Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics

0
🎯
Sign in to get full access
Overview
- Automatic speech recognition (ASR) can be used to automatically assess reading fluency, which is important for early detection of reading difficulties.
- Precise assessment tools are needed, especially for languages other than English.
- This study evaluates six ASR-based systems for assessing oral reading accuracy in Dutch.
- The most successful system reached substantial agreement with human evaluations.
Plain English Explanation
Automatically assessing how fluently someone reads out loud using speech recognition technology has great potential for identifying reading problems early on and providing timely support. However, these assessment tools need to be very accurate, especially for languages besides English.
In this research, the scientists tested six different speech recognition systems to see how well they could automatically evaluate the accuracy of people reading out loud in Dutch. They found that their most successful system was able to match human experts' assessments to a large degree. This system did the best job of predicting whether a word was read correctly or not based on the confidence level of its speech recognition.
Importantly, the language model used by this top-performing system included not just the correct words, but also common reading mistakes. This shows that incorporating typical errors people make when reading out loud can improve the accuracy of these automatic assessment tools. Overall, this study demonstrates the promise of using speech recognition to evaluate reading fluency, especially for languages besides English.
Technical Explanation
This study evaluated the use of six state-of-the-art automatic speech recognition (ASR) systems for assessing oral reading accuracy in Dutch. The researchers used the Kaldi and Whisper ASR frameworks to build and test these systems.
The key finding was that the most successful system reached substantial agreement with human expert evaluations, achieving a Matthews Correlation Coefficient of 0.63. This system also had the highest correlation between its confidence scores and the actual correctness of the words, with a Pearson's r of 0.45.
Importantly, the language model (LM) used by this top-performing system incorporated not just the correct words, but also common reading errors and mistakes. This indicates that including typical reading errors in the LM can improve the performance of ASR-based reading assessment systems.
The researchers discuss the implications of these results for developing effective automatic assessment tools, especially for languages beyond English. They also identify potential avenues for future research, such as exploring deep learning techniques for this task.
Critical Analysis
While the results of this study are promising, the researchers acknowledge several caveats and limitations. First, the dataset used was relatively small, so further evaluation on larger and more diverse datasets would be beneficial. Additionally, the study focused only on assessing reading accuracy, while reading fluency involves other important factors like reading speed and expression.
Another potential issue is the reliance on human expert evaluations as the ground truth. Inconsistencies and biases in human assessments could affect the validity of the comparisons made in this study. Further research could explore ways to establish more objective benchmarks for evaluating reading assessment systems.
Overall, this study provides valuable insights into the potential of ASR-based systems for assessing reading in languages beyond English. However, more work is needed to address the limitations and expand the capabilities of these technologies to fully realize their promise for early intervention and support of reading development.
Conclusion
This research demonstrates the potential of using automatic speech recognition to assess oral reading accuracy, particularly for languages other than English. The most successful system in the study showed strong agreement with human expert evaluations, suggesting that ASR-based tools can be a viable approach for detecting reading difficulties early on and enabling timely intervention.
Importantly, the study found that incorporating common reading errors into the language model improved the performance of the assessment system. This highlights the importance of accounting for the unique characteristics of reading, rather than simply trying to achieve perfect transcription accuracy.
While further research is needed to address the limitations of this study, the findings contribute to the growing body of work exploring the use of speech recognition and other AI-powered technologies for supporting reading development and assessment. As these technologies continue to advance, they hold great promise for enhancing our ability to identify and assist individuals who struggle with reading.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Automatic Assessment of Oral Reading Accuracy for Reading Diagnostics
Bo Molenaar, Cristian Tejedor-Garcia, Helmer Strik, Catia Cucchiarini
Automatic assessment of reading fluency using automatic speech recognition (ASR) holds great potential for early detection of reading difficulties and subsequent timely intervention. Precise assessment tools are required, especially for languages other than English. In this study, we evaluate six state-of-the-art ASR-based systems for automatically assessing Dutch oral reading accuracy using Kaldi and Whisper. Results show our most successful system reached substantial agreement with human evaluations (MCC = .63). The same system reached the highest correlation between forced decoding confidence scores and word correctness (r = .45). This system's language model (LM) consisted of manual orthographic transcriptions and reading prompts of the test data, which shows that including reading errors in the LM improves assessment performance. We discuss the implications for developing automatic assessment systems and identify possible avenues of future research.
Read more7/24/2024
🤯
0
An ASR-Based Tutor for Learning to Read: How to Optimize Feedback to First Graders
Yu Bai, Cristian Tejedor-Garcia, Ferdy Hubers, Catia Cucchiarini, Helmer Strik
The interest in employing automatic speech recognition (ASR) in applications for reading practice has been growing in recent years. In a previous study, we presented an ASR-based Dutch reading tutor application that was developed to provide instantaneous feedback to first-graders learning to read. We saw that ASR has potential at this stage of the reading process, as the results suggested that pupils made progress in reading accuracy and fluency by using the software. In the current study, we used children's speech from an existing corpus (JASMIN) to develop two new ASR systems, and compared the results to those of the previous study. We analyze correct/incorrect classification of the ASR systems using human transcripts at word level, by means of evaluation measures such as Cohen's Kappa, Matthews Correlation Coefficient (MCC), precision, recall and F-measures. We observe improvements for the newly developed ASR systems regarding the agreement with human-based judgment and correct rejection (CR). The accuracy of the ASR systems varies for different reading tasks and word types. Our results suggest that, in the current configuration, it is difficult to classify isolated words. We discuss these results, possible ways to improve our systems and avenues for future research.
