Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
2404.09491
0
0
Abstract
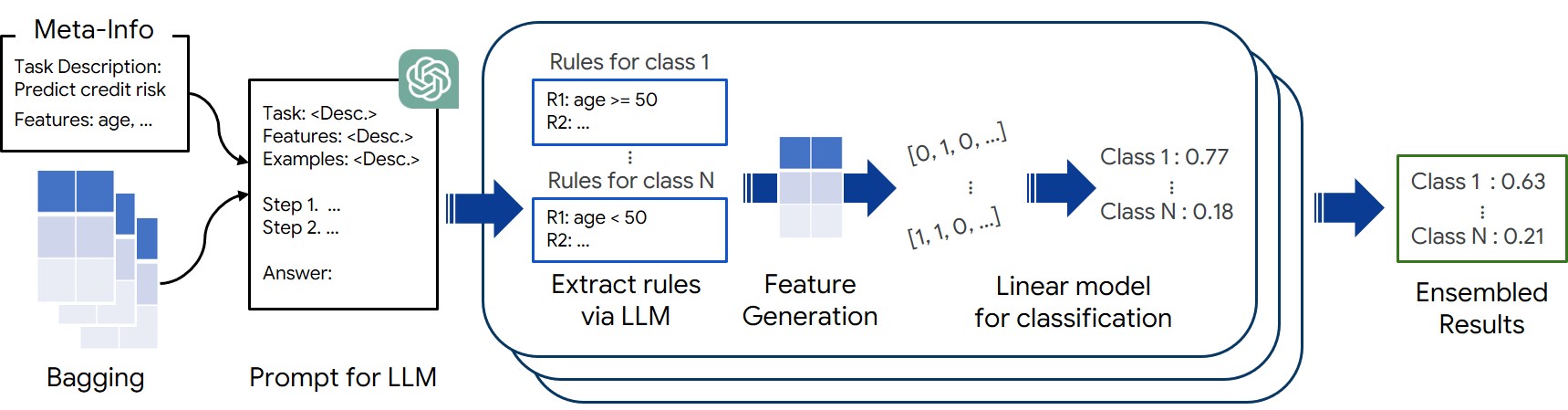
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
Create account to get full access
Related Work
Few-Shot Learning with Tabular Data
Few-shot learning is the challenge of learning new tasks or making predictions with limited training data. This can be particularly difficult for tabular data, which often has complex feature interactions and dependencies. Prior research has explored ways to leverage large language models (LLMs) for few-shot learning on tabular data.
For example, a blog post discussed how LLMs can be fine-tuned on tabular data to automatically engineer useful features, boosting few-shot learning performance. Another post showed how incorporating supervised knowledge into LLMs can further improve their ability to handle tabular data.
Research has also explored how LLMs can effectively memorize and learn from small tabular datasets, as described in a post on "elephants never forgetting". Additionally, a paper examined the fairness implications of using LLMs for tabular learning compared to traditional machine learning models.
Overall, this prior work suggests that LLMs hold significant promise for addressing the challenges of few-shot learning on tabular data, though there are still open questions around feature engineering, knowledge incorporation, and fairness that require further research, as discussed in the OpenTab project.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Unleashing the Potential of Large Language Models for Predictive Tabular Tasks in Data Science
Yazheng Yang, Yuqi Wang, Sankalok Sen, Lei Li, Qi Liu
0
0
In the domain of data science, the predictive tasks of classification, regression, and imputation of missing values are commonly encountered challenges associated with tabular data. This research endeavors to apply Large Language Models (LLMs) towards addressing these predictive tasks. Despite their proficiency in comprehending natural language, LLMs fall short in dealing with structured tabular data. This limitation stems from their lacking exposure to the intricacies of tabular data during their foundational training. Our research aims to mitigate this gap by compiling a comprehensive corpus of tables annotated with instructions and executing large-scale training of Llama-2 on this enriched dataset. Furthermore, we investigate the practical application of applying the trained model to zero-shot prediction, few-shot prediction, and in-context learning scenarios. Through extensive experiments, our methodology has shown significant improvements over existing benchmarks. These advancements highlight the efficacy of tailoring LLM training to solve table-related problems in data science, thereby establishing a new benchmark in the utilization of LLMs for enhancing tabular intelligence.
4/9/2024
✨
Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, Jinwoo Shin
0
0
Learning effective representations from raw data is crucial for the success of deep learning methods. However, in the tabular domain, practitioners often prefer augmenting raw column features over using learned representations, as conventional tree-based algorithms frequently outperform competing approaches. As a result, feature engineering methods that automatically generate candidate features have been widely used. While these approaches are often effective, there remains ambiguity in defining the space over which to search for candidate features. Moreover, they often rely solely on validation scores to select good features, neglecting valuable feedback from past experiments that could inform the planning of future experiments. To address the shortcomings, we propose a new tabular learning framework based on large language models (LLMs), coined Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage LLMs' reasoning capabilities to find good feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. Here, we choose a decision tree as reasoning as it can be interpreted in natural language, effectively conveying knowledge of past experiments (i.e., the prediction models trained with the generated features) to the LLM. Our empirical results demonstrate that this simple framework consistently enhances the performance of various prediction models across diverse tabular benchmarks, outperforming competing automatic feature engineering methods.
6/14/2024

Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
Xi Fang, Weijie Xu, Fiona Anting Tan, Jiani Zhang, Ziqing Hu, Yanjun Qi, Scott Nickleach, Diego Socolinsky, Srinivasan Sengamedu, Christos Faloutsos
0
0
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
6/25/2024

New!Anomaly Detection of Tabular Data Using LLMs
Aodong Li, Yunhan Zhao, Chen Qiu, Marius Kloft, Padhraic Smyth, Maja Rudolph, Stephan Mandt
0
0
Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
6/25/2024