Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
2404.08680
0
0
Abstract
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
Create account to get full access
Overview
- This paper explores a method for automating the process of research synthesis using domain-specific fine-tuning of large language models.
- The researchers aim to address the challenges and limitations of traditional systematic literature review approaches by leveraging the capabilities of large language models.
- The proposed approach involves fine-tuning a pre-trained language model on a domain-specific corpus to enable efficient and accurate research synthesis.
Plain English Explanation
Researchers are often tasked with reviewing and synthesizing existing research on a particular topic, a process known as a systematic literature review. This can be a time-consuming and labor-intensive endeavor, requiring researchers to manually sift through a large volume of scientific papers and extract key insights.
To streamline this process, the authors of this paper have explored the use of <a href="https://aimodels.fyi/papers/arxiv/navigating-landscape-large-language-models-comprehensive-review">large language models</a> (LLMs), which are AI systems trained on vast amounts of text data. By fine-tuning an LLM on a domain-specific corpus of research papers, the researchers aim to create a model that can efficiently and accurately synthesize the key findings and insights from a body of literature.
The idea is that the fine-tuned LLM will have a deep understanding of the domain-specific concepts, terminology, and research methodologies, allowing it to quickly and accurately extract and summarize the relevant information from a set of research papers. This could greatly reduce the time and effort required for researchers to conduct a comprehensive literature review, freeing them up to focus on higher-level analysis and interpretation.
The authors provide a detailed overview of the systematic literature review process and the challenges it presents, as well as the potential benefits of leveraging LLMs to automate this task. They also outline the technical approach for fine-tuning an LLM and evaluate the performance of the resulting model on a set of benchmark tasks.
Technical Explanation
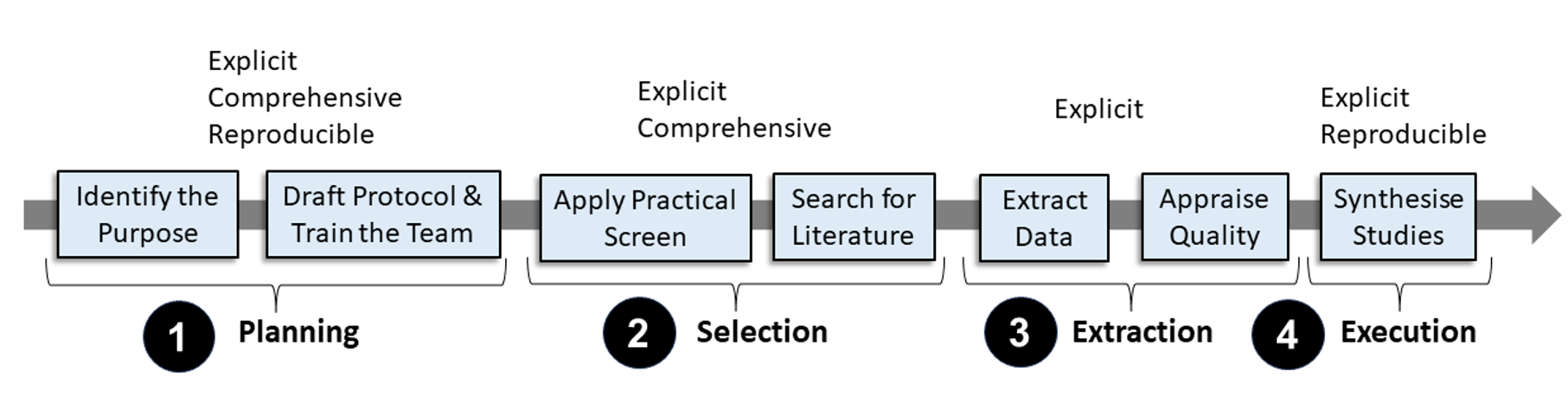
The paper begins by providing background on the systematic literature review (SLR) process, which involves identifying, evaluating, and synthesizing all relevant research on a particular topic. The authors note that this process can be time-consuming and labor-intensive, requiring researchers to manually read and extract key insights from a large number of scientific papers.
