Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
2404.10595
0
0
Abstract
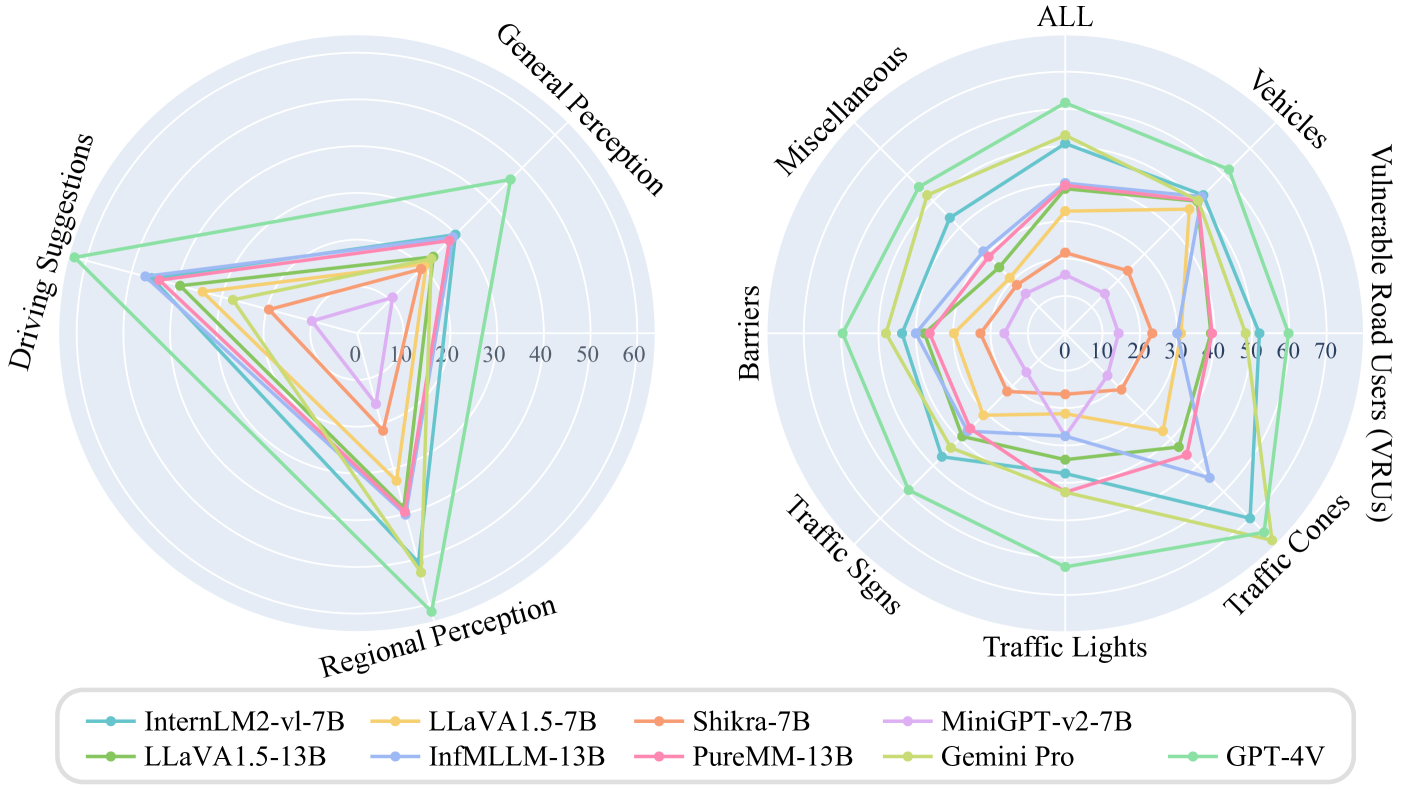
Large Vision-Language Models (LVLMs) have received widespread attention in advancing the interpretable self-driving. Existing evaluations of LVLMs primarily focus on the multi-faceted capabilities in natural circumstances, lacking automated and quantifiable assessment for self-driving, let alone the severe road corner cases. In this paper, we propose CODA-LM, the very first benchmark for the automatic evaluation of LVLMs for self-driving corner cases. We adopt a hierarchical data structure to prompt powerful LVLMs to analyze complex driving scenes and generate high-quality pre-annotation for human annotators, and for LVLM evaluation, we show that using the text-only large language models (LLMs) as judges reveals even better alignment with human preferences than the LVLM judges. Moreover, with CODA-LM, we build CODA-VLM, a new driving LVLM surpassing all the open-sourced counterparts on CODA-LM. Our CODA-VLM performs comparably with GPT-4V, even surpassing GPT-4V by +21.42% on the regional perception task. We hope CODA-LM can become the catalyst to promote interpretable self-driving empowered by LVLMs.
Create account to get full access
Overview
- This paper presents an automated evaluation framework for assessing the performance of large vision-language models (LVLMs) on challenging self-driving corner cases.
- The authors develop a suite of diverse and realistic self-driving scenarios to stress-test the capabilities of LVLMs, which are becoming increasingly important for autonomous vehicles.
- The evaluation framework covers a range of tasks, including object detection, action recognition, and scene understanding, providing a comprehensive assessment of LVLM capabilities in the self-driving domain.
Plain English Explanation
The paper focuses on evaluating how well large vision-language models (LVLMs) - powerful AI systems that can understand and generate text and images - perform on challenging scenarios related to self-driving cars. As these models become more important for autonomous vehicles, the researchers created a set of diverse and realistic driving situations to thoroughly test the models' abilities.
