Automated Knowledge Concept Annotation and Question Representation Learning for Knowledge Tracing

0
Sign in to get full access
Overview
- Introduces an automated approach for annotating knowledge concepts in educational questions and learning question representations for knowledge tracing
- Proposes a novel framework that jointly learns concept annotations and question representations to improve knowledge tracing performance
- Demonstrated effectiveness on several benchmark datasets for knowledge tracing
Plain English Explanation
The paper discusses a new method for automatically annotating the knowledge concepts covered in educational questions and learning effective representations of those questions to improve knowledge tracing - the task of modeling a student's mastery of different skills over time.
The key idea is to jointly learn the annotations of knowledge concepts in questions and the representations of those questions, rather than treating them as separate tasks. This allows the model to leverage the connections between the question content, the knowledge involved, and the student's learning progress. The authors demonstrate that this approach outperforms prior methods on several benchmark datasets for knowledge tracing.
The significance of this work is that it provides a more integrated and effective way to trace students' knowledge acquisition by modeling the relationship between the questions, the underlying knowledge, and the students' responses. This could lead to better personalized learning experiences and more accurate assessments of student mastery.
Technical Explanation
The paper proposes a novel framework called Automated Knowledge Concept Annotation and Question Representation Learning (AKCANQRL) for knowledge tracing. The key components are:
-
Automated Knowledge Concept Annotation: This module automatically annotates the knowledge concepts covered in each educational question using a pre-trained language model. This provides a structured representation of the knowledge tested in each question.
-
Question Representation Learning: This module learns effective vector representations of the questions by incorporating the automatically annotated knowledge concepts. The question representations are designed to capture both the semantic content of the questions and the underlying knowledge tested.
-
Joint Learning: The concept annotation and question representation modules are trained jointly, allowing the model to leverage the connections between the question content, knowledge concepts, and student responses for improved knowledge tracing performance.
The authors evaluate AKCANQRL on several benchmark datasets for knowledge tracing and show that it outperforms prior state-of-the-art methods. The results demonstrate the benefits of the integrated approach to modeling questions, knowledge, and student learning.
Critical Analysis
The paper provides a compelling approach for automating the annotation of knowledge concepts in educational questions and using that information to learn better question representations for knowledge tracing. However, there are a few potential limitations and areas for further research:
-
The reliance on pre-trained language models for concept annotation may limit the approach's adaptability to new domains or question types not well-represented in the pre-training data.
-
The evaluation is primarily focused on standardized test-style questions, and the performance on more open-ended or problem-solving-oriented questions is unclear.
-
The paper does not address potential biases or inconsistencies in the automatically generated concept annotations, which could impact the downstream knowledge tracing performance.
-
Exploring ways to incorporate additional contextual information, such as student demographics or learning behaviors, could further improve the knowledge tracing capabilities.
Overall, the paper presents a promising direction for integrating question content, knowledge concepts, and student learning, but additional research is needed to address the potential limitations and expand the approach's applicability.
Conclusion
This paper introduces an automated framework for annotating knowledge concepts in educational questions and learning effective question representations to improve knowledge tracing. The key innovation is the joint learning of concept annotations and question representations, which allows the model to leverage the connections between the question content, underlying knowledge, and student responses.
