Automating the Identification of High-Value Datasets in Open Government Data Portals
2406.10541
0
0

Abstract
Recognized for fostering innovation and transparency, driving economic growth, enhancing public services, supporting research, empowering citizens, and promoting environmental sustainability, High-Value Datasets (HVD) play a crucial role in the broader Open Government Data (OGD) movement. However, identifying HVD presents a resource-intensive and complex challenge due to the nuanced nature of data value. Our proposal aims to automate the identification of HVDs on OGD portals using a quantitative approach based on a detailed analysis of user interest derived from data usage statistics, thereby minimizing the need for human intervention. The proposed method involves extracting download data, analyzing metrics to identify high-value categories, and comparing HVD datasets across different portals. This automated process provides valuable insights into trends in dataset usage, reflecting citizens' needs and preferences. The effectiveness of our approach is demonstrated through its application to a sample of US OGD city portals. The practical implications of this study include contributing to the understanding of HVD at both local and national levels. By providing a systematic and efficient means of identifying HVD, our approach aims to inform open governance initiatives and practices, aiding OGD portal managers and public authorities in their efforts to optimize data dissemination and utilization.
Create account to get full access
Overview
- This paper presents a method for automatically identifying high-value datasets in open government data portals.
- The researchers focus on US municipalities as a case study and develop an algorithm to assess the quality and importance of datasets.
- The goal is to help government agencies and the public more easily navigate the vast amount of data available on open data portals.
Plain English Explanation
Open government data portals contain a large and growing number of datasets covering various aspects of local and national governance. However, not all of these datasets are equally valuable or useful to the public. This research paper presents a method to automatically identify the most important and high-quality datasets on these portals.
The researchers developed an algorithm that analyzes factors such as dataset metadata, user interactions, and external references to assess the value and significance of each dataset. By applying this algorithm to open data portals for US municipalities, they were able to surface the most crucial datasets that are likely to be of greatest interest and utility to citizens, policymakers, and other stakeholders.
This kind of automated system can help people more easily navigate the wealth of information available on open data portals, directing them to the most impactful and relevant datasets. This is particularly important as the amount of data published by governments continues to grow exponentially, making it increasingly difficult for users to efficiently find the most useful resources.
Technical Explanation
The core of the researchers' approach is a machine learning model that assesses the value of government datasets based on a variety of signals. These include the metadata associated with each dataset (e.g., title, description, tags), the level of user engagement (e.g., downloads, views, comments), and external references to the dataset from news articles, blog posts, or other online sources.
The model is trained on a set of datasets that have been manually labeled by domain experts as being "high-value" or not. It then learns to recognize the patterns and features that distinguish valuable datasets from less important ones. When applied to a new set of unlabeled datasets, the model can automatically predict their relative importance and priority.
The researchers tested this approach on open data portals for 40 US municipalities, covering over 20,000 unique datasets. Their results show that the automated system is able to effectively identify the most impactful datasets, outperforming alternative methods for dataset ranking and discovery. This has important implications for helping government agencies and the public more efficiently navigate the wealth of information available on open data platforms.
Critical Analysis
One potential limitation of this research is the reliance on manual labeling of "high-value" datasets for model training. While the researchers employed multiple domain experts to ensure consistent labeling, there may still be some subjectivity in these assessments. An interesting area for future work could be to explore more objective or data-driven approaches to defining dataset value.
Additionally, the researchers focused their evaluation on open data portals for US municipalities. While this provides a useful case study, it remains to be seen how well the approach would generalize to other levels of government (e.g., state, federal) or to open data platforms in other countries. Validating the model's performance in diverse contexts would bolster confidence in its broader applicability.
Overall, however, this paper presents a compelling and practical approach to a significant challenge in the world of open government data. Automating the identification of high-value datasets has the potential to greatly improve data discoverability and utilization, ultimately enhancing transparency and public engagement with government operations.
Conclusion
This research offers a novel method for automatically assessing the value and importance of datasets published on open government data portals. By leveraging machine learning to analyze various signals of dataset quality and significance, the researchers demonstrate an effective way to surface the most impactful resources amidst the growing volume of available data.
The techniques described in this paper have important implications for both government agencies and the general public. They can help ensure that critical information and insights are more easily discoverable, allowing decision-makers and citizens to make more informed choices. As open data initiatives continue to expand, this kind of automated data curation will become increasingly valuable in navigating the wealth of information at our fingertips.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
From an Integrated Usability Framework to Lessons on Usability and Performance of Open Government Data Portals: A Comparative Study of European Union and Gulf Cooperation Council Countries
Fillip Molodtsov, Anastasija Nikiforova
0
0
Open Government Data (OGD) initiatives aim to enhance public participation and collaboration by making government data accessible to diverse stakeholders, fostering social, environmental, and economic benefits through public value generation. However, challenges such as declining popularity, lack of OGD portal usability, and private interests overshadowing public accessibility persist. This study proposes an integrated usability framework for evaluating OGD portals, focusing on inclusivity, user collaboration, and data exploration. Employing Design Science Research (DSR), the framework is developed and applied to 33 OGD portals from the European Union (EU) and Gulf Cooperation Council (GCC) countries. The quantitative analysis is complemented by qualitative analysis and clustering, enabling assessment of portal performance, identification of best practices, and common weaknesses. This results in 19 high-level recommendations for improving the open data ecosystem. Key findings highlight the competitive nature of EU portals and the innovative features of GCC portals, emphasizing the need for multilingual support, better communication mechanisms, and improved dataset usability. The study stresses trends towards exposing data quality indicators and incorporating advanced functionalities such as AI systems. This framework serves as a baseline for OGD portal requirements elicitation, offering practical implications for developing sustainable, collaborative, and robust OGD portals, ultimately contributing to a more transparent and equitable world.
