Data Valuation with Gradient Similarity

0
Sign in to get full access
Overview
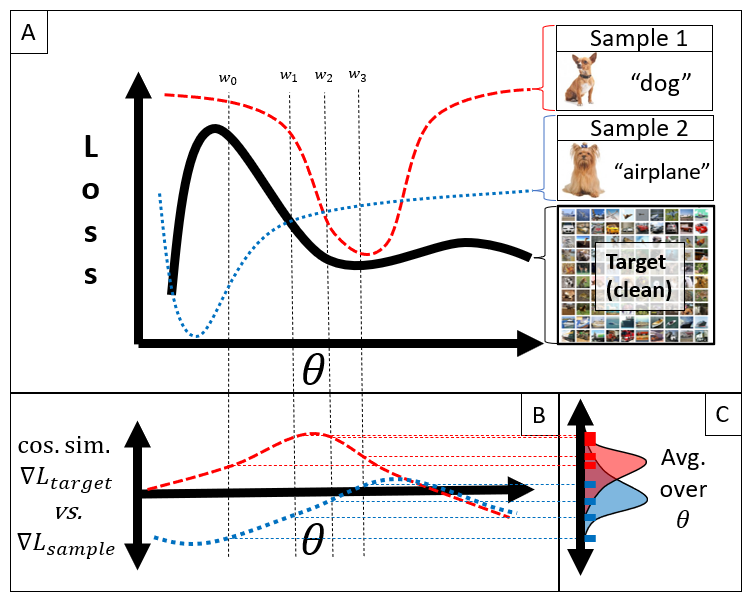
- This paper introduces a novel approach for data valuation called "Data Valuation with Gradient Similarity" (DVGS).
- The key idea is to use the gradients of a model's loss function with respect to the training data as a way to quantify the value of each data point.
- The authors demonstrate the effectiveness of DVGS on several machine learning tasks and show that it outperforms existing data valuation methods.
Plain English Explanation
In machine learning, the training data used to build a model is crucial for its performance. Data valuation with gradient similarity is a new way to determine how valuable each data point is to the model.
The core concept is to look at the gradients, or rate of change, of the model's loss function with respect to each training data point. Data points that have a bigger impact on the loss function are considered more valuable, as they contribute more to the model's learning.
By quantifying the value of each data point in this way, the authors show that their DVGS method can outperform other existing approaches to data valuation. This allows machine learning practitioners to better understand and optimize the data they use, leading to more robust and effective models.
Technical Explanation
The DVGS method works by computing the gradient of the model's loss function with respect to each training data point. The magnitude of this gradient reflects how much a given data point influences the model's learning.
The authors test DVGS on several machine learning tasks, including image classification, text classification, and regression problems. They compare the performance of models trained with data selected using DVGS to models trained with data selected using other data valuation techniques, such as ECoVaL and divergence-based approaches.
The results show that models trained with data selected using DVGS consistently outperform the other methods, demonstrating the effectiveness of using gradient-based information to quantify data value. The authors also investigate the robustness of DVGS to dataset shift and find that it can identify valuable data points even when the test distribution differs from the training distribution.
Critical Analysis
The DVGS paper presents a compelling approach to data valuation, but there are a few potential limitations and areas for further research:
-
The method relies on the ability to compute gradients, which may be challenging for certain types of models or tasks. Further work is needed to explore its applicability to a wider range of machine learning scenarios.
-
The authors only consider regression and classification tasks in their experiments. It would be valuable to investigate the performance of DVGS on other problem domains, such as adversarial validation for geospatial data or gradient-based data selection for federated learning.
-
The paper does not explore how DVGS might be used in an active learning setting, where the model could iteratively select the most valuable data points to label and retrain. Integrating DVGS into such a framework could lead to further performance improvements.
Overall, the DVGS approach is a promising step forward in data valuation and could have significant implications for improving the efficiency and effectiveness of machine learning models.
Conclusion
The Data Valuation with Gradient Similarity (DVGS) method introduced in this paper provides a novel way to quantify the value of training data for machine learning models. By leveraging the gradients of the model's loss function, DVGS can identify the most influential data points and use this information to improve model performance.
The authors demonstrate the effectiveness of DVGS across a variety of tasks, showing that it outperforms other state-of-the-art data valuation techniques. This suggests that gradient-based data valuation is a powerful tool for machine learning practitioners to optimize their datasets and build more robust and effective models.
