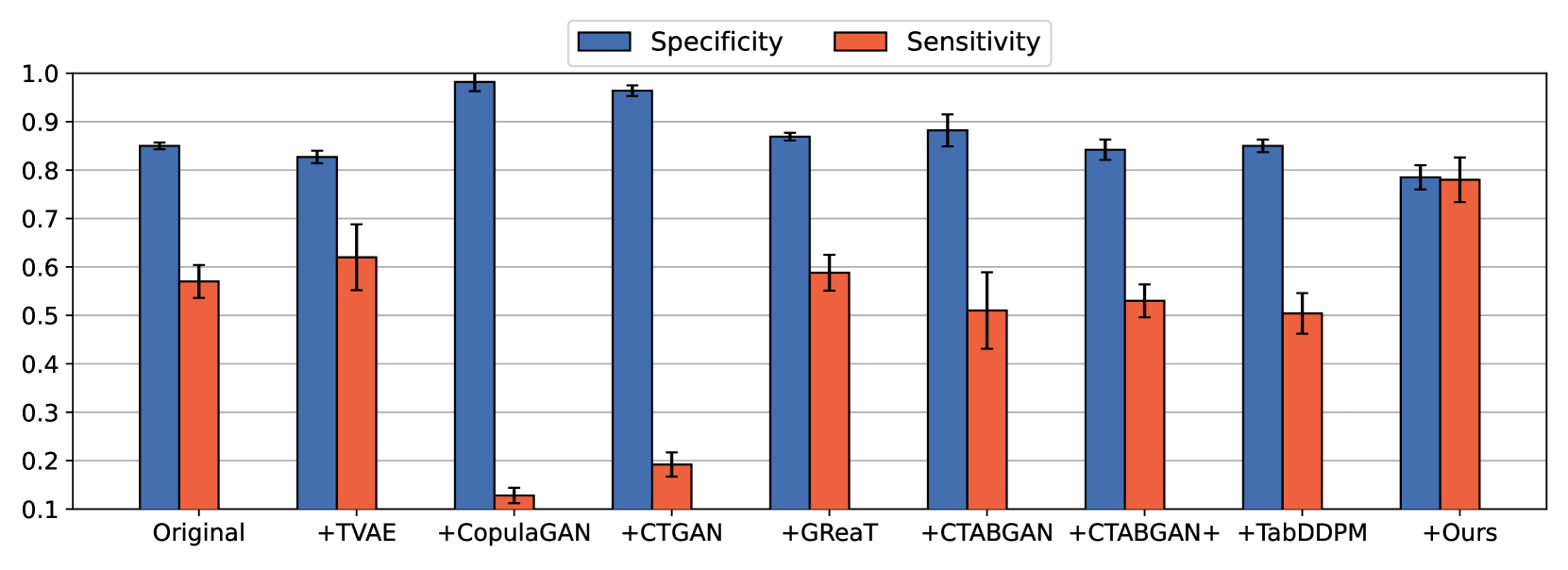
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
Generating realistic synthetic tabular data presents a critical challenge in machine learning. This study introduces a simple yet effective method employing Large Language Models (LLMs) tailored to generate synthetic data, specifically addressing data imbalance problems. We propose a novel group-wise prompting method in CSV-style formatting that leverages the in-context learning capabilities of LLMs to produce data that closely adheres to the specified requirements and characteristics of the target dataset. Moreover, our proposed random word replacement strategy significantly improves the handling of monotonous categorical values, enhancing the accuracy and representativeness of the synthetic data. The effectiveness of our method is extensively validated across eight real-world public datasets, achieving state-of-the-art performance in downstream classification and regression tasks while maintaining inter-feature correlations and improving token efficiency over existing approaches. This advancement significantly contributes to addressing the key challenges of machine learning applications, particularly in the context of tabular data generation and handling class imbalance. The source code for our work is available at: https://github.com/seharanul17/synthetic-tabular-LLM
4/22/2024