CarLLaVA: Vision language models for camera-only closed-loop driving
2406.10165
0
0

Abstract
In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
Create account to get full access
Overview
• This paper, titled "CarLLaVA: Vision language models for camera-only closed-loop driving," explores the use of vision-language models for autonomous driving in a camera-only setup.
• The researchers investigate the feasibility of using these models to control a vehicle's steering and throttle without relying on additional sensors like LIDAR or radar.
• The proposed approach, called CarLLaVA, aims to enable camera-only closed-loop driving by leveraging advancements in vision-language models.
Plain English Explanation
• The paper investigates using vision-language models to control a self-driving car using only the information from a camera, without needing additional sensors like LIDAR or radar.
• Vision-language models are AI systems that can understand and process both visual information (like images or videos) and language (like text or speech). The researchers explore how these models can be used to make decisions about steering and throttle control for a vehicle, based solely on the camera feed.
• This "camera-only closed-loop driving" approach could potentially simplify the hardware required for autonomous vehicles, making them more accessible and affordable. The CO-Driver and LEGO-Drive projects explore similar ideas.
Technical Explanation
• The researchers propose the CarLLaVA (Camera-only Language-and-Vision Autonomy) framework, which uses a vision-language model to process the camera feed and generate appropriate steering and throttle commands for the vehicle.
• The key components of CarLLaVA include:
- A vision-language model that can understand and reason about the visual scene from the camera.
- A control module that translates the model's understanding into steering and throttle signals to control the vehicle.
- A closed-loop control system that continuously adjusts the vehicle's actions based on the camera input.
• The paper presents experiments evaluating the performance of CarLLaVA on various driving tasks, including lane following, intersection navigation, and object avoidance. The results demonstrate the potential of vision-language models for camera-only autonomous driving.
• The researchers also discuss the integration of the OpenVLA vision-language model into the CarLLaVA framework, highlighting the benefits of using open-source tools for this research.
Critical Analysis
• The paper presents a promising approach to camera-only autonomous driving, but it acknowledges the limitations of current vision-language models, which may struggle with complex or ambiguous situations.
• The researchers suggest that further advancements in vision-language models, as well as the integration of additional sensors or driving task-specific modules, may be necessary to achieve robust and reliable camera-only closed-loop driving.
• The TrafficVLM project, which explores using vision-language models for traffic video understanding, could provide insights relevant to the CarLLaVA approach.
Conclusion
• The CarLLaVA framework demonstrates the potential of using vision-language models for camera-only autonomous driving, which could lead to more accessible and affordable self-driving technology.
• The research highlights the importance of continued advancements in vision-language models and the integration of various sensing modalities to achieve reliable and safe autonomous driving solutions.
• Overall, the paper contributes to the ongoing efforts to develop camera-only autonomous driving systems, which could have significant implications for the future of transportation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024
🤔
Co-driver: VLM-based Autonomous Driving Assistant with Human-like Behavior and Understanding for Complex Road Scenes
Ziang Guo, Artem Lykov, Zakhar Yagudin, Mikhail Konenkov, Dzmitry Tsetserukou
0
0
Recent research about Large Language Model based autonomous driving solutions shows a promising picture in planning and control fields. However, heavy computational resources and hallucinations of Large Language Models continue to hinder the tasks of predicting precise trajectories and instructing control signals. To address this problem, we propose Co-driver, a novel autonomous driving assistant system to empower autonomous vehicles with adjustable driving behaviors based on the understanding of road scenes. A pipeline involving the CARLA simulator and Robot Operating System 2 (ROS2) verifying the effectiveness of our system is presented, utilizing a single Nvidia 4090 24G GPU while exploiting the capacity of textual output of the Visual Language Model. Besides, we also contribute a dataset containing an image set and a corresponding prompt set for fine-tuning the Visual Language Model module of our system. In the real-world driving dataset, our system achieved 96.16% success rate in night scenes and 89.7% in gloomy scenes regarding reasonable predictions. Our Co-driver dataset will be released at https://github.com/ZionGo6/Co-driver.
5/10/2024
👀
Vision Language Models in Autonomous Driving: A Survey and Outlook
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, Alois C. Knoll
0
0
The applications of Vision-Language Models (VLMs) in the field of Autonomous Driving (AD) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By incorporating language data, driving systems can gain a better understanding of real-world environments, thereby enhancing driving safety and efficiency. In this work, we present a comprehensive and systematic survey of the advances in vision language models in this domain, encompassing perception and understanding, navigation and planning, decision-making and control, end-to-end autonomous driving, and data generation. We introduce the mainstream VLM tasks in AD and the commonly utilized metrics. Additionally, we review current studies and applications in various areas and summarize the existing language-enhanced autonomous driving datasets thoroughly. Lastly, we discuss the benefits and challenges of VLMs in AD and provide researchers with the current research gaps and future trends.
