Large Language Models Synergize with Automated Machine Learning
2405.03727
0
0

Abstract
Recently, program synthesis driven by large language models (LLMs) has become increasingly popular. However, program synthesis for machine learning (ML) tasks still poses significant challenges. This paper explores a novel form of program synthesis, targeting ML programs, by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the generation and optimization of the code of the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To ensure compatibilities, we design a testing technique for ML programs. Unlike traditional program synthesis, which typically relies on binary evaluations (i.e., correct or incorrect), evaluating ML programs necessitates more than just binary judgments. Therefore, we further assess ML programs numerically and select the optimal programs from a range of candidates using AutoML methods. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In experiments, given the textual task description, our method, Text-to-ML, generates the complete and optimized ML program in a fully autonomous process.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the synergies between large language models (LLMs) and automated machine learning (AutoML) techniques.
- The authors investigate how LLMs can be leveraged to enhance AutoML pipelines, and how AutoML can be used to improve the performance and capabilities of LLMs.
- Key contributions include integrating LLMs into AutoML workflows, using LLMs for data augmentation, and automating research synthesis with LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, understand natural language, and perform a wide variety of language-related tasks. Automated machine learning (AutoML) is a field that aims to automate the process of building and optimizing machine learning models, making it more accessible to non-experts.
This paper looks at how these two technologies can work together to create more powerful and efficient AI systems. The authors explore ways to integrate LLMs into AutoML workflows, allowing the language understanding and generation capabilities of LLMs to enhance the machine learning process. For example, they demonstrate how LLMs can be used for data augmentation, generating new training data to improve the performance of machine learning models.
The paper also shows how AutoML can be used to optimize the performance of LLMs, automating the process of fine-tuning and adapting these powerful language models to specific tasks and domains. Additionally, the authors explore using LLMs to automate the synthesis of research, helping researchers quickly identify relevant studies and insights.
Overall, this work highlights the potential for LLMs and AutoML to complement each other, creating AI systems that are more capable, efficient, and accessible than either technology on its own.
Technical Explanation
The paper begins by outlining the key challenges and motivations driving the integration of large language models (LLMs) and automated machine learning (AutoML) techniques. The authors note that while LLMs have shown impressive capabilities in a range of language-related tasks, they can be computationally expensive and time-consuming to fine-tune and adapt to specific domains. Conversely, while AutoML can streamline the machine learning process, it may struggle with tasks that require strong language understanding and generation abilities.
To address these challenges, the authors propose several approaches for synergizing LLMs and AutoML. One key contribution is the integration of LLMs into AutoML workflows, allowing the language understanding and generation capabilities of LLMs to enhance the automated machine learning process. The authors demonstrate how LLMs can be used for data augmentation, generating new training data to improve the performance of machine learning models.
The paper also explores how AutoML can be used to optimize the performance of LLMs, automating the process of fine-tuning and adapting these powerful language models to specific tasks and domains. Additionally, the authors present a framework for using LLMs to automate the synthesis of research, helping researchers quickly identify relevant studies and insights.
Through a series of experiments and case studies, the authors demonstrate the effectiveness of their proposed approaches, showing how LLMs and AutoML can work together to create more powerful and efficient AI systems.
Critical Analysis
The paper presents a compelling case for the synergistic integration of large language models (LLMs) and automated machine learning (AutoML) techniques. The authors provide a thorough exploration of the key challenges and motivations driving this research, and their proposed approaches offer promising solutions.
However, the paper does not fully address some potential limitations and caveats. For example, the authors acknowledge that fine-tuning and adapting LLMs can be computationally expensive, and it is not clear how their AutoML-based optimization techniques would scale to the most powerful and complex LLMs currently available.
Additionally, the paper does not delve deeply into the potential ethical and societal implications of these technologies. As LLMs and AutoML become more powerful and ubiquitous, there will be important questions to consider around issues such as bias, privacy, and the impact on jobs and the workforce.
Further research is needed to fully understand the long-term implications of these technologies and to explore additional ways to make them more accessible, reliable, and beneficial to society. Nonetheless, this paper represents an important step forward in the ongoing effort to harness the power of LLMs and AutoML to solve complex problems and drive innovation.
Conclusion
This paper presents a compelling vision for the synergistic integration of large language models (LLMs) and automated machine learning (AutoML) techniques. By leveraging the complementary strengths of these two technologies, the authors demonstrate how they can create more powerful and efficient AI systems capable of tackling a wide range of language-related tasks.