Read more7/24/2024
🔎
0
Reading Miscue Detection in Primary School through Automatic Speech Recognition
Lingyun Gao, Cristian Tejedor-Garcia, Helmer Strik, Catia Cucchiarini
Automatic reading diagnosis systems can benefit both teachers for more efficient scoring of reading exercises and students for accessing reading exercises with feedback more easily. However, there are limited studies on Automatic Speech Recognition (ASR) for child speech in languages other than English, and limited research on ASR-based reading diagnosis systems. This study investigates how efficiently state-of-the-art (SOTA) pretrained ASR models recognize Dutch native children speech and manage to detect reading miscues. We found that Hubert Large finetuned on Dutch speech achieves SOTA phoneme-level child speech recognition (PER at 23.1%), while Whisper (Faster Whisper Large-v2) achieves SOTA word-level performance (WER at 9.8%). Our findings suggest that Wav2Vec2 Large and Whisper are the two best ASR models for reading miscue detection. Specifically, Wav2Vec2 Large shows the highest recall at 0.83, whereas Whisper exhibits the highest precision at 0.52 and an F1 score of 0.52.
Read more7/24/2024
0
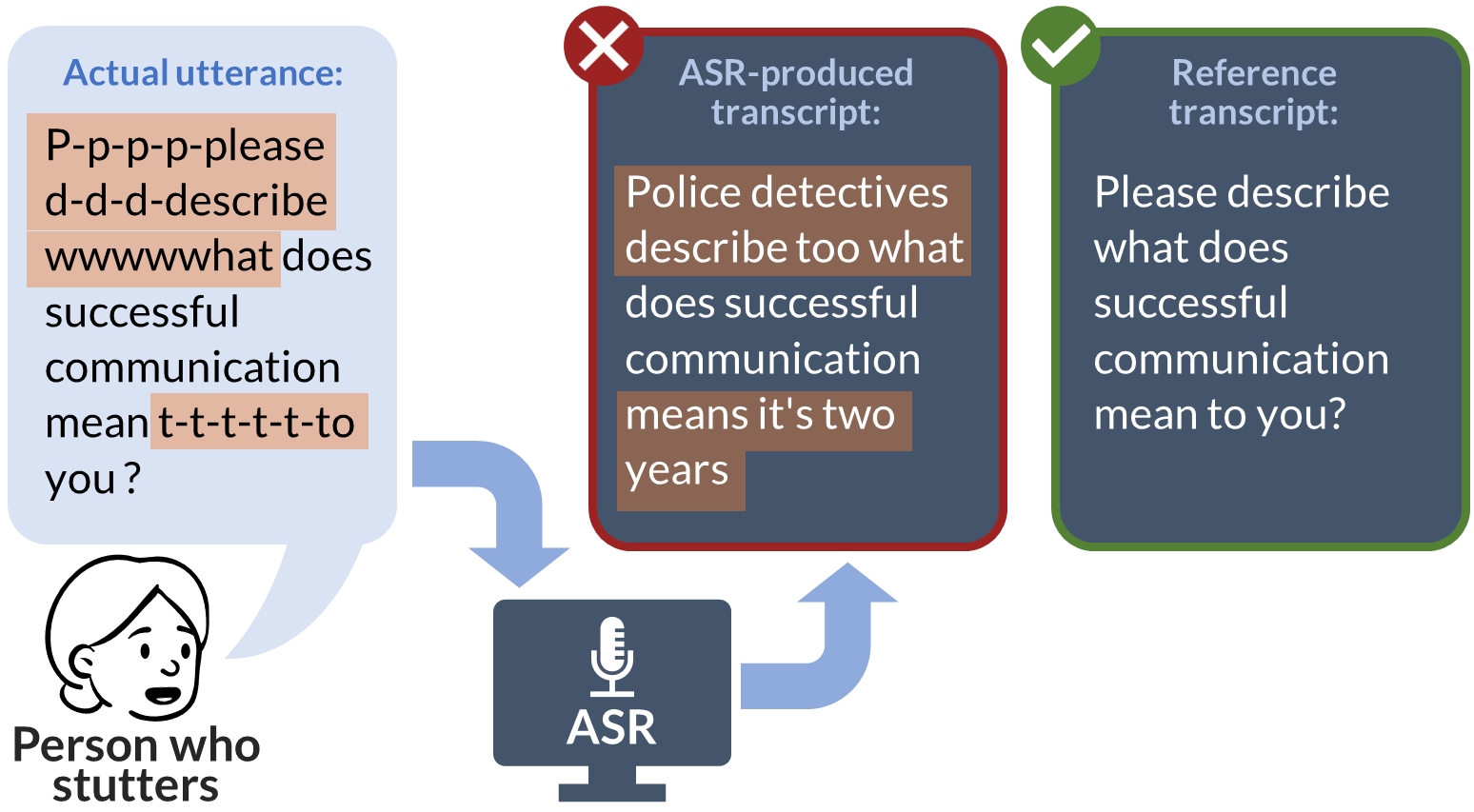
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
Read more5/13/2024