6/14/2024
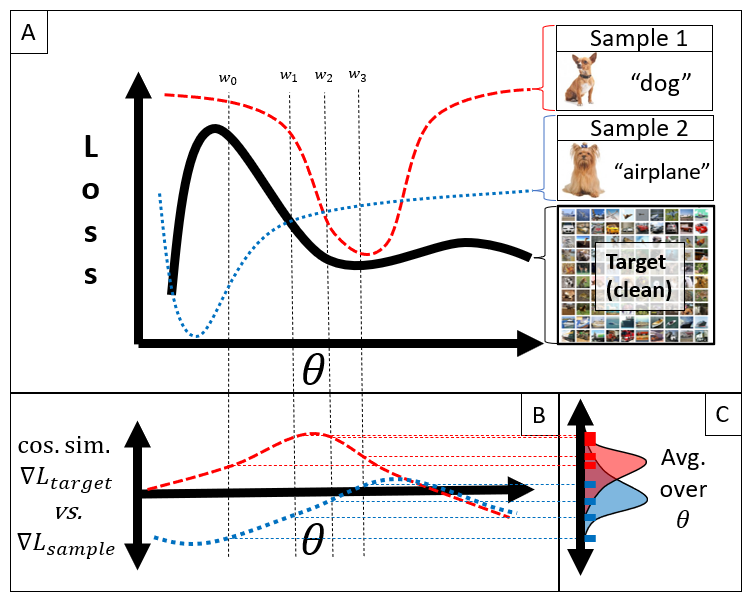
Data Valuation with Gradient Similarity
Nathaniel J. Evans, Gordon B. Mills, Guanming Wu, Xubo Song, Shannon McWeeney
0
0
High-quality data is crucial for accurate machine learning and actionable analytics, however, mislabeled or noisy data is a common problem in many domains. Distinguishing low- from high-quality data can be challenging, often requiring expert knowledge and considerable manual intervention. Data Valuation algorithms are a class of methods that seek to quantify the value of each sample in a dataset based on its contribution or importance to a given predictive task. These data values have shown an impressive ability to identify mislabeled observations, and filtering low-value data can boost machine learning performance. In this work, we present a simple alternative to existing methods, termed Data Valuation with Gradient Similarity (DVGS). This approach can be easily applied to any gradient descent learning algorithm, scales well to large datasets, and performs comparably or better than baseline valuation methods for tasks such as corrupted label discovery and noise quantification. We evaluate the DVGS method on tabular, image and RNA expression datasets to show the effectiveness of the method across domains. Our approach has the ability to rapidly and accurately identify low-quality data, which can reduce the need for expert knowledge and manual intervention in data cleaning tasks.
5/15/2024
💬
Towards Robust Evaluation: A Comprehensive Taxonomy of Datasets and Metrics for Open Domain Question Answering in the Era of Large Language Models
Akchay Srivastava, Atif Memon
0
0
Open Domain Question Answering (ODQA) within natural language processing involves building systems that answer factual questions using large-scale knowledge corpora. Recent advances stem from the confluence of several factors, such as large-scale training datasets, deep learning techniques, and the rise of large language models. High-quality datasets are used to train models on realistic scenarios and enable the evaluation of the system on potentially unseen data. Standardized metrics facilitate comparisons between different ODQA systems, allowing researchers to objectively track advancements in the field. Our study presents a thorough examination of the current landscape of ODQA benchmarking by reviewing 52 datasets and 20 evaluation techniques across textual and multimodal modalities. We introduce a novel taxonomy for ODQA datasets that incorporates both the modality and difficulty of the question types. Additionally, we present a structured organization of ODQA evaluation metrics along with a critical analysis of their inherent trade-offs. Our study aims to empower researchers by providing a framework for the robust evaluation of modern question-answering systems. We conclude by identifying the current challenges and outlining promising avenues for future research and development.
6/21/2024
📊
Towards augmented data quality management: Automation of Data Quality Rule Definition in Data Warehouses
Heidi Carolina Tamm, Anastasija Nikiforova
0
0
In the contemporary data-driven landscape, ensuring data quality (DQ) is crucial for deriving actionable insights from vast data repositories. The objective of this study is to explore the potential for automating data quality management within data warehouses as data repository commonly used by large organizations. By conducting a systematic review of existing DQ tools available in the market and academic literature, the study assesses their capability to automatically detect and enforce data quality rules. The review encompassed 151 tools from various sources, revealing that most current tools focus on data cleansing and fixing in domain-specific databases rather than data warehouses. Only a limited number of tools, specifically ten, demonstrated the capability to detect DQ rules, not to mention implementing this in data warehouses. The findings underscore a significant gap in the market and academic research regarding AI-augmented DQ rule detection in data warehouses. This paper advocates for further development in this area to enhance the efficiency of DQ management processes, reduce human workload, and lower costs. The study highlights the necessity of advanced tools for automated DQ rule detection, paving the way for improved practices in data quality management tailored to data warehouse environments. The study can guide organizations in selecting data quality tool that would meet their requirements most.
6/18/2024