Semantic Scaling: Bayesian Ideal Point Estimates with Large Language Models

0
Sign in to get full access
Overview
- The research paper proposes a new method called "Semantic Scaling" for estimating ideological positions of political actors using large language models.
- The method uses Bayesian inference to derive ideal point estimates from text data, providing a more nuanced and interpretable way to measure political ideology compared to traditional approaches.
- The paper demonstrates the effectiveness of Semantic Scaling on several real-world datasets, showing how it can uncover interesting insights about political dynamics.
Plain English Explanation
Measuring the political views of individuals or organizations can be challenging, but this research introduces a new technique called "Semantic Scaling" that aims to do it more accurately.
The key idea is to use powerful language models, which are AI systems trained on vast amounts of text data, to infer the underlying ideological positions of political actors based on the language they use. By applying Bayesian statistical methods, the researchers can derive detailed "ideal point" estimates that capture the nuances of someone's political orientation, rather than simply classifying them as liberal or conservative.
This approach builds on prior work in the field of text scaling, but the novelty here is leveraging the semantic understanding of large language models to make the ideology measurement more interpretable and insightful.
The researchers demonstrate the Semantic Scaling method on real political datasets, showing how it can uncover interesting patterns and relationships that might be missed by more simplistic analysis. For example, it can identify subtle differences in the positioning of political figures or reveal the multidimensional nature of certain ideological divides.
Overall, this research represents an important advance in the measurement of political ideology, with potential applications in fields like public policy, election analysis, and social science research.
Technical Explanation
The core of the Semantic Scaling approach is to use Bayesian inference to derive ideal point estimates from text data, rather than relying on more traditional methods like supervised classification or scaling techniques based on word frequencies.
The researchers first obtain text data associated with different political actors, such as speeches, social media posts, or policy documents. They then leverage the semantic understanding of a large language model, such as GPT-3, to extract rich feature representations of this text data.
Building on frameworks like "You are the Expert Annotator", the researchers formulate a Bayesian model that relates the latent ideological positions of the actors to the observed text features. This model is then used to infer the posterior distribution of the ideal point estimates for each actor, providing a more nuanced and interpretable measure of their political orientation.
The key advantages of this Semantic Scaling approach are:
- Interpretability: The ideal point estimates have a clear conceptual meaning, allowing for easier interpretation and analysis compared to more opaque techniques like supervised classification.
- Flexibility: The Bayesian framework can incorporate additional information, such as actor characteristics or contextual factors, to refine the ideology estimates.
- Generalizability: The method can be applied to diverse text data sources, including speeches, social media, and policy documents, making it widely applicable.
The researchers validate the Semantic Scaling method on several real-world datasets, demonstrating its ability to uncover interesting patterns in political dynamics that align with expert assessments and existing knowledge.
Critical Analysis
The Semantic Scaling approach represents an important advance in the measurement of political ideology, but it is not without its limitations.
As noted in the "Measurement Age of LLMs" paper, the performance of large language models can be sensitive to biases and artifacts present in the training data, which could potentially skew the ideology estimates. The researchers acknowledge this issue and suggest further exploration of techniques to mitigate such biases.
Additionally, the Bayesian modeling framework requires making certain assumptions about the underlying data-generating process, and the validity of these assumptions could be an area for further investigation. The "Semantic Phrase Processing" paper highlights some of the challenges in accurately modeling the semantics of political text, which could impact the reliability of the Semantic Scaling approach.
Overall, the Semantic Scaling method provides a promising new direction for measuring political ideology, but continued research and validation on diverse datasets will be necessary to fully assess its strengths and limitations. Encouraging critical engagement with the underlying methodology and its potential biases is crucial for ensuring the responsible and ethical application of these techniques in real-world settings.
Conclusion
The Semantic Scaling method introduced in this research paper represents a significant step forward in the measurement of political ideology. By leveraging the semantic understanding of large language models and Bayesian inference, the approach offers a more nuanced and interpretable way to estimate the ideological positions of political actors.
The mathematical foundations of this work build on the "Learning Semantic Languages" framework, demonstrating the potential for AI-driven techniques to advance our understanding of complex social and political phenomena.
