Baby Bear: Seeking a Just Right Rating Scale for Scalar Annotations

0

Sign in to get full access
Overview
- The paper introduces a new method called "Baby Bear" for creating rating scales for scalar annotations that are just right - not too large or too small.
- It addresses challenges in direct assessment, which is a common way to collect scalar annotations, such as inconsistent scale usage and difficulty in comparing across annotators.
- The authors propose Baby Bear as a solution to find a "just right" rating scale that is tailored to the task and data at hand.
Plain English Explanation
The paper discusses the challenges of collecting scalar ratings or scores from people, which is a common task in machine learning and AI research. When people provide ratings on a scale, they don't always use the scale the same way. Some may use the full range, while others may stick to the middle. This makes it difficult to compare ratings across different people.
The authors introduce a new method called "Baby Bear" that aims to find a "just right" rating scale for a particular task or dataset. The idea is to start with a large scale, then iteratively adjust it to find the optimal size that allows people to provide meaningful and consistent ratings. This helps ensure the ratings can be properly compared and used in further analysis or model training.
The key innovation of Baby Bear is its ability to automatically determine the most appropriate scale size, rather than relying on researchers to manually choose a scale upfront. This can save time and lead to higher quality annotations that are more useful for downstream applications.
Technical Explanation
The paper focuses on the problem of direct assessment, a common method for collecting scalar annotations where raters provide a numeric score on a predefined scale. The authors identify two key challenges with direct assessment:
- Inconsistent scale usage: Raters may not use the full range of the scale, leading to compressed or skewed distributions of scores that are difficult to compare.
- Selecting the "just right" scale: Researchers must choose an appropriate scale size upfront, which is challenging without knowing the natural range of scores for a given task or dataset.
To address these issues, the authors propose Baby Bear, a method that automatically finds a "just right" rating scale by iteratively adjusting the scale size. The key steps are:
- Start with a large initial scale (e.g., 1-100)
- Collect ratings on this scale and analyze the distribution
- Adjust the scale size based on the distribution (e.g., shrink it if the ratings are too compressed)
- Repeat steps 2-3 until the scale size is "just right"
The authors evaluate Baby Bear on several datasets and show that it can improve the quality and consistency of scalar annotations compared to using a fixed scale.
Critical Analysis
The Baby Bear method appears to be a promising approach for addressing the challenges of direct assessment. By automatically tuning the rating scale to the task and data at hand, it can help ensure more meaningful and consistent annotations.
However, the paper does not address a few potential limitations:
- Generalization: The authors only evaluate Baby Bear on a few datasets. More research is needed to understand how it performs across a wider range of tasks and domains.
- Cognitive Burden: Repeatedly adjusting the scale size may increase the cognitive load on raters, which could impact annotation quality. The authors should investigate the tradeoffs between scale optimization and rater fatigue.
- Data Efficiency: The iterative nature of Baby Bear requires multiple rounds of data collection, which could be time-consuming and expensive. Exploring more data-efficient approaches may be beneficial.
Additionally, the paper could have provided more discussion on the broader implications of this work. For example, how might Baby Bear's ability to find the "just right" scale size impact downstream machine learning models or applications that rely on scalar annotations?
Conclusion
The Baby Bear method introduced in this paper represents an interesting and potentially impactful approach to addressing the challenges of direct assessment for collecting scalar annotations. By automatically tuning the rating scale, it can help ensure more consistent and meaningful data for a variety of AI and machine learning tasks.