The evaluation framework covers a variety of tasks that are crucial for self-driving, such as detecting objects, recognizing actions, and understanding the overall scene. By assessing the models' performance across these different areas, the researchers can get a comprehensive understanding of the strengths and weaknesses of LVLMs when it comes to the complex challenges of autonomous driving.
This work is important because it provides a way to systematically evaluate the readiness of these advanced AI models for real-world self-driving applications, where safety and reliability are paramount. The insights gained from this research can help guide the further development and deployment of LVLMs in autonomous vehicles.
Technical Explanation
The paper proposes an automated evaluation framework for assessing the performance of large vision-language models (LVLMs) on a suite of self-driving corner cases. The authors argue that as LVLMs become increasingly important for autonomous vehicles, it is crucial to have a comprehensive evaluation of their capabilities in this domain.
The evaluation framework covers a range of tasks, including object detection, action recognition, and scene understanding. The authors develop a diverse set of realistic self-driving scenarios that stress-test the models' abilities to handle complex, safety-critical situations. These scenarios are designed to assess the models' robustness, generalization, and decision-making capabilities in the context of autonomous driving.
To enable automated evaluation, the authors curate a large-scale dataset of self-driving corner cases, with detailed annotations for the various tasks. They also provide baseline models and evaluation metrics to facilitate comparison and benchmarking of different LVLM approaches.
The technical details of the evaluation framework, dataset, and baseline models are presented in the paper, along with the results of experiments comparing the performance of various LVLM architectures on the proposed benchmark.
Critical Analysis
The paper presents a valuable contribution to the field of autonomous driving by addressing the critical need for comprehensive evaluation of LVLMs in this domain. The authors' approach of developing a diverse set of realistic self-driving corner cases is particularly noteworthy, as it goes beyond typical evaluation on curated, standardized datasets.
However, the paper could have benefited from a more in-depth discussion of the limitations and potential issues with the proposed evaluation framework. For example, the authors could have addressed concerns about the representativeness of the curated scenarios, the potential for biases in the dataset, and the scalability of the automated evaluation process.
Additionally, while the paper provides a solid technical foundation, it could have been strengthened by a more thorough analysis of the implications of the research findings. The authors could have delved deeper into the practical significance of the evaluated LVLM capabilities, their potential impact on the development of safer and more reliable autonomous vehicles, and the broader implications for the field of machine learning in the context of safety-critical applications.
Conclusion
This paper presents an important step forward in the evaluation of large vision-language models (LVLMs) for autonomous driving applications. By developing a comprehensive evaluation framework focused on self-driving corner cases, the authors have created a valuable tool for assessing the readiness and capabilities of these advanced AI models for real-world deployment in autonomous vehicles.
The insights gained from this research can inform the continued development and refinement of LVLMs, helping to ensure that they are equipped to handle the complex and safety-critical challenges of autonomous driving. As the importance of LVLMs in this domain continues to grow, the work described in this paper will become increasingly crucial for driving progress in the field of autonomous vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024
👀
Vision Language Models in Autonomous Driving: A Survey and Outlook
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, Alois C. Knoll
0
0
The applications of Vision-Language Models (VLMs) in the field of Autonomous Driving (AD) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By incorporating language data, driving systems can gain a better understanding of real-world environments, thereby enhancing driving safety and efficiency. In this work, we present a comprehensive and systematic survey of the advances in vision language models in this domain, encompassing perception and understanding, navigation and planning, decision-making and control, end-to-end autonomous driving, and data generation. We introduce the mainstream VLM tasks in AD and the commonly utilized metrics. Additionally, we review current studies and applications in various areas and summarize the existing language-enhanced autonomous driving datasets thoroughly. Lastly, we discuss the benefits and challenges of VLMs in AD and provide researchers with the current research gaps and future trends.
6/26/2024
Personalized Autonomous Driving with Large Language Models: Field Experiments
Can Cui, Zichong Yang, Yupeng Zhou, Yunsheng Ma, Juanwu Lu, Lingxi Li, Yaobin Chen, Jitesh Panchal, Ziran Wang
0
0
Integrating large language models (LLMs) in autonomous vehicles enables conversation with AI systems to drive the vehicle. However, it also emphasizes the requirement for such systems to comprehend commands accurately and achieve higher-level personalization to adapt to the preferences of drivers or passengers over a more extended period. In this paper, we introduce an LLM-based framework, Talk2Drive, capable of translating natural verbal commands into executable controls and learning to satisfy personal preferences for safety, efficiency, and comfort with a proposed memory module. This is the first-of-its-kind multi-scenario field experiment that deploys LLMs on a real-world autonomous vehicle. Experiments showcase that the proposed system can comprehend human intentions at different intuition levels, ranging from direct commands like can you drive faster to indirect commands like I am really in a hurry now. Additionally, we use the takeover rate to quantify the trust of human drivers in the LLM-based autonomous driving system, where Talk2Drive significantly reduces the takeover rate in highway, intersection, and parking scenarios. We also validate that the proposed memory module considers personalized preferences and further reduces the takeover rate by up to 65.2% compared with those without a memory module. The experiment video can be watched at https://www.youtube.com/watch?v=4BWsfPaq1Ro
5/9/2024

CarLLaVA: Vision language models for camera-only closed-loop driving
Katrin Renz, Long Chen, Ana-Maria Marcu, Jan Hunermann, Benoit Hanotte, Alice Karnsund, Jamie Shotton, Elahe Arani, Oleg Sinavski
0
0
In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
6/17/2024