Automatic Generation of Fashion Images using Prompting in Generative Machine Learning Models

0

Sign in to get full access
Overview
- This paper explores using prompting techniques in generative machine learning models to automatically generate fashion images.
- The researchers investigate how to effectively prompt large language models to create high-quality fashion images.
- The goal is to enable the automated generation of fashion designs and outfits without the need for manual artistic creation.
Plain English Explanation
The paper discusses a method for generating fashion images using large language models and prompting techniques. The key idea is to provide the model with textual descriptions or prompts that specify the desired fashion items, styles, and visual attributes. The model then generates corresponding images in response to these prompts.
This approach aims to automate the process of fashion design and creation, allowing users to generate fashion images without the need for manual artistic skills or labor-intensive processes. By leveraging the capabilities of large language models, the researchers explore how to effectively prompt these models to produce high-quality, realistic fashion images that align with the specified descriptions.
The paper investigates the technical details of this prompting-based fashion image generation approach, examining the model architectures, training data, and optimization strategies used to achieve successful results. The goal is to enable more accessible and efficient fashion design and synthesis, potentially benefiting industries, designers, and consumers alike.
Technical Explanation
The paper proposes a framework for automatically generating fashion images using prompting techniques in generative machine learning models. The core idea is to leverage the powerful text-to-image generation capabilities of large language models and prompt them with textual descriptions of desired fashion items, styles, and visual attributes.
The researchers experiment with different model architectures, including Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), to assess their effectiveness in generating high-quality fashion images from text prompts. They also explore retrieval-augmented generation techniques, where the models incorporate information from a database of fashion images to enhance the generated outputs.
The training process involves exposing the models to large datasets of fashion-related textual descriptions and corresponding images, allowing the models to learn the associations between language and visual representations of fashion. The researchers experiment with different prompting strategies, including iterative prompting and prompt perturbation, to optimize the quality and diversity of the generated fashion images.
The paper presents quantitative and qualitative evaluations of the generated fashion images, assessing their realism, diversity, and alignment with the provided textual prompts. The findings suggest that prompting-based generation can be an effective approach for automating the creation of fashion designs and enabling more accessible and efficient fashion synthesis.
Critical Analysis
The paper presents a promising approach for automating the generation of fashion images using prompting techniques in generative machine learning models. The researchers have demonstrated the potential of leveraging large language models and textual prompts to produce high-quality, diverse fashion images.
However, the paper does not address several important limitations and potential concerns. First, the research is limited to evaluating the generated fashion images, without considering the practical implications or real-world applications of this technology. The paper does not explore how the generated fashion images could be integrated into the design workflow, or how they might impact the fashion industry and its stakeholders.
Additionally, the paper does not address potential ethical concerns, such as the potential for the misuse of this technology to create fake or deceptive fashion content, or the implications for creative professionals in the fashion industry. The researchers should have explored these aspects more thoroughly to provide a more comprehensive understanding of the implications and limitations of their approach.
Furthermore, the paper does not delve into the generalization capabilities of the proposed method. It is unclear how well the models would perform in generating fashion images for diverse cultural contexts, body types, or underrepresented communities. Investigating these aspects could reveal important insights and challenges that need to be addressed.
Overall, the paper presents an interesting and technically sound approach to fashion image generation, but it would benefit from a more in-depth discussion of the practical, ethical, and societal implications of this technology. Encouraging critical thinking and a balanced perspective on the potential benefits and drawbacks of this research could lead to more meaningful progress in this field.
Conclusion
This paper explores the use of prompting techniques in generative machine learning models to automatically generate fashion images. The researchers demonstrate the potential of leveraging large language models and textual prompts to produce high-quality, diverse fashion images, aiming to automate the process of fashion design and creation.
The technical approach involves experimenting with different model architectures, such as VAEs and GANs, and exploring techniques like retrieval-augmented generation to enhance the generated outputs. The training process involves exposing the models to large datasets of fashion-related textual descriptions and corresponding images, allowing the models to learn the associations between language and visual representations of fashion.
