Retrieval Augmented Generation in Prompt-based Text-to-Speech Synthesis with Context-Aware Contrastive Language-Audio Pretraining

0
Sign in to get full access
Overview
- This paper proposes a new approach for text-to-speech (TTS) synthesis that combines retrieval-augmented generation with context-aware contrastive language-audio pretraining.
- The key idea is to leverage relevant information from a large database of text-audio pairs to improve the quality and naturalness of the generated speech.
- The method involves retrieving relevant text-audio examples from the database and using them to condition the TTS model, guided by a contrastive language-audio pretraining objective.
Plain English Explanation
In this paper, the researchers developed a new way to generate high-quality, natural-sounding speech from text. The core insight is to use a large database of text and audio examples to help the speech synthesis model do its job better.
The way it works is: when the model needs to generate speech from some input text, it first searches through the database to find relevant text-audio pairs. It then uses those relevant examples to "condition" or guide the speech generation process, helping it produce more natural-sounding output.
The researchers also used a special training technique called "contrastive language-audio pretraining" to teach the model how to better connect the text and audio information. This allows the model to make more informed decisions when selecting which text-audio examples to use for the speech synthesis task.
The key benefit of this approach is that it can produce more realistic and expressive speech, by leveraging the wealth of information contained in the large text-audio database. This could be very useful for applications like virtual assistants, audiobook narration, or text-to-speech systems that need to sound more natural and human-like.
Technical Explanation
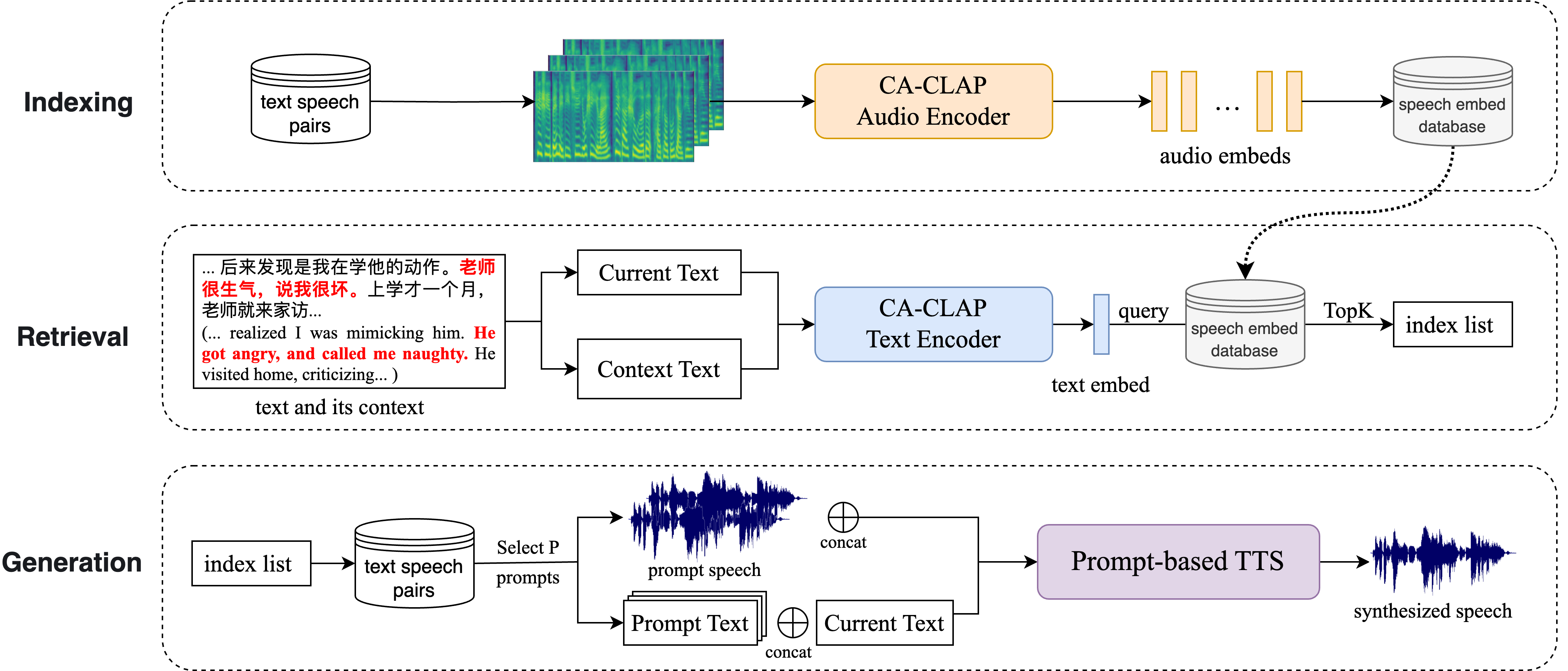
The paper introduces a Retrieval Augmented Generation (RAG) approach for text-to-speech (TTS) synthesis, where the TTS model is conditioned on relevant text-audio examples retrieved from a large database.