While the paper highlights the potential of DVGS, further research is needed to explore its broader applicability and integration with other machine learning paradigms. Nonetheless, this work represents an important step forward in the field of data valuation and opens up new avenues for enhancing the efficiency and impact of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Valuation with Gradient Similarity
Nathaniel J. Evans, Gordon B. Mills, Guanming Wu, Xubo Song, Shannon McWeeney
High-quality data is crucial for accurate machine learning and actionable analytics, however, mislabeled or noisy data is a common problem in many domains. Distinguishing low- from high-quality data can be challenging, often requiring expert knowledge and considerable manual intervention. Data Valuation algorithms are a class of methods that seek to quantify the value of each sample in a dataset based on its contribution or importance to a given predictive task. These data values have shown an impressive ability to identify mislabeled observations, and filtering low-value data can boost machine learning performance. In this work, we present a simple alternative to existing methods, termed Data Valuation with Gradient Similarity (DVGS). This approach can be easily applied to any gradient descent learning algorithm, scales well to large datasets, and performs comparably or better than baseline valuation methods for tasks such as corrupted label discovery and noise quantification. We evaluate the DVGS method on tabular, image and RNA expression datasets to show the effectiveness of the method across domains. Our approach has the ability to rapidly and accurately identify low-quality data, which can reduce the need for expert knowledge and manual intervention in data cleaning tasks.
Read more5/15/2024
🧠
0
Neural Dynamic Data Valuation
Zhangyong Liang, Huanhuan Gao, Ji Zhang
Data constitute the foundational component of the data economy and its marketplaces. Efficient and fair data valuation has emerged as a topic of significant interest. Many approaches based on marginal contribution have shown promising results in various downstream tasks. However, they are well known to be computationally expensive as they require training a large number of utility functions, which are used to evaluate the usefulness or value of a given dataset for a specific purpose. As a result, it has been recognized as infeasible to apply these methods to a data marketplace involving large-scale datasets. Consequently, a critical issue arises: how can the re-training of the utility function be avoided? To address this issue, we propose a novel data valuation method from the perspective of optimal control, named the neural dynamic data valuation (NDDV). Our method has solid theoretical interpretations to accurately identify the data valuation via the sensitivity of the data optimal control state. In addition, we implement a data re-weighting strategy to capture the unique features of data points, ensuring fairness through the interaction between data points and the mean-field states. Notably, our method requires only training once to estimate the value of all data points, significantly improving the computational efficiency. We conduct comprehensive experiments using different datasets and tasks. The results demonstrate that the proposed NDDV method outperforms the existing state-of-the-art data valuation methods in accurately identifying data points with either high or low values and is more computationally efficient.
Read more6/13/2024
📊
0
Data Valuation by Leveraging Global and Local Statistical Information
Xiaoling Zhou, Ou Wu, Michael K. Ng, Hao Jiang
Data valuation has garnered increasing attention in recent years, given the critical role of high-quality data in various applications, particularly in machine learning tasks. There are diverse technical avenues to quantify the value of data within a corpus. While Shapley value-based methods are among the most widely used techniques in the literature due to their solid theoretical foundation, the accurate calculation of Shapley values is often intractable, leading to the proposal of numerous approximated calculation methods. Despite significant progress, nearly all existing methods overlook the utilization of distribution information of values within a data corpus. In this paper, we demonstrate that both global and local statistical information of value distributions hold significant potential for data valuation within the context of machine learning. Firstly, we explore the characteristics of both global and local value distributions across several simulated and real data corpora. Useful observations and clues are obtained. Secondly, we propose a new data valuation method that estimates Shapley values by incorporating the explored distribution characteristics into an existing method, AME. Thirdly, we present a new path to address the dynamic data valuation problem by formulating an optimization problem that integrates information of both global and local value distributions. Extensive experiments are conducted on Shapley value estimation, value-based data removal/adding, mislabeled data detection, and incremental/decremental data valuation. The results showcase the effectiveness and efficiency of our proposed methodologies, affirming the significant potential of global and local value distributions in data valuation.
Read more5/29/2024

0
CHG Shapley: Efficient Data Valuation and Selection towards Trustworthy Machine Learning
Huaiguang Cai
Understanding the decision-making process of machine learning models is crucial for ensuring trustworthy machine learning. Data Shapley, a landmark study on data valuation, advances this understanding by assessing the contribution of each datum to model accuracy. However, the resource-intensive and time-consuming nature of multiple model retraining poses challenges for applying Data Shapley to large datasets. To address this, we propose the CHG (Conduct of Hardness and Gradient) score, which approximates the utility of each data subset on model accuracy during a single model training. By deriving the closed-form expression of the Shapley value for each data point under the CHG score utility function, we reduce the computational complexity to the equivalent of a single model retraining, an exponential improvement over existing methods. Additionally, we employ CHG Shapley for real-time data selection, demonstrating its effectiveness in identifying high-value and noisy data. CHG Shapley facilitates trustworthy model training through efficient data valuation, introducing a novel data-centric perspective on trustworthy machine learning.
Read more6/19/2024