Automatic Programming: Large Language Models and Beyond
2405.02213
0
0
💬
Abstract
Automatic programming has seen increasing popularity due to the emergence of tools like GitHub Copilot which rely on Large Language Models (LLMs). At the same time, automatically generated code faces challenges during deployment due to concerns around quality and trust. In this article, we study automated coding in a general sense and study the concerns around code quality, security and related issues of programmer responsibility. These are key issues for organizations while deciding on the usage of automatically generated code. We discuss how advances in software engineering such as program repair and analysis can enable automatic programming. We conclude with a forward looking view, focusing on the programming environment of the near future, where programmers may need to switch to different roles to fully utilize the power of automatic programming. Automated repair of automatically generated programs from LLMs, can help produce higher assurance code from LLMs, along with evidence of assurance
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores the challenges and opportunities surrounding the use of automatically generated code, particularly in the context of large language models (LLMs) like GitHub Copilot.
- It discusses the concerns around code quality, security, and programmer responsibility when it comes to the deployment of automatically generated code.
- The paper also examines how advancements in software engineering, such as program repair and analysis, can enable and improve automatic programming.
- The authors provide a forward-looking perspective, suggesting that programmers may need to adapt their roles to fully leverage the power of automatic programming in the near future.
Plain English Explanation
As tools like GitHub Copilot that use large language models (LLMs) become more popular, the practice of automatic programming is gaining traction. Automatic programming refers to the ability of these tools to generate code automatically, without requiring a human programmer to write it from scratch.
While this technology holds a lot of promise, there are also concerns about the quality and trustworthiness of the code that is automatically generated. Organizations considering the use of automatically generated code need to carefully weigh the potential benefits against the risks, such as security vulnerabilities and issues with code reliability.
The paper discusses how advancements in software engineering, like program repair and program analysis, can help address these concerns and enable more effective automatic programming. These techniques can help improve the quality and security of automatically generated code, increasing its viability for real-world use.
Looking to the future, the authors suggest that programmers may need to adapt their roles and responsibilities to make the most of automatic programming. Instead of writing code from scratch, programmers may need to focus more on tasks like overseeing the automatic generation of code, verifying its quality, and ensuring it meets the necessary requirements.
Technical Explanation
The paper explores the challenges and opportunities surrounding the use of automatically generated code, particularly in the context of large language models (LLMs) like GitHub Copilot. The authors discuss the key concerns around code quality, security, and programmer responsibility when it comes to the deployment of automatically generated code.
The paper examines how advancements in software engineering, such as program repair and program analysis, can enable and improve automatic programming. These techniques can help address the quality and security issues that arise with automatically generated code, making it more viable for real-world use.
The authors also provide a forward-looking perspective, suggesting that programmers may need to adapt their roles and responsibilities to fully leverage the power of automatic programming in the near future. Instead of writing code from scratch, programmers may need to focus more on tasks like overseeing the automatic generation of code, verifying its quality, and ensuring it meets the necessary requirements.
Critical Analysis
The paper raises valid concerns about the potential challenges of deploying automatically generated code, particularly around issues of quality, security, and programmer responsibility. The authors rightly point out that organizations need to carefully consider these factors when deciding whether to adopt automatic programming tools like GitHub Copilot.
While the paper discusses potential solutions, such as advancements in program repair and program analysis, it does not provide a comprehensive evaluation of their effectiveness or limitations. Additionally, the authors' suggestion that programmers may need to adapt their roles in the near future could benefit from a more in-depth analysis of the potential implications for the software development workforce.
It would also be valuable for the paper to explore the broader societal and ethical implications of the widespread adoption of automatic programming, such as the impact on employment in the software industry and the potential for bias or discrimination in the code generated by LLMs.
Conclusion
The paper highlights the significant opportunities and challenges presented by the rise of automatic programming, particularly in the context of large language models like GitHub Copilot. While the technology has the potential to revolutionize software development, it also raises serious concerns about code quality, security, and programmer responsibility.
The authors suggest that advancements in software engineering, such as program repair and analysis, can help address these concerns and enable more effective automatic programming. Additionally, they foresee that programmers may need to adapt their roles and responsibilities to fully leverage the power of this technology in the near future.