While the paper demonstrates promising results, further research is needed to fully understand the method's limitations and broader implications. Exploring ways to improve data efficiency and minimize cognitive burden on raters could also strengthen the Baby Bear approach. Overall, this work highlights the importance of careful scale design in annotation tasks and provides a valuable contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Baby Bear: Seeking a Just Right Rating Scale for Scalar Annotations
Xu Han, Felix Yu, Joao Sedoc, Benjamin Van Durme
Our goal is a mechanism for efficiently assigning scalar ratings to each of a large set of elements. For example, what percent positive or negative is this product review? When sample sizes are small, prior work has advocated for methods such as Best Worst Scaling (BWS) as being more robust than direct ordinal annotation (Likert scales). Here we first introduce IBWS, which iteratively collects annotations through Best-Worst Scaling, resulting in robustly ranked crowd-sourced data. While effective, IBWS is too expensive for large-scale tasks. Using the results of IBWS as a best-desired outcome, we evaluate various direct assessment methods to determine what is both cost-efficient and best correlating to a large scale BWS annotation strategy. Finally, we illustrate in the domains of dialogue and sentiment how these annotations can support robust learning-to-rank models.
Read more8/20/2024

0
You are an expert annotator: Automatic Best-Worst-Scaling Annotations for Emotion Intensity Modeling
Christopher Bagdon, Prathamesh Karmalker, Harsha Gurulingappa, Roman Klinger
Labeling corpora constitutes a bottleneck to create models for new tasks or domains. Large language models mitigate the issue with automatic corpus labeling methods, particularly for categorical annotations. Some NLP tasks such as emotion intensity prediction, however, require text regression, but there is no work on automating annotations for continuous label assignments. Regression is considered more challenging than classification: The fact that humans perform worse when tasked to choose values from a rating scale lead to comparative annotation methods, including best-worst scaling. This raises the question if large language model-based annotation methods show similar patterns, namely that they perform worse on rating scale annotation tasks than on comparative annotation tasks. To study this, we automate emotion intensity predictions and compare direct rating scale predictions, pairwise comparisons and best-worst scaling. We find that the latter shows the highest reliability. A transformer regressor fine-tuned on these data performs nearly on par with a model trained on the original manual annotations.