The core components are:
- A text encoder and audio encoder that learn to map text and audio into a shared embedding space through contrastive language-audio pretraining.
- A retrieval module that finds the most relevant text-audio pairs from the database given the input text.
- A TTS generation module that combines the input text and the retrieved text-audio examples to produce the final speech output.
The key innovation is the use of context-aware retrieval and collaborative retrieval techniques to select the most relevant examples from the database. This allows the model to better leverage the available information and generate more natural-sounding speech.
The experiments show that this retrieval-augmented approach outperforms traditional TTS models on various objective and subjective metrics, demonstrating the benefits of incorporating relevant text-audio examples into the speech synthesis process.
Critical Analysis
The paper presents a promising approach for improving the quality and naturalness of text-to-speech synthesis. The key strength is the ability to leverage a large database of text-audio pairs to guide the speech generation process, which helps overcome the limitations of traditional TTS models that rely solely on the input text.
However, the paper does not address some potential limitations and areas for further research:
- The size and quality of the text-audio database can have a significant impact on the performance, and the authors don't provide much detail on how the database was constructed and curated.
- The paper focuses on English language TTS, but it's unclear how well the approach would generalize to other languages or domains.
- The computational and memory overhead of the retrieval-augmented architecture is not discussed, which could be an important practical consideration for real-world deployment.
Additionally, while the paper demonstrates the effectiveness of the proposed approach, it would be valuable to see more in-depth analysis or ablation studies to better understand the specific contributions of the different components (e.g., the role of contrastive pretraining, the impact of different retrieval strategies, etc.).
Conclusion
This paper presents a novel approach for text-to-speech synthesis that combines retrieval-augmented generation with context-aware contrastive language-audio pretraining. By leveraging relevant text-audio examples from a large database, the model is able to generate more natural-sounding and expressive speech compared to traditional TTS systems.
The key innovation is the use of advanced retrieval techniques to select the most relevant text-audio pairs to condition the speech generation process. This allows the model to better leverage the available information and produce higher-quality output.
The findings of this research have important implications for the development of more human-like and engaging text-to-speech systems, which could benefit a wide range of applications, from virtual assistants to audiobook narration. As the field of speech synthesis continues to advance, techniques like the one presented in this paper will play an increasingly important role in delivering a more natural and immersive user experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retrieval Augmented Generation in Prompt-based Text-to-Speech Synthesis with Context-Aware Contrastive Language-Audio Pretraining
Jinlong Xue, Yayue Deng, Yingming Gao, Ya Li
Recent prompt-based text-to-speech (TTS) models can clone an unseen speaker using only a short speech prompt. They leverage a strong in-context ability to mimic the speech prompts, including speaker style, prosody, and emotion. Therefore, the selection of a speech prompt greatly influences the generated speech, akin to the importance of a prompt in large language models (LLMs). However, current prompt-based TTS models choose the speech prompt manually or simply at random. Hence, in this paper, we adapt retrieval augmented generation (RAG) from LLMs to prompt-based TTS. Unlike traditional RAG methods, we additionally consider contextual information during the retrieval process and present a Context-Aware Contrastive Language-Audio Pre-training (CA-CLAP) model to extract context-aware, style-related features. The objective and subjective evaluations demonstrate that our proposed RAG method outperforms baselines, and our CA-CLAP achieves better results than text-only retrieval methods.