While the paper presents promising results, it falls short in addressing important limitations and potential concerns, such as the practical implications, ethical considerations, and the need for more comprehensive evaluation of the generalization capabilities of the proposed method. Addressing these aspects could lead to a more balanced and insightful understanding of the potential benefits and challenges of this technology.
Overall, the paper contributes to the growing field of automated fashion design and synthesis, but further research and critical analysis are needed to fully understand the impact and implications of prompting-based fashion image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automatic Generation of Fashion Images using Prompting in Generative Machine Learning Models
Georgia Argyrou, Angeliki Dimitriou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
The advent of artificial intelligence has contributed in a groundbreaking transformation of the fashion industry, redefining creativity and innovation in unprecedented ways. This work investigates methodologies for generating tailored fashion descriptions using two distinct Large Language Models and a Stable Diffusion model for fashion image creation. Emphasizing adaptability in AI-driven fashion creativity, we depart from traditional approaches and focus on prompting techniques, such as zero-shot and few-shot learning, as well as Chain-of-Thought (CoT), which results in a variety of colors and textures, enhancing the diversity of the outputs. Central to our methodology is Retrieval-Augmented Generation (RAG), enriching models with insights from fashion sources to ensure contemporary representations. Evaluation combines quantitative metrics such as CLIPscore with qualitative human judgment, highlighting strengths in creativity, coherence, and aesthetic appeal across diverse styles. Among the participants, RAG and few-shot learning techniques are preferred for their ability to produce more relevant and appealing fashion descriptions. Our code is provided at https://github.com/georgiarg/AutoFashion.
Read more7/23/2024

0
Prompt2Fashion: An automatically generated fashion dataset
Georgia Argyrou, Angeliki Dimitriou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
Despite the rapid evolution and increasing efficacy of language and vision generative models, there remains a lack of comprehensive datasets that bridge the gap between personalized fashion needs and AI-driven design, limiting the potential for truly inclusive and customized fashion solutions. In this work, we leverage generative models to automatically construct a fashion image dataset tailored to various occasions, styles, and body types as instructed by users. We use different Large Language Models (LLMs) and prompting strategies to offer personalized outfits of high aesthetic quality, detail, and relevance to both expert and non-expert users' requirements, as demonstrated by qualitative analysis. Up until now the evaluation of the generated outfits has been conducted by non-expert human subjects. Despite the provided fine-grained insights on the quality and relevance of generation, we extend the discussion on the importance of expert knowledge for the evaluation of artistic AI-generated datasets such as this one. Our dataset is publicly available on GitHub at https://github.com/georgiarg/Prompt2Fashion.
Read more9/16/2024

0
FashionSD-X: Multimodal Fashion Garment Synthesis using Latent Diffusion
Abhishek Kumar Singh, Ioannis Patras
The rapid evolution of the fashion industry increasingly intersects with technological advancements, particularly through the integration of generative AI. This study introduces a novel generative pipeline designed to transform the fashion design process by employing latent diffusion models. Utilizing ControlNet and LoRA fine-tuning, our approach generates high-quality images from multimodal inputs such as text and sketches. We leverage and enhance state-of-the-art virtual try-on datasets, including Multimodal Dress Code and VITON-HD, by integrating sketch data. Our evaluation, utilizing metrics like FID, CLIP Score, and KID, demonstrates that our model significantly outperforms traditional stable diffusion models. The results not only highlight the effectiveness of our model in generating fashion-appropriate outputs but also underscore the potential of diffusion models in revolutionizing fashion design workflows. This research paves the way for more interactive, personalized, and technologically enriched methodologies in fashion design and representation, bridging the gap between creative vision and practical application.