The key contributions of this work include integrating LLMs into AutoML workflows, using LLMs for data augmentation, and automating research synthesis with LLMs. These approaches show how the language understanding and generation capabilities of LLMs can enhance the machine learning process, while AutoML can be used to optimize the performance of LLMs.
As the fields of LLMs and AutoML continue to evolve, this research highlights the potential for these technologies to work together to drive innovation and solve complex problems. However, it also raises important questions about the ethical and societal implications of these powerful AI systems, which will need to be carefully considered in future research and development efforts.
Overall, this paper represents an exciting step forward in the quest to unlock the full potential of large language models and automated machine learning, and it will undoubtedly inspire further exploration and collaboration in this rapidly advancing field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Automatic Programming: Large Language Models and Beyond
Michael R. Lyu, Baishakhi Ray, Abhik Roychoudhury, Shin Hwei Tan, Patanamon Thongtanunam
0
0
Automatic programming has seen increasing popularity due to the emergence of tools like GitHub Copilot which rely on Large Language Models (LLMs). At the same time, automatically generated code faces challenges during deployment due to concerns around quality and trust. In this article, we study automated coding in a general sense and study the concerns around code quality, security and related issues of programmer responsibility. These are key issues for organizations while deciding on the usage of automatically generated code. We discuss how advances in software engineering such as program repair and analysis can enable automatic programming. We conclude with a forward looking view, focusing on the programming environment of the near future, where programmers may need to switch to different roles to fully utilize the power of automatic programming. Automated repair of automatically generated programs from LLMs, can help produce higher assurance code from LLMs, along with evidence of assurance
5/16/2024
💬
Exploring and Unleashing the Power of Large Language Models in Automated Code Translation
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, Ge Li
0
0
Code translation tools (transpilers) are developed for automatic source-to-source translation. Although learning-based transpilers have shown impressive enhancement against rule-based counterparts, owing to their task-specific pre-training on extensive monolingual corpora. Their current performance still remains unsatisfactory for practical deployment, and the associated training resources are also prohibitively expensive. LLMs pre-trained on huge amounts of human-written code/text have shown remarkable performance in many code intelligence tasks due to their powerful generality, even without task-specific training. Thus, LLMs can potentially circumvent the above limitations, but they have not been exhaustively explored yet. This paper investigates diverse LLMs and learning-based transpilers for automated code translation tasks, finding that: although certain LLMs have outperformed current transpilers, they still have some accuracy issues, where most of the failures are induced by a lack of comprehension of source programs, missing clear instructions on I/O types in translation, and ignoring discrepancies between source and target programs. Enlightened by the above findings, we further propose UniTrans, a Unified code Translation framework, applicable to various LLMs, for unleashing their power in this field. Specifically, UniTrans first crafts a series of test cases for target programs with the assistance of source programs. Next, it harnesses the above auto-generated test cases to augment the code translation and then evaluate their correctness via execution. Afterward, UniTrans further (iteratively) repairs incorrectly translated programs prompted by test case execution results. Extensive experiments are conducted on six settings of translation datasets between Python, Java, and C++. Three recent LLMs of diverse sizes are tested with UniTrans, and all achieve substantial improvements.
5/14/2024
Lemur: Integrating Large Language Models in Automated Program Verification
Haoze Wu, Clark Barrett, Nina Narodytska
0
0
The demonstrated code-understanding capability of LLMs raises the question of whether they can be used for automated program verification, a task that demands high-level abstract reasoning about program properties that is challenging for verification tools. We propose a general methodology to combine the power of LLMs and automated reasoners for automated program verification. We formally describe this methodology as a set of transition rules and prove its soundness. We instantiate the calculus as a sound automated verification procedure and demonstrate practical improvements on a set of synthetic and competition benchmarks.
4/26/2024
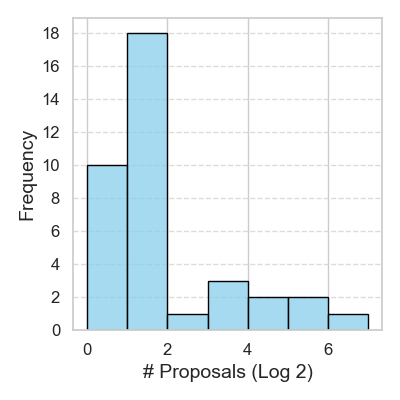
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024