Automatic Graph Topology-Aware Transformer
2405.19779
0
0
Abstract
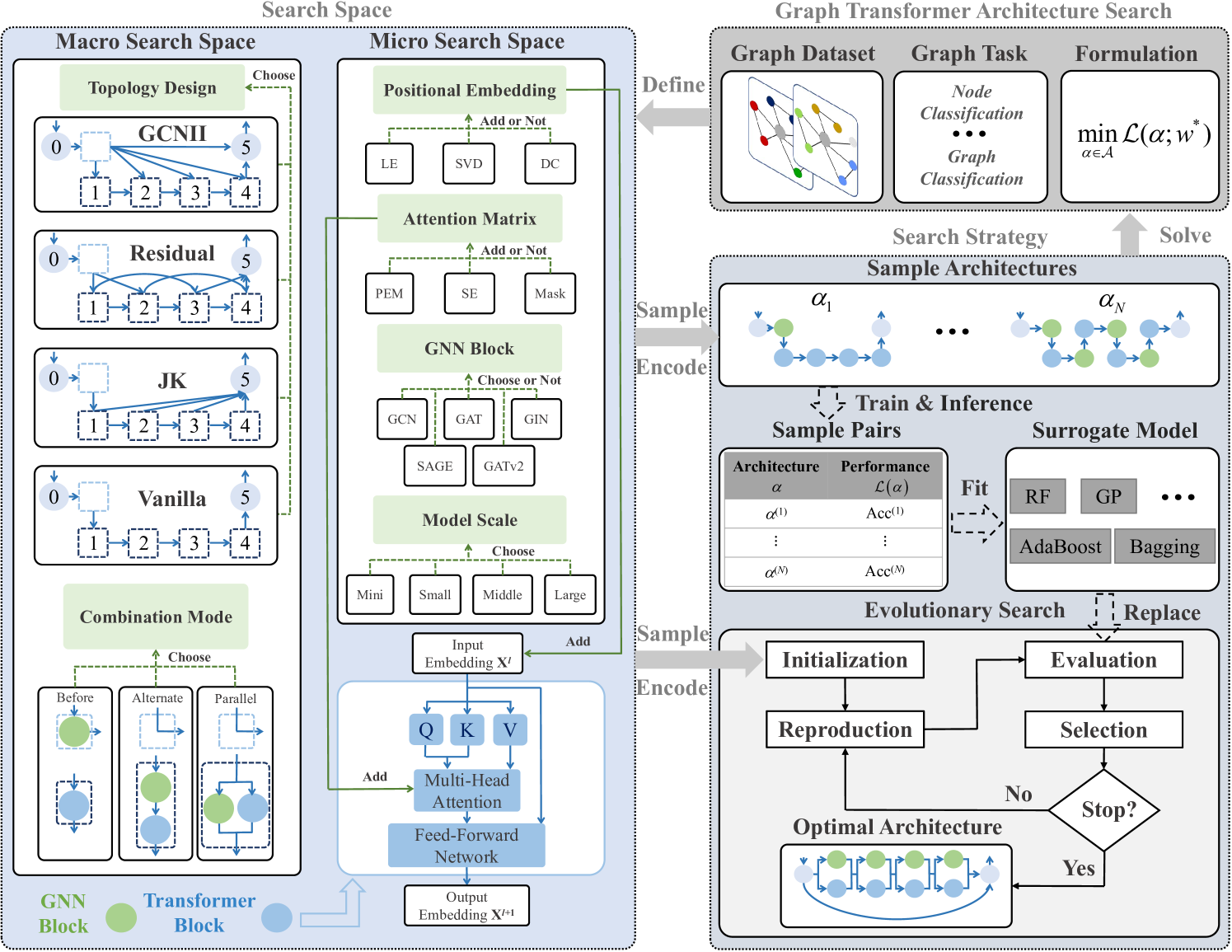
Existing efforts are dedicated to designing many topologies and graph-aware strategies for the graph Transformer, which greatly improve the model's representation capabilities. However, manually determining the suitable Transformer architecture for a specific graph dataset or task requires extensive expert knowledge and laborious trials. This paper proposes an evolutionary graph Transformer architecture search framework (EGTAS) to automate the construction of strong graph Transformers. We build a comprehensive graph Transformer search space with the micro-level and macro-level designs. EGTAS evolves graph Transformer topologies at the macro level and graph-aware strategies at the micro level. Furthermore, a surrogate model based on generic architectural coding is proposed to directly predict the performance of graph Transformers, substantially reducing the evaluation cost of evolutionary search. We demonstrate the efficacy of EGTAS across a range of graph-level and node-level tasks, encompassing both small-scale and large-scale graph datasets. Experimental results and ablation studies show that EGTAS can construct high-performance architectures that rival state-of-the-art manual and automated baselines.