Read more4/30/2024
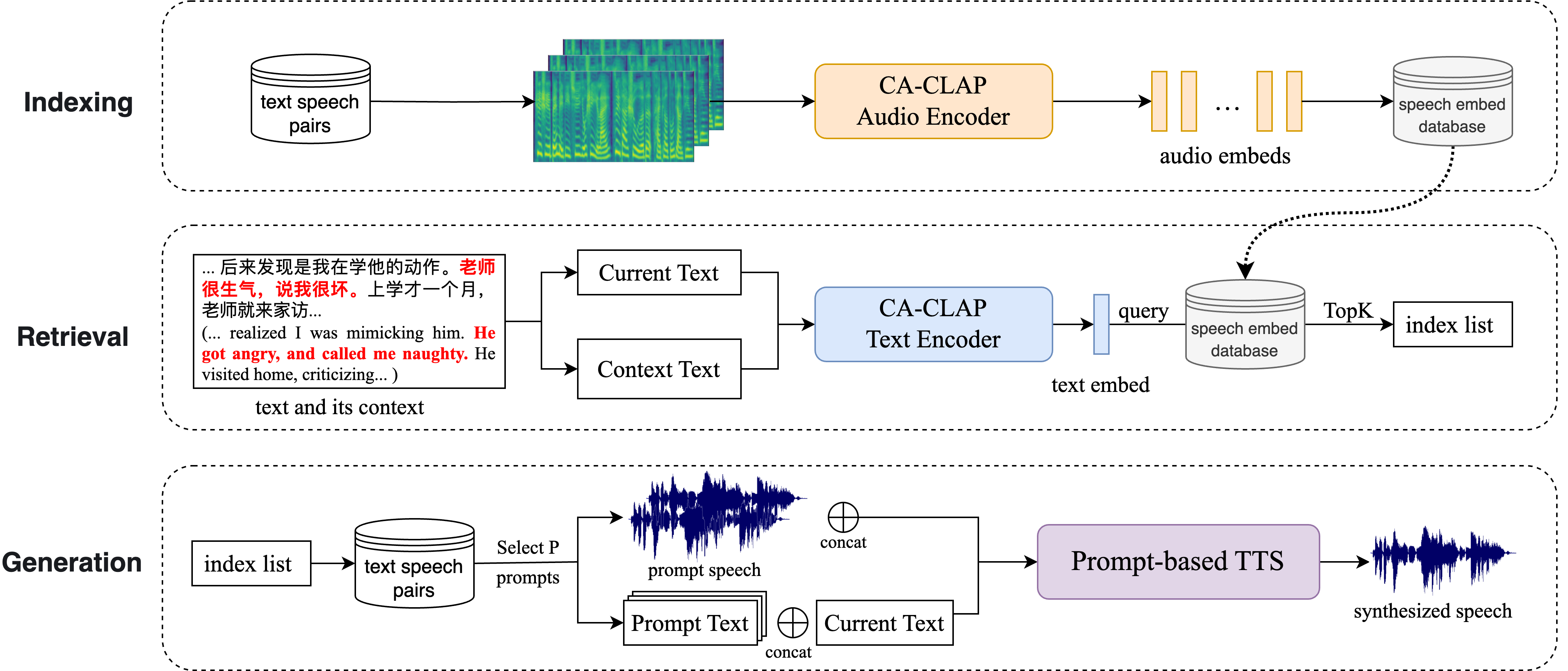
0
Retrieval Augmented Generation in Prompt-based Text-to-Speech Synthesis with Context-Aware Contrastive Language-Audio Pretraining
Jinlong Xue, Yayue Deng, Yingming Gao, Ya Li
Recent prompt-based text-to-speech (TTS) models can clone an unseen speaker using only a short speech prompt. They leverage a strong in-context ability to mimic the speech prompts, including speaker style, prosody, and emotion. Therefore, the selection of a speech prompt greatly influences the generated speech, akin to the importance of a prompt in large language models (LLMs). However, current prompt-based TTS models choose the speech prompt manually or simply at random. Hence, in this paper, we adapt retrieval augmented generation (RAG) from LLMs to prompt-based TTS. Unlike traditional RAG methods, we additionally consider contextual information during the retrieval process and present a Context-Aware Contrastive Language-Audio Pre-training (CA-CLAP) model to extract context-aware, style-related features. The objective and subjective evaluations demonstrate that our proposed RAG method outperforms baselines, and our CA-CLAP achieves better results than text-only retrieval methods.
Read more6/7/2024