While the Semantic Scaling method shows promise, ongoing research and validation will be crucial to address potential biases and ensure the responsible application of these tools. Nevertheless, this research represents an important contribution to the field, with the potential to yield valuable insights for policymakers, political analysts, and social scientists.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Scaling: Bayesian Ideal Point Estimates with Large Language Models
Michael Burnham
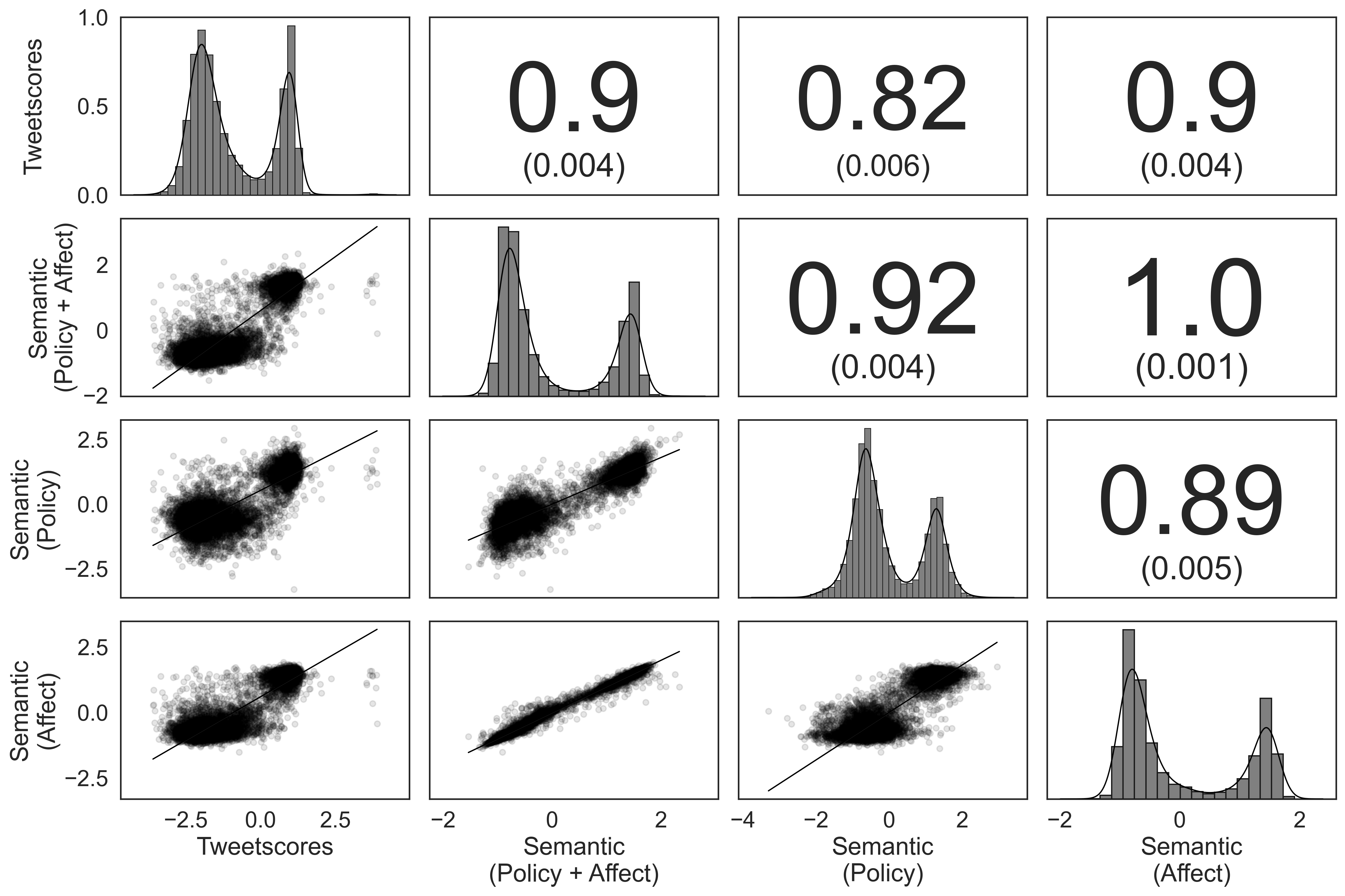
This paper introduces Semantic Scaling, a novel method for ideal point estimation from text. I leverage large language models to classify documents based on their expressed stances and extract survey-like data. I then use item response theory to scale subjects from these data. Semantic Scaling significantly improves on existing text-based scaling methods, and allows researchers to explicitly define the ideological dimensions they measure. This represents the first scaling approach that allows such flexibility outside of survey instruments and opens new avenues of inquiry for populations difficult to survey. Additionally, it works with documents of varying length, and produces valid estimates of both mass and elite ideology. I demonstrate that the method can differentiate between policy preferences and in-group/out-group affect. Among the public, Semantic Scaling out-preforms Tweetscores according to human judgement; in Congress, it recaptures the first dimension DW-NOMINATE while allowing for greater flexibility in resolving construct validity challenges.