Read more4/23/2024
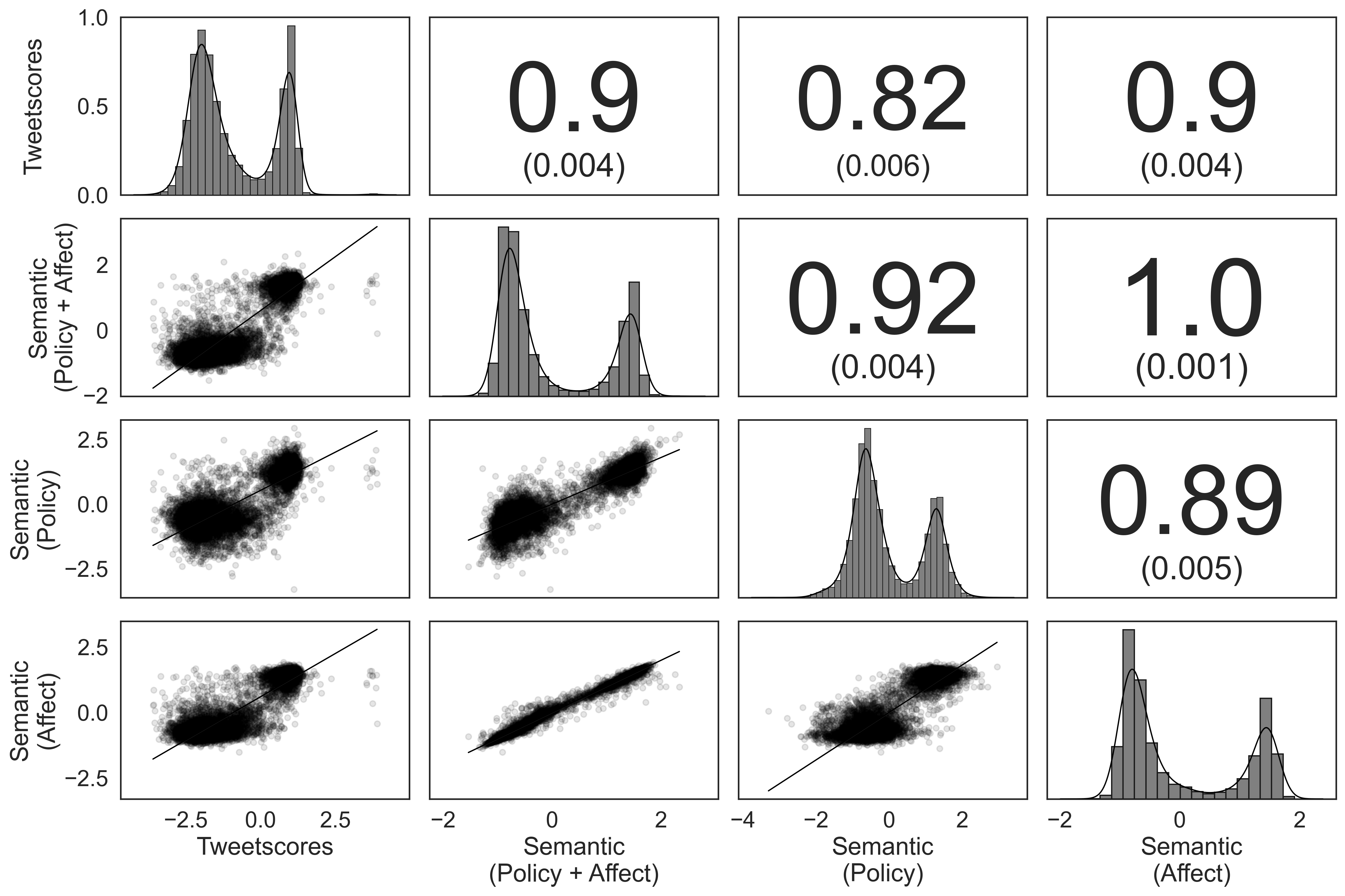
0
Semantic Scaling: Bayesian Ideal Point Estimates with Large Language Models
Michael Burnham
This paper introduces Semantic Scaling, a novel method for ideal point estimation from text. I leverage large language models to classify documents based on their expressed stances and extract survey-like data. I then use item response theory to scale subjects from these data. Semantic Scaling significantly improves on existing text-based scaling methods, and allows researchers to explicitly define the ideological dimensions they measure. This represents the first scaling approach that allows such flexibility outside of survey instruments and opens new avenues of inquiry for populations difficult to survey. Additionally, it works with documents of varying length, and produces valid estimates of both mass and elite ideology. I demonstrate that the method can differentiate between policy preferences and in-group/out-group affect. Among the public, Semantic Scaling out-preforms Tweetscores according to human judgement; in Congress, it recaptures the first dimension DW-NOMINATE while allowing for greater flexibility in resolving construct validity challenges.
Read more5/7/2024
🌿
0
Using Natural Language Explanations to Rescale Human Judgments
Manya Wadhwa, Jifan Chen, Junyi Jessy Li, Greg Durrett
The rise of large language models (LLMs) has brought a critical need for high-quality human-labeled data, particularly for processes like human feedback and evaluation. A common practice is to label data via consensus annotation over human judgments. However, annotators' judgments for subjective tasks can differ in many ways: they may reflect different qualitative judgments about an example, and they may be mapped to a labeling scheme in different ways. We show that these nuances can be captured by natural language explanations, and propose a method to rescale ordinal annotations and explanations using LLMs. Specifically, we feed annotators' Likert ratings and corresponding explanations into an LLM and prompt it to produce a numeric score anchored in a scoring rubric. These scores should reflect the annotators' underlying assessments of the example. The rubric can be designed or modified after annotation, and include distinctions that may not have been known when the original error taxonomy was devised. We explore our technique in the context of rating system outputs for a document-grounded question answering task, where LLMs achieve near-human performance. Our method rescales the raw judgments without impacting agreement and brings the scores closer to human judgments grounded in the same scoring rubric.
Read more9/10/2024