Create account to get full access
Overview
- Proposes a novel Graph Topology-Aware Transformer (GTAT) model for graph-based neural architecture search and performance prediction tasks
- Leverages graph neural networks to capture the structural information of computational graphs
- Aims to automatically design efficient neural network architectures by considering the underlying graph topology
Plain English Explanation
The paper introduces the Graph Topology-Aware Transformer (GTAT), a new model that can help design efficient neural network architectures. Neural networks are complex mathematical models that are used in many AI applications, such as image recognition and language processing. The design of these neural networks is often a challenging task, as there are many possible architectural choices to consider.
The key insight behind GTAT is that the structure or "topology" of the computational graph underlying a neural network can provide important information about its performance. Attending to Graph Transformers and Towards Principled Graph Transformers have also explored using graph-based approaches for neural network design.
GTAT uses graph neural networks, a type of machine learning model that can capture the relationships between the different components of a computational graph. By considering this structural information, GTAT can help automatically design neural network architectures that are more efficient and effective for a given task. This could be particularly useful for applications where the optimal neural network architecture is not known in advance, such as in Topology-Guided Hypergraph Transformer Network: Unveiling Structural Importance or FairGT: Fairness-Aware Graph Transformer.
The researchers demonstrate the effectiveness of GTAT on several benchmark tasks, showing that it can outperform other state-of-the-art methods for neural architecture search and performance prediction. This suggests that incorporating graph-based structural information can be a powerful approach for designing efficient and high-performing neural networks.
Technical Explanation
The core idea behind the Graph Topology-Aware Transformer (GTAT) is to leverage the structural information of the computational graph underlying a neural network architecture to improve the performance of neural architecture search (NAS) and performance prediction tasks.
The authors first represent the neural network architecture as a directed acyclic graph (DAG), where the nodes correspond to the layers or operations, and the edges represent the connections between them. They then propose a graph neural network-based encoder to capture the topological information of this computational graph.
The encoder consists of multiple graph attention layers, which allow the model to learn the relative importance of different graph nodes and edges. This graph-aware encoding is then used as input to a transformer-based decoder, which predicts the performance of the neural network architecture or generates a new architecture via a reinforcement learning-based NAS approach.
The authors evaluate GTAT on several benchmark tasks, including NAS on the DARTS search space and performance prediction on the NAS-Bench-201 and NAS-Bench-1Shot1 datasets. The results show that GTAT outperforms other state-of-the-art methods, demonstrating the value of incorporating graph-based structural information for these tasks.
The authors also discuss the potential limitations of their approach, such as the computational overhead of the graph neural network encoder and the need for further research to extend GTAT to handle more complex graph structures, such as those found in EATFormer: Improving Vision Transformer Inspired by Evolutionary.
Critical Analysis
The key strength of the GTAT model is its ability to leverage the structural information of the computational graph underlying a neural network architecture, which previous approaches have largely overlooked. By capturing the relative importance of different graph nodes and edges, GTAT can make more informed decisions about architecture design and performance prediction.
One potential limitation of the GTAT model is the computational overhead introduced by the graph neural network encoder. While the authors demonstrate that GTAT outperforms other methods on the benchmark tasks, the additional complexity of the model may make it less practical for certain real-world applications with strict computational constraints.
Additionally, the authors note that GTAT is currently limited to handling directed acyclic graphs, which may not be sufficient to capture the full complexity of neural network architectures, especially as the field continues to explore more advanced designs like those in Topology-Guided Hypergraph Transformer Network: Unveiling Structural and FairGT: Fairness-Aware Graph Transformer. Further research may be needed to extend GTAT to handle more general graph structures.
Overall, the GTAT model represents an exciting step forward in incorporating graph-based structural information for neural architecture search and performance prediction, and the authors have provided a solid foundation for future work in this direction.
Conclusion
The Graph Topology-Aware Transformer (GTAT) proposed in this paper is a novel approach to leveraging the structural information of computational graphs for neural architecture search and performance prediction tasks. By using a graph neural network encoder to capture the relative importance of different graph nodes and edges, GTAT can make more informed decisions about the design of efficient and high-performing neural network architectures.
The authors demonstrate the effectiveness of GTAT on several benchmark tasks, showcasing its ability to outperform other state-of-the-art methods. This suggests that incorporating graph-based structural information can be a powerful approach for automating the design of neural networks, which could have significant implications for a wide range of AI applications.