Read more5/7/2024
0
Scaling Properties of Speech Language Models
Santiago Cuervo, Ricard Marxer
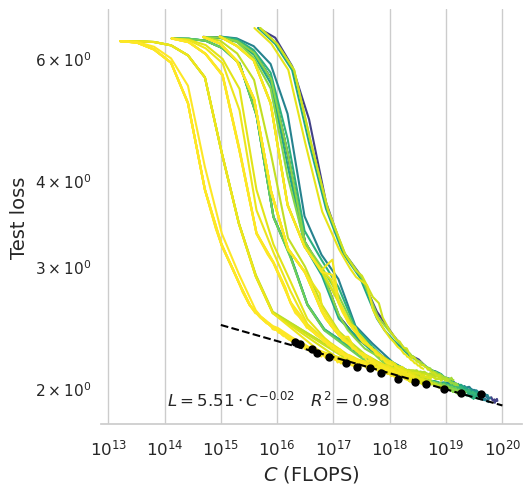
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
Read more4/17/2024
🧠
0
Measurement in the Age of LLMs: An Application to Ideological Scaling
Sean O'Hagan, Aaron Schein
Much of social science is centered around terms like ``ideology'' or ``power'', which generally elude precise definition, and whose contextual meanings are trapped in surrounding language. This paper explores the use of large language models (LLMs) to flexibly navigate the conceptual clutter inherent to social scientific measurement tasks. We rely on LLMs' remarkable linguistic fluency to elicit ideological scales of both legislators and text, which accord closely to established methods and our own judgement. A key aspect of our approach is that we elicit such scores directly, instructing the LLM to furnish numeric scores itself. This approach affords a great deal of flexibility, which we showcase through a variety of different case studies. Our results suggest that LLMs can be used to characterize highly subtle and diffuse manifestations of political ideology in text.
Read more4/9/2024
0
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
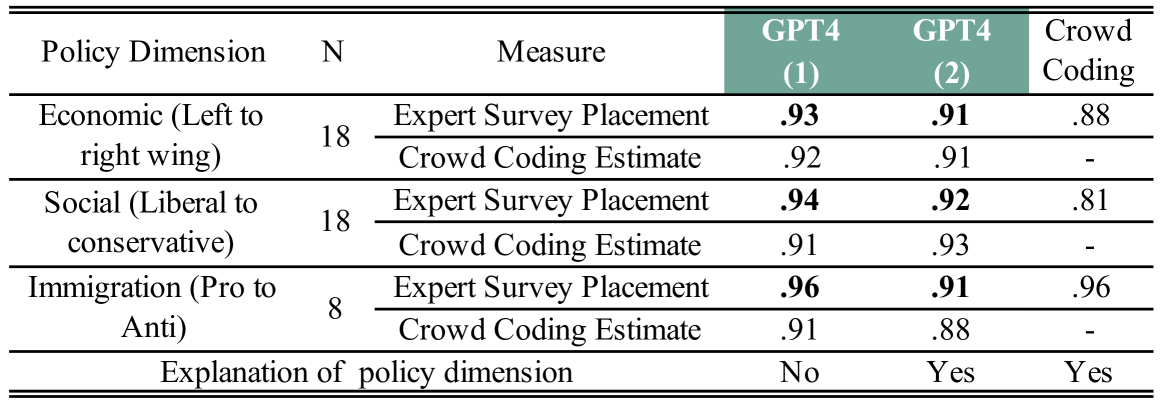
We use instruction-tuned Large Language Models (LLMs) like GPT-4, Llama 3, MiXtral, or Aya to position political texts within policy and ideological spaces. We ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to position political actors such as US Senators, or longer texts such as UK party manifestos or EU policy speeches given in 10 different languages. The correlations between the position estimates obtained with the best LLMs and benchmarks based on text coding by experts, crowdworkers, or roll call votes exceed .90. This approach is generally more accurate than the positions obtained with supervised classifiers trained on large amounts of research data. Using instruction-tuned LLMs to position texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Read more9/6/2024