The empirical results demonstrate the effectiveness of this approach on several benchmark datasets, suggesting that the integrated modeling of questions, knowledge, and student learning can lead to more accurate and personalized assessments of student mastery. While there are some potential limitations, this work represents an important step towards enhancing knowledge tracing capabilities and ultimately, improving personalized learning experiences for students.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Automated Knowledge Concept Annotation and Question Representation Learning for Knowledge Tracing
Yilmazcan Ozyurt, Stefan Feuerriegel, Mrinmaya Sachan
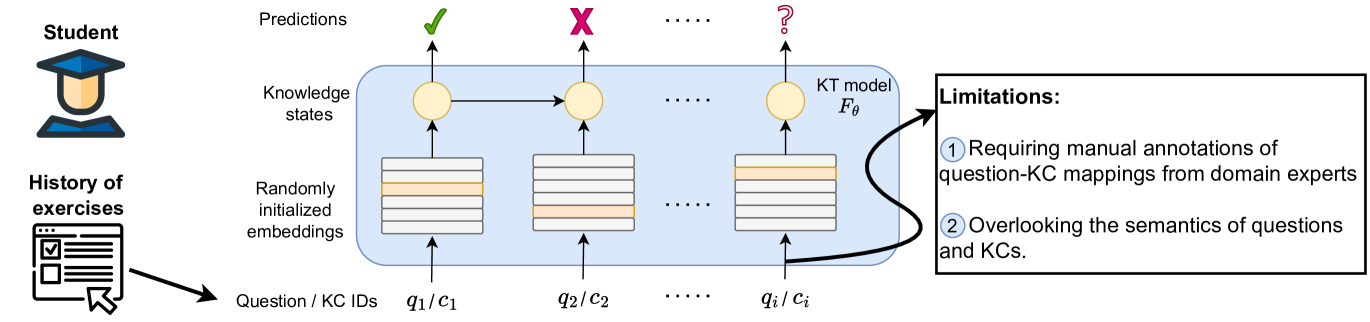
Knowledge tracing (KT) is a popular approach for modeling students' learning progress over time, which can enable more personalized and adaptive learning. However, existing KT approaches face two major limitations: (1) they rely heavily on expert-defined knowledge concepts (KCs) in questions, which is time-consuming and prone to errors; and (2) KT methods tend to overlook the semantics of both questions and the given KCs. In this work, we address these challenges and present KCQRL, a framework for automated knowledge concept annotation and question representation learning that can improve the effectiveness of any existing KT model. First, we propose an automated KC annotation process using large language models (LLMs), which generates question solutions and then annotates KCs in each solution step of the questions. Second, we introduce a contrastive learning approach to generate semantically rich embeddings for questions and solution steps, aligning them with their associated KCs via a tailored false negative elimination approach. These embeddings can be readily integrated into existing KT models, replacing their randomly initialized embeddings. We demonstrate the effectiveness of KCQRL across 15 KT algorithms on two large real-world Math learning datasets, where we achieve consistent performance improvements.
Read more10/3/2024

0
A Question-centric Multi-experts Contrastive Learning Framework for Improving the Accuracy and Interpretability of Deep Sequential Knowledge Tracing Models
Hengyuan Zhang, Zitao Liu, Chenming Shang, Dawei Li, Yong Jiang
Knowledge tracing (KT) plays a crucial role in predicting students' future performance by analyzing their historical learning processes. Deep neural networks (DNNs) have shown great potential in solving the KT problem. However, there still exist some important challenges when applying deep learning techniques to model the KT process. The first challenge lies in taking the individual information of the question into modeling. This is crucial because, despite questions sharing the same knowledge component (KC), students' knowledge acquisition on homogeneous questions can vary significantly. The second challenge lies in interpreting the prediction results from existing deep learning-based KT models. In real-world applications, while it may not be necessary to have complete transparency and interpretability of the model parameters, it is crucial to present the model's prediction results in a manner that teachers find interpretable. This makes teachers accept the rationale behind the prediction results and utilize them to design teaching activities and tailored learning strategies for students. However, the inherent black-box nature of deep learning techniques often poses a hurdle for teachers to fully embrace the model's prediction results. To address these challenges, we propose a Question-centric Multi-experts Contrastive Learning framework for KT called Q-MCKT. We have provided all the datasets and code on our website at https://github.com/rattlesnakey/Q-MCKT.
Read more7/8/2024

0
Language Model Can Do Knowledge Tracing: Simple but Effective Method to Integrate Language Model and Knowledge Tracing Task
Unggi Lee, Jiyeong Bae, Dohee Kim, Sookbun Lee, Jaekwon Park, Taekyung Ahn, Gunho Lee, Damji Stratton, Hyeoncheol Kim
Knowledge Tracing (KT) is a critical task in online learning for modeling student knowledge over time. Despite the success of deep learning-based KT models, which rely on sequences of numbers as data, most existing approaches fail to leverage the rich semantic information in the text of questions and concepts. This paper proposes Language model-based Knowledge Tracing (LKT), a novel framework that integrates pre-trained language models (PLMs) with KT methods. By leveraging the power of language models to capture semantic representations, LKT effectively incorporates textual information and significantly outperforms previous KT models on large benchmark datasets. Moreover, we demonstrate that LKT can effectively address the cold-start problem in KT by leveraging the semantic knowledge captured by PLMs. Interpretability of LKT is enhanced compared to traditional KT models due to its use of text-rich data. We conducted the local interpretable model-agnostic explanation technique and analysis of attention scores to interpret the model performance further. Our work highlights the potential of integrating PLMs with KT and paves the way for future research in KT domain.