To address these challenges, the researchers propose a method for automating the research synthesis task using <a href="https://aimodels.fyi/papers/arxiv/apprentices-to-research-assistants-advancing-research-large">domain-specific fine-tuning of large language models</a>. The general idea is to take a pre-trained LLM, such as GPT-3 or BERT, and fine-tune it on a corpus of research papers within a specific domain (e.g., machine learning, cancer biology). This fine-tuning process allows the model to develop a deep understanding of the domain-specific concepts, terminology, and research methodologies, enabling it to effectively extract and synthesize key insights from new research papers.
The authors describe the technical details of the fine-tuning process, including the data preparation, model architecture, and training procedures. They also outline the evaluation tasks used to assess the performance of the fine-tuned model, such as extractive summarization, answer generation, and question answering.
The results of the experiments demonstrate that the fine-tuned LLM outperforms generic language models and other baselines on these benchmark tasks, suggesting that it can effectively automate the research synthesis process. The authors also discuss the potential limitations of their approach, such as the reliance on high-quality training data and the potential for bias or errors in the model's outputs.
Critical Analysis
The authors acknowledge several caveats and limitations of their proposed approach. First, the success of the method relies heavily on the quality and representativeness of the domain-specific corpus used for fine-tuning the language model. If the training data is not sufficiently comprehensive or diverse, the resulting model may have blindspots or biases that could impact its performance on research synthesis tasks.
Additionally, the authors note that the fine-tuned model's outputs, while potentially more accurate and efficient than manual literature reviews, still require human oversight and validation. There is a risk of the model making incorrect or biased inferences, and researchers would need to carefully evaluate the model's outputs to ensure the reliability of the research synthesis.
Another potential limitation is the scalability of the approach. While the fine-tuning process may be more efficient than traditional literature reviews for individual research projects, the time and computational resources required to fine-tune a model for each new domain or topic could become a bottleneck as the scope of research synthesis tasks grows.
Overall, the authors present a promising approach to automating research synthesis, but there are several areas that warrant further investigation and refinement. <a href="https://aimodels.fyi/papers/arxiv/supervised-knowledge-makes-large-language-models-better">Exploring ways to improve the robustness and generalizability of the fine-tuned models</a>, as well as developing methods to ensure the reliability and transparency of the research synthesis outputs, could help address some of the identified limitations.
Conclusion
This paper introduces a novel approach to automating the process of research synthesis using domain-specific fine-tuning of large language models. The authors demonstrate the potential of this method to improve the efficiency and accuracy of systematic literature reviews, a task that is currently highly labor-intensive for researchers.
By leveraging the capabilities of LLMs, the proposed approach could significantly reduce the time and effort required to synthesize the key findings and insights from a body of research literature. This could free up researchers to focus on higher-level analysis and interpretation, ultimately accelerating the pace of scientific progress.
While the authors acknowledge several caveats and limitations, the overall results suggest that <a href="https://aimodels.fyi/papers/arxiv/novel-paradigm-boosting-translation-capabilities-large-language">integrating LLMs into the research synthesis process</a> is a promising direction for future exploration. As the field of <a href="https://aimodels.fyi/papers/arxiv/exploring-autonomous-agents-through-lens-large-language">large language models continues to advance</a>, the potential applications for automating and augmenting research workflows will only continue to grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Apprentices to Research Assistants: Advancing Research with Large Language Models
M. Namvarpour, A. Razi
0
0
Large Language Models (LLMs) have emerged as powerful tools in various research domains. This article examines their potential through a literature review and firsthand experimentation. While LLMs offer benefits like cost-effectiveness and efficiency, challenges such as prompt tuning, biases, and subjectivity must be addressed. The study presents insights from experiments utilizing LLMs for qualitative analysis, highlighting successes and limitations. Additionally, it discusses strategies for mitigating challenges, such as prompt optimization techniques and leveraging human expertise. This study aligns with the 'LLMs as Research Tools' workshop's focus on integrating LLMs into HCI data work critically and ethically. By addressing both opportunities and challenges, our work contributes to the ongoing dialogue on their responsible application in research.