Overall, the paper provides a thoughtful and nuanced exploration of the complex issues surrounding automatic programming, highlighting the need for continued research and careful consideration as this technology continues to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models Synergize with Automated Machine Learning
Jinglue Xu, Jialong Li, Zhen Liu, Nagar Anthel Venkatesh Suryanarayanan, Guoyuan Zhou, Jia Guo, Hitoshi Iba, Kenji Tei
0
0
Recently, program synthesis driven by large language models (LLMs) has become increasingly popular. However, program synthesis for machine learning (ML) tasks still poses significant challenges. This paper explores a novel form of program synthesis, targeting ML programs, by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the generation and optimization of the code of the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To ensure compatibilities, we design a testing technique for ML programs. Unlike traditional program synthesis, which typically relies on binary evaluations (i.e., correct or incorrect), evaluating ML programs necessitates more than just binary judgments. Therefore, we further assess ML programs numerically and select the optimal programs from a range of candidates using AutoML methods. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In experiments, given the textual task description, our method, Text-to-ML, generates the complete and optimized ML program in a fully autonomous process.
5/14/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024
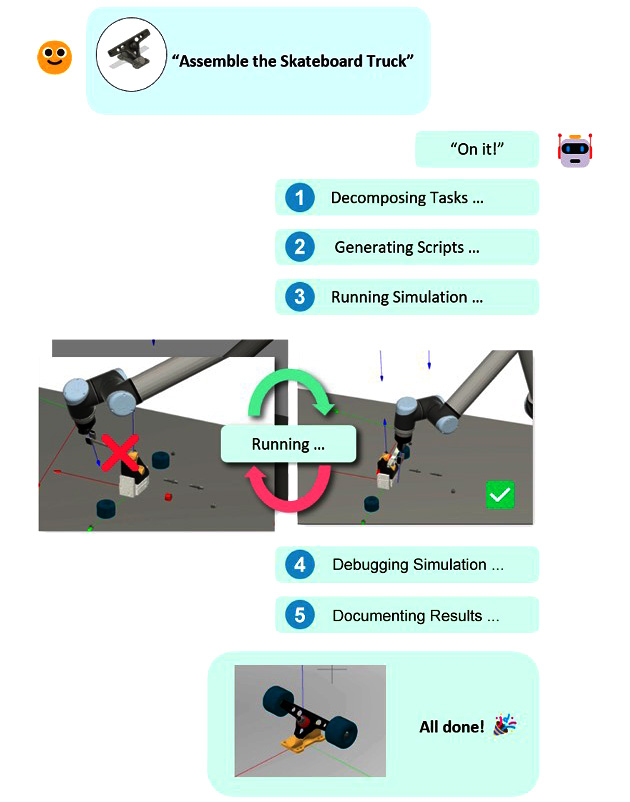
Toward Automated Programming for Robotic Assembly Using ChatGPT
Annabella Macaluso, Nicholas Cote, Sachin Chitta
0
0
Despite significant technological advancements, the process of programming robots for adaptive assembly remains labor-intensive, demanding expertise in multiple domains and often resulting in task-specific, inflexible code. This work explores the potential of Large Language Models (LLMs), like ChatGPT, to automate this process, leveraging their ability to understand natural language instructions, generalize examples to new tasks, and write code. In this paper, we suggest how these abilities can be harnessed and applied to real-world challenges in the manufacturing industry. We present a novel system that uses ChatGPT to automate the process of programming robots for adaptive assembly by decomposing complex tasks into simpler subtasks, generating robot control code, executing the code in a simulated workcell, and debugging syntax and control errors, such as collisions. We outline the architecture of this system and strategies for task decomposition and code generation. Finally, we demonstrate how our system can autonomously program robots for various assembly tasks in a real-world project.
5/15/2024
🌐
Automated Program Repair: Emerging trends pose and expose problems for benchmarks
Joseph Renzullo, Pemma Reiter, Westley Weimer, Stephanie Forrest
0
0
Machine learning (ML) now pervades the field of Automated Program Repair (APR). Algorithms deploy neural machine translation and large language models (LLMs) to generate software patches, among other tasks. But, there are important differences between these applications of ML and earlier work. Evaluations and comparisons must take care to ensure that results are valid and likely to generalize. A challenge is that the most popular APR evaluation benchmarks were not designed with ML techniques in mind. This is especially true for LLMs, whose large and often poorly-disclosed training datasets may include problems on which they are evaluated.
5/10/2024