Read more6/7/2024
🛸
0
Prompt Perturbation in Retrieval-Augmented Generation based Large Language Models
Zhibo Hu (Hye-Young), Chen Wang (Hye-Young), Yanfeng Shu (Hye-Young), Helen (Hye-Young), Paik, Liming Zhu
The robustness of large language models (LLMs) becomes increasingly important as their use rapidly grows in a wide range of domains. Retrieval-Augmented Generation (RAG) is considered as a means to improve the trustworthiness of text generation from LLMs. However, how the outputs from RAG-based LLMs are affected by slightly different inputs is not well studied. In this work, we find that the insertion of even a short prefix to the prompt leads to the generation of outputs far away from factually correct answers. We systematically evaluate the effect of such prefixes on RAG by introducing a novel optimization technique called Gradient Guided Prompt Perturbation (GGPP). GGPP achieves a high success rate in steering outputs of RAG-based LLMs to targeted wrong answers. It can also cope with instructions in the prompts requesting to ignore irrelevant context. We also exploit LLMs' neuron activation difference between prompts with and without GGPP perturbations to give a method that improves the robustness of RAG-based LLMs through a highly effective detector trained on neuron activation triggered by GGPP generated prompts. Our evaluation on open-sourced LLMs demonstrates the effectiveness of our methods.
Read more7/25/2024

0
Adaptive Retrieval-Augmented Generation for Conversational Systems
Xi Wang, Procheta Sen, Ruizhe Li, Emine Yilmaz
Despite the success of integrating large language models into the development of conversational systems, many studies have shown the effectiveness of retrieving and augmenting external knowledge for informative responses. Hence, many existing studies commonly assume the always need for Retrieval Augmented Generation (RAG) in a conversational system without explicit control. This raises a research question about such a necessity. In this study, we propose to investigate the need for each turn of system response to be augmented with external knowledge. In particular, by leveraging human judgements on the binary choice of adaptive augmentation, we develop RAGate, a gating model, which models conversation context and relevant inputs to predict if a conversational system requires RAG for improved responses. We conduct extensive experiments on devising and applying RAGate to conversational models and well-rounded analyses of different conversational scenarios. Our experimental results and analysis indicate the effective application of RAGate in RAG-based conversational systems in identifying system responses for appropriate RAG with high-quality responses and a high generation confidence. This study also identifies the correlation between the generation's confidence level and the relevance of the augmented knowledge.
Read more8/1/2024

0
New!LA-RAG:Enhancing LLM-based ASR Accuracy with Retrieval-Augmented Generation
Shaojun Li, Hengchao Shang, Daimeng Wei, Jiaxin Guo, Zongyao Li, Xianghui He, Min Zhang, Hao Yang
Recent advancements in integrating speech information into large language models (LLMs) have significantly improved automatic speech recognition (ASR) accuracy. However, existing methods often constrained by the capabilities of the speech encoders under varied acoustic conditions, such as accents. To address this, we propose LA-RAG, a novel Retrieval-Augmented Generation (RAG) paradigm for LLM-based ASR. LA-RAG leverages fine-grained token-level speech datastores and a speech-to-speech retrieval mechanism to enhance ASR accuracy via LLM in-context learning (ICL) capabilities. Experiments on Mandarin and various Chinese dialect datasets demonstrate significant improvements in ASR accuracy compared to existing methods, validating the effectiveness of our approach, especially in handling accent variations.
Read more9/16/2024