Read more6/11/2024
0
Knowledge Tagging System on Math Questions via LLMs with Flexible Demonstration Retriever
Hang Li, Tianlong Xu, Jiliang Tang, Qingsong Wen
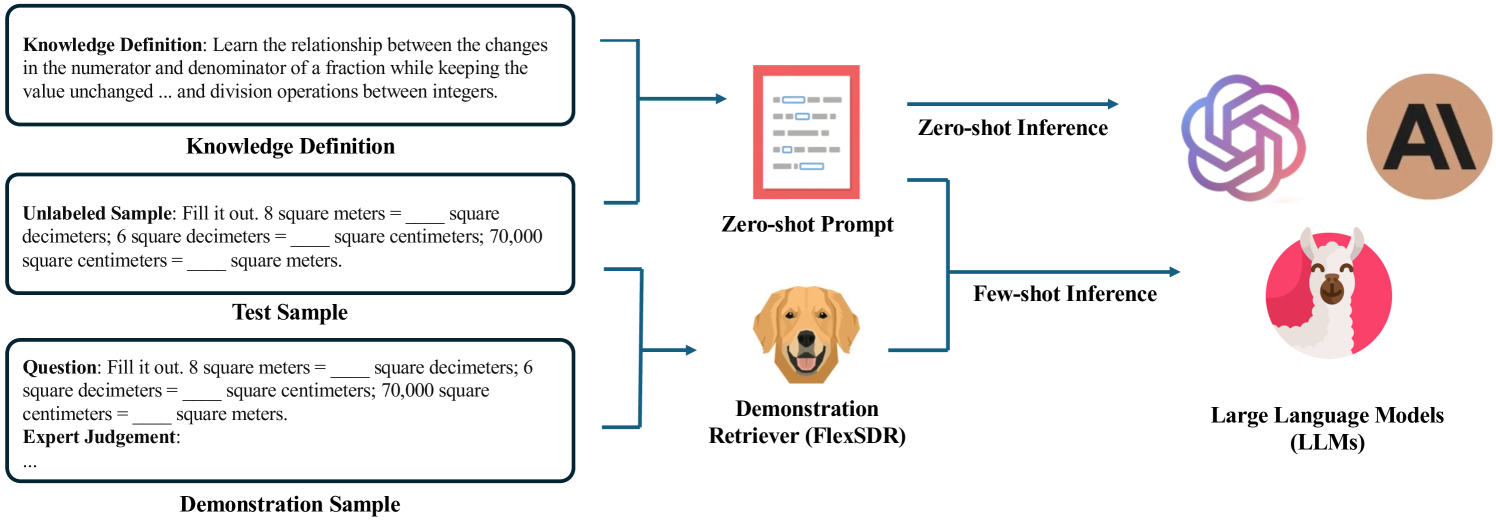
Knowledge tagging for questions plays a crucial role in contemporary intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations are always conducted by pedagogical experts, as the task requires not only a strong semantic understanding of both question stems and knowledge definitions but also deep insights into connecting question-solving logic with corresponding knowledge concepts. With the recent emergence of advanced text encoding algorithms, such as pre-trained language models, many researchers have developed automatic knowledge tagging systems based on calculating the semantic similarity between the knowledge and question embeddings. In this paper, we explore automating the task using Large Language Models (LLMs), in response to the inability of prior encoding-based methods to deal with the hard cases which involve strong domain knowledge and complicated concept definitions. By showing the strong performance of zero- and few-shot results over math questions knowledge tagging tasks, we demonstrate LLMs' great potential in conquering the challenges faced by prior methods. Furthermore, by proposing a reinforcement learning-based demonstration retriever, we successfully exploit the great potential of different-sized LLMs in achieving better performance results while keeping the in-context demonstration usage efficiency high.
Read more6/21/2024