Performant ASR Models for Medical Entities in Accented Speech
2406.12387
0
0
Abstract
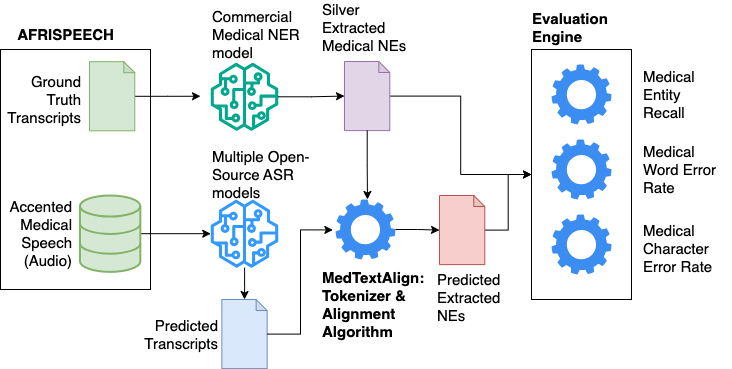
Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
Create account to get full access
Overview
- This paper focuses on developing performant Automatic Speech Recognition (ASR) models for medical entities in accented speech.
- The researchers address the challenge of accurately transcribing medical terms spoken with accents, which is crucial for clinical applications.
- They explore various techniques, including data augmentation, transfer learning, and specialized modeling approaches, to improve ASR performance on accented medical speech.
Plain English Explanation
The paper aims to create speech recognition models that can accurately transcribe medical terms even when they are spoken with different accents. This is important for medical applications, where accurate transcription of medical information is crucial. The researchers try different techniques to improve the performance of the speech recognition models on accented speech, such as using additional data to train the models and adapting the models to specialize in recognizing medical terms.
Technical Explanation
The paper investigates methods to build performant ASR models for medical entities in accented speech. The researchers explore techniques like data augmentation, transfer learning, and specialized modeling approaches to improve ASR performance on accented medical speech. They evaluate their models on datasets containing speech samples with various accents and medical terminology.
Critical Analysis
The paper acknowledges the limitations of the study, such as the challenges of obtaining diverse and representative datasets for accented medical speech. The researchers suggest that further research is needed to explore the generalization of their techniques to broader medical vocabulary and more diverse accents. Additionally, the impact of these models on real-world clinical applications could be further investigated.
Conclusion
This paper presents an important step towards developing robust and accurate ASR models for medical entities in accented speech. The techniques explored, such as data augmentation and transfer learning, show promise in improving the transcription of medical terms spoken with different accents. The findings have the potential to enhance the accessibility and usability of speech-based clinical systems, particularly in diverse healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Medical Spoken Named Entity Recognition
Khai Le-Duc
0
0
Spoken Named Entity Recognition (NER) aims to extracting named entities from speech and categorizing them into types like person, location, organization, etc. In this work, we present VietMed-NER - the first spoken NER dataset in the medical domain. To our best knowledge, our real-world dataset is the largest spoken NER dataset in the world in terms of the number of entity types, featuring 18 distinct types. Secondly, we present baseline results using various state-of-the-art pre-trained models: encoder-only and sequence-to-sequence. We found that pre-trained multilingual models XLM-R outperformed all monolingual models on both reference text and ASR output. Also in general, encoders perform better than sequence-to-sequence models for the NER task. By simply translating, the transcript is applicable not just to Vietnamese but to other languages as well. All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed
6/21/2024
🗣️
Advancing African-Accented Speech Recognition: Epistemic Uncertainty-Driven Data Selection for Generalizable ASR Models
Bonaventure F. P. Dossou
0
0
Accents play a pivotal role in shaping human communication, enhancing our ability to convey and comprehend messages with clarity and cultural nuance. While there has been significant progress in Automatic Speech Recognition (ASR), African-accented English ASR has been understudied due to a lack of training datasets, which are often expensive to create and demand colossal human labor. Combining several active learning paradigms and the core-set approach, we propose a new multi-rounds adaptation process that uses epistemic uncertainty to automate the annotation process, significantly reducing the associated costs and human labor. This novel method streamlines data annotation and strategically selects data samples that contribute most to model uncertainty, thereby enhancing training efficiency. We define a new metric called U-WER to track model adaptation to hard accents. We evaluate our approach across several domains, datasets, and high-performing speech models. Our results show that our approach leads to a 69.44% WER improvement while requiring on average 45% less data than established baselines. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating its viability for building generalizable ASR models in the context of accented African ASR. We open-source the code here: https://github.com/bonaventuredossou/active_learning_african_asr
5/24/2024

Automatic Speech Recognition for Biomedical Data in Bengali Language
Shariar Kabir, Nazmun Nahar, Shyamasree Saha, Mamunur Rashid
0
0
This paper presents the development of a prototype Automatic Speech Recognition (ASR) system specifically designed for Bengali biomedical data. Recent advancements in Bengali ASR are encouraging, but a lack of domain-specific data limits the creation of practical healthcare ASR models. This project bridges this gap by developing an ASR system tailored for Bengali medical terms like symptoms, severity levels, and diseases, encompassing two major dialects: Bengali and Sylheti. We train and evaluate two popular ASR frameworks on a comprehensive 46-hour Bengali medical corpus. Our core objective is to create deployable health-domain ASR systems for digital health applications, ultimately increasing accessibility for non-technical users in the healthcare sector.
6/21/2024
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
0
0
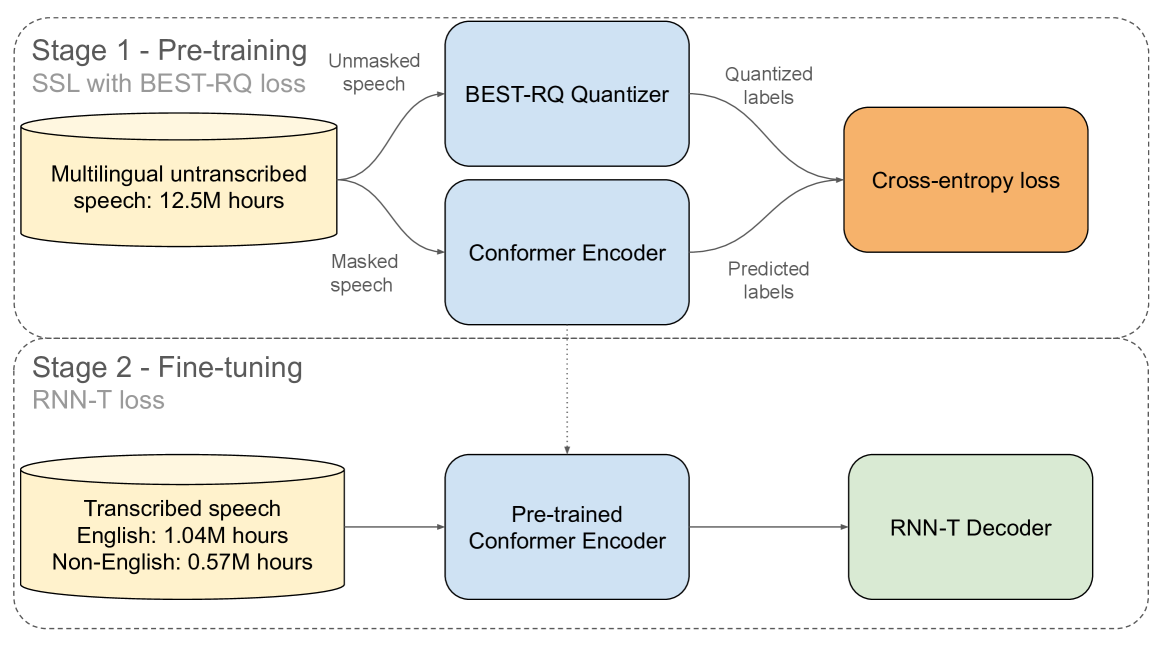
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
4/17/2024