4/10/2024

The Promise and Challenges of Using LLMs to Accelerate the Screening Process of Systematic Reviews
Aleksi Huotala, Miikka Kuutila, Paul Ralph, Mika Mantyla
0
0
Systematic review (SR) is a popular research method in software engineering (SE). However, conducting an SR takes an average of 67 weeks. Thus, automating any step of the SR process could reduce the effort associated with SRs. Our objective is to investigate if Large Language Models (LLMs) can accelerate title-abstract screening by simplifying abstracts for human screeners, and automating title-abstract screening. We performed an experiment where humans screened titles and abstracts for 20 papers with both original and simplified abstracts from a prior SR. The experiment with human screeners was reproduced with GPT-3.5 and GPT-4 LLMs to perform the same screening tasks. We also studied if different prompting techniques (Zero-shot (ZS), One-shot (OS), Few-shot (FS), and Few-shot with Chain-of-Thought (FS-CoT)) improve the screening performance of LLMs. Lastly, we studied if redesigning the prompt used in the LLM reproduction of screening leads to improved performance. Text simplification did not increase the screeners' screening performance, but reduced the time used in screening. Screeners' scientific literacy skills and researcher status predict screening performance. Some LLM and prompt combinations perform as well as human screeners in the screening tasks. Our results indicate that the GPT-4 LLM is better than its predecessor, GPT-3.5. Additionally, Few-shot and One-shot prompting outperforms Zero-shot prompting. Using LLMs for text simplification in the screening process does not significantly improve human performance. Using LLMs to automate title-abstract screening seems promising, but current LLMs are not significantly more accurate than human screeners. To recommend the use of LLMs in the screening process of SRs, more research is needed. We recommend future SR studies publish replication packages with screening data to enable more conclusive experimenting with LLM screening.
5/9/2024
💬
Exploring the use of a Large Language Model for data extraction in systematic reviews: a rapid feasibility study
Lena Schmidt, Kaitlyn Hair, Sergio Graziozi, Fiona Campbell, Claudia Kapp, Alireza Khanteymoori, Dawn Craig, Mark Engelbert, James Thomas
0
0
This paper describes a rapid feasibility study of using GPT-4, a large language model (LLM), to (semi)automate data extraction in systematic reviews. Despite the recent surge of interest in LLMs there is still a lack of understanding of how to design LLM-based automation tools and how to robustly evaluate their performance. During the 2023 Evidence Synthesis Hackathon we conducted two feasibility studies. Firstly, to automatically extract study characteristics from human clinical, animal, and social science domain studies. We used two studies from each category for prompt-development; and ten for evaluation. Secondly, we used the LLM to predict Participants, Interventions, Controls and Outcomes (PICOs) labelled within 100 abstracts in the EBM-NLP dataset. Overall, results indicated an accuracy of around 80%, with some variability between domains (82% for human clinical, 80% for animal, and 72% for studies of human social sciences). Causal inference methods and study design were the data extraction items with the most errors. In the PICO study, participants and intervention/control showed high accuracy (>80%), outcomes were more challenging. Evaluation was done manually; scoring methods such as BLEU and ROUGE showed limited value. We observed variability in the LLMs predictions and changes in response quality. This paper presents a template for future evaluations of LLMs in the context of data extraction for systematic review automation. Our results show that there might be value in using LLMs, for example as second or third reviewers. However, caution is advised when integrating models such as GPT-4 into tools. Further research on stability and reliability in practical settings is warranted for each type of data that is processed by the LLM.
5/24/2024
💬
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
0
0
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
6/12/2024