While the GTAT model has some limitations, such as the computational overhead of the graph neural network encoder and the current restriction to directed acyclic graphs, the authors have laid the groundwork for further research in this promising direction. As the field of neural architecture search continues to evolve, approaches like GTAT that can capture the underlying structural information of computational graphs are likely to play an increasingly important role in the development of efficient and high-performing neural network models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Attending to Graph Transformers
Luis Muller, Mikhail Galkin, Christopher Morris, Ladislav Ramp'av{s}ek
0
0
Recently, transformer architectures for graphs emerged as an alternative to established techniques for machine learning with graphs, such as (message-passing) graph neural networks. So far, they have shown promising empirical results, e.g., on molecular prediction datasets, often attributed to their ability to circumvent graph neural networks' shortcomings, such as over-smoothing and over-squashing. Here, we derive a taxonomy of graph transformer architectures, bringing some order to this emerging field. We overview their theoretical properties, survey structural and positional encodings, and discuss extensions for important graph classes, e.g., 3D molecular graphs. Empirically, we probe how well graph transformers can recover various graph properties, how well they can deal with heterophilic graphs, and to what extent they prevent over-squashing. Further, we outline open challenges and research direction to stimulate future work. Our code is available at https://github.com/luis-mueller/probing-graph-transformers.
4/1/2024

Towards Principled Graph Transformers
Luis Muller, Daniel Kusuma, Blai Bonet, Christopher Morris
0
0
Graph learning architectures based on the k-dimensional Weisfeiler-Leman (k-WL) hierarchy offer a theoretically well-understood expressive power. However, such architectures often fail to deliver solid predictive performance on real-world tasks, limiting their practical impact. In contrast, global attention-based models such as graph transformers demonstrate strong performance in practice, but comparing their expressive power with the k-WL hierarchy remains challenging, particularly since these architectures rely on positional or structural encodings for their expressivity and predictive performance. To address this, we show that the recently proposed Edge Transformer, a global attention model operating on node pairs instead of nodes, has at least 3-WL expressive power. Empirically, we demonstrate that the Edge Transformer surpasses other theoretically aligned architectures regarding predictive performance while not relying on positional or structural encodings. Our code is available at https://github.com/luis-mueller/towards-principled-gts
5/27/2024
🛸
Gransformer: Transformer-based Graph Generation
Ahmad Khajenezhad, Seyed Ali Osia, Mahmood Karimian, Hamid Beigy
0
0
Transformers have become widely used in various tasks, such as natural language processing and machine vision. This paper proposes Gransformer, an algorithm based on Transformer for generating graphs. We modify the Transformer encoder to exploit the structural information of the given graph. The attention mechanism is adapted to consider the presence or absence of edges between each pair of nodes. We also introduce a graph-based familiarity measure between node pairs that applies to both the attention and the positional encoding. This measure of familiarity is based on message-passing algorithms and contains structural information about the graph. Also, this measure is autoregressive, which allows our model to acquire the necessary conditional probabilities in a single forward pass. In the output layer, we also use a masked autoencoder for density estimation to efficiently model the sequential generation of dependent edges connected to each node. In addition, we propose a technique to prevent the model from generating isolated nodes without connection to preceding nodes by using BFS node orderings. We evaluate this method using synthetic and real-world datasets and compare it with related ones, including recurrent models and graph convolutional networks. Experimental results show that the proposed method performs comparatively to these methods.
6/3/2024

Hypergraph Transformer for Semi-Supervised Classification
Zexi Liu, Bohan Tang, Ziyuan Ye, Xiaowen Dong, Siheng Chen, Yanfeng Wang
0
0
Hypergraphs play a pivotal role in the modelling of data featuring higher-order relations involving more than two entities. Hypergraph neural networks emerge as a powerful tool for processing hypergraph-structured data, delivering remarkable performance across various tasks, e.g., hypergraph node classification. However, these models struggle to capture global structural information due to their reliance on local message passing. To address this challenge, we propose a novel hypergraph learning framework, HyperGraph Transformer (HyperGT). HyperGT uses a Transformer-based neural network architecture to effectively consider global correlations among all nodes and hyperedges. To incorporate local structural information, HyperGT has two distinct designs: i) a positional encoding based on the hypergraph incidence matrix, offering valuable insights into node-node and hyperedge-hyperedge interactions; and ii) a hypergraph structure regularization in the loss function, capturing connectivities between nodes and hyperedges. Through these designs, HyperGT achieves comprehensive hypergraph representation learning by effectively incorporating global interactions while preserving local connectivity patterns. Extensive experiments conducted on real-world hypergraph node classification tasks showcase that HyperGT consistently outperforms existing methods, establishing new state-of-the-art benchmarks. Ablation studies affirm the effectiveness of the individual designs of our model.
6/4/2024