6/26/2024
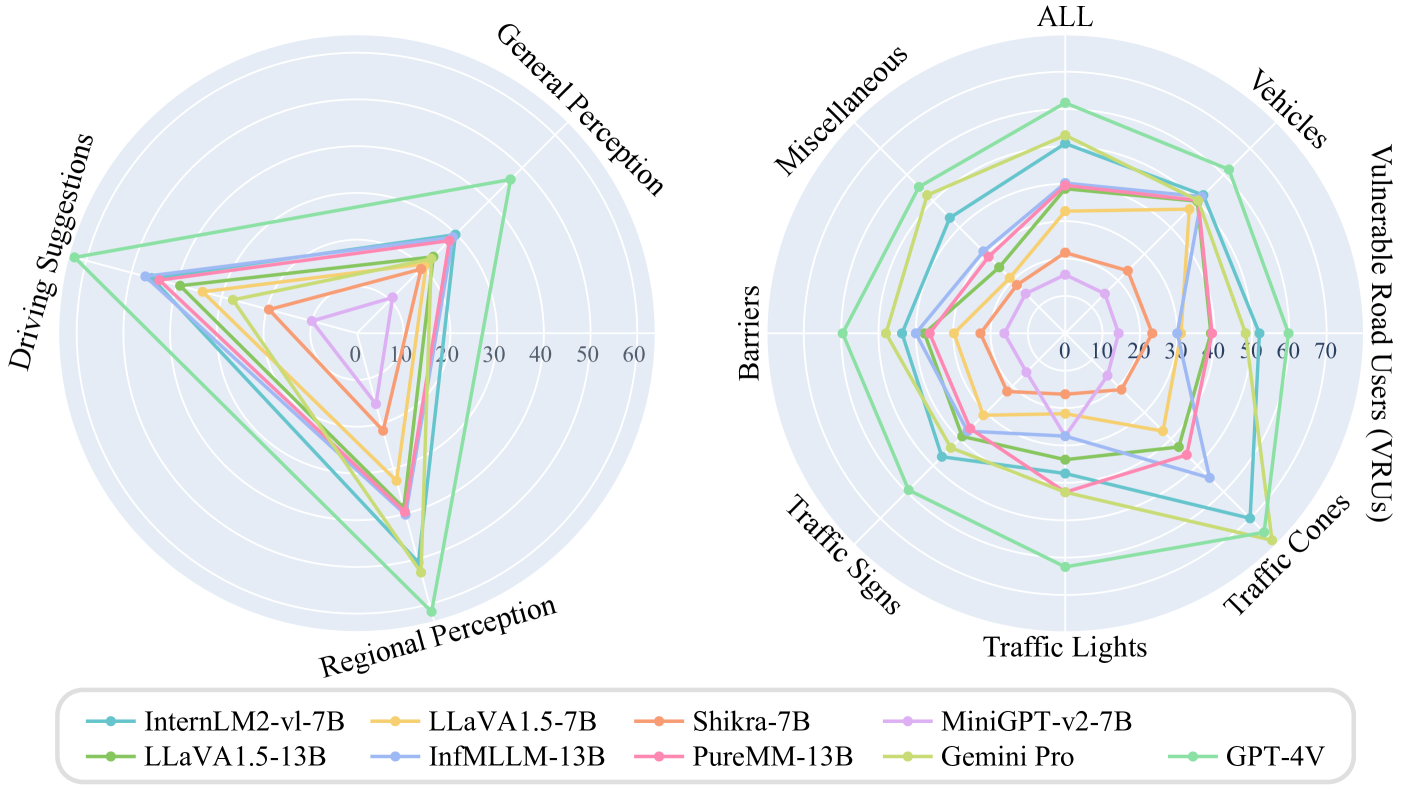
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Kai Chen, Yanze Li, Wenhua Zhang, Yanxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, Dit-Yan Yeung, Huchuan Lu, Xu Jia
0
0
Large Vision-Language Models (LVLMs) have received widespread attention in advancing the interpretable self-driving. Existing evaluations of LVLMs primarily focus on the multi-faceted capabilities in natural circumstances, lacking automated and quantifiable assessment for self-driving, let alone the severe road corner cases. In this paper, we propose CODA-LM, the very first benchmark for the automatic evaluation of LVLMs for self-driving corner cases. We adopt a hierarchical data structure to prompt powerful LVLMs to analyze complex driving scenes and generate high-quality pre-annotation for human annotators, and for LVLM evaluation, we show that using the text-only large language models (LLMs) as judges reveals even better alignment with human preferences than the LVLM judges. Moreover, with CODA-LM, we build CODA-VLM, a new driving LVLM surpassing all the open-sourced counterparts on CODA-LM. Our CODA-VLM performs comparably with GPT-4V, even surpassing GPT-4V by +21.42% on the regional perception task. We hope CODA-LM can become the catalyst to promote interpretable self-driving empowered by LVLMs.
6/28/2024