BackMix: Mitigating Shortcut Learning in Echocardiography with Minimal Supervision

0

Sign in to get full access
Overview
- This paper proposes a new technique called BackMix to mitigate the problem of shortcut learning in echocardiography models.
- Shortcut learning refers to models learning spurious correlations in the data rather than the intended underlying patterns.
- BackMix is a data augmentation technique that aims to force the model to learn more robust features by mixing echocardiography images with similar but unrelated images.
- The paper demonstrates the effectiveness of BackMix in improving model performance and reducing shortcut learning on echocardiography datasets.
Plain English Explanation
Machine learning models trained on medical images like echocardiograms (ultrasound scans of the heart) can sometimes learn shortcuts - picking up on unintended patterns in the data that don't actually reflect the true underlying condition they're trying to diagnose. This can lead to models that perform well on the training data but fail to generalize to new, unseen cases.
The researchers behind this paper developed a new technique called BackMix to help address this problem. The key idea is to force the model to learn more robust features by mixing the echocardiogram images it trains on with similar but unrelated images, like pictures of other body parts.
This makes it harder for the model to latch onto superficial shortcuts, and instead encourages it to focus on the truly relevant patterns in the echocardiogram data. The paper shows that using BackMix leads to models that not only perform better on standard evaluation metrics, but are also less susceptible to shortcut learning issues that could cause problems in real-world deployment.
Technical Explanation
The BackMix technique works by taking an echocardiogram image and a similarly sized but unrelated image (e.g. an X-ray of a different body part), and blending them together to create a new training example. The model is then asked to predict the label associated with the echocardiogram portion of the mixed image.
This forces the model to look beyond superficial image characteristics and instead focus on the true underlying patterns in the echocardiogram data that are relevant to the task at hand. The paper demonstrates the effectiveness of BackMix through experiments on several echocardiography datasets, showing improved performance and reduced susceptibility to shortcut learning issues compared to standard training approaches.
The authors also explore semi-supervised learning techniques as a way to further boost performance when limited labeled data is available, and discuss connections to the broader challenge of shortcut learning in medical image segmentation.
Critical Analysis
The paper provides a compelling solution to the important problem of shortcut learning in echocardiography models. By introducing the BackMix technique, the authors demonstrate a practical way to force models to learn more robust features.
However, the paper does not delve into the potential limitations or failure modes of the approach. For instance, it's unclear how well BackMix would scale to more diverse or complex medical imaging datasets, or how it might interact with other data augmentation techniques like controllable echocardiography video synthesis.
Additionally, the paper does not address potential concerns around the calibration of mixed data or the interpretability of models trained with BackMix. These are important practical considerations that could impact the real-world deployment of such techniques.
Overall, the paper presents a valuable contribution to the field, but further research is needed to fully understand the limitations and broader implications of the BackMix approach.
Conclusion
This paper introduces a new data augmentation technique called BackMix that aims to mitigate the problem of shortcut learning in echocardiography models. By mixing echocardiogram images with unrelated images, the technique forces the model to learn more robust features, leading to improved performance and reduced susceptibility to spurious correlations.
The results demonstrate the effectiveness of BackMix on several echocardiography datasets, and the authors also explore the use of semi-supervised learning techniques to further boost performance. This work has important implications for the development of reliable and trustworthy medical imaging models, which is crucial for their widespread adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BackMix: Mitigating Shortcut Learning in Echocardiography with Minimal Supervision
Kit Mills Bransby, Arian Beqiri, Woo-Jin Cho Kim, Jorge Oliveira, Agisilaos Chartsias, Alberto Gomez
Neural networks can learn spurious correlations that lead to the correct prediction in a validation set, but generalise poorly because the predictions are right for the wrong reason. This undesired learning of naive shortcuts (Clever Hans effect) can happen for example in echocardiogram view classification when background cues (e.g. metadata) are biased towards a class and the model learns to focus on those background features instead of on the image content. We propose a simple, yet effective random background augmentation method called BackMix, which samples random backgrounds from other examples in the training set. By enforcing the background to be uncorrelated with the outcome, the model learns to focus on the data within the ultrasound sector and becomes invariant to the regions outside this. We extend our method in a semi-supervised setting, finding that the positive effects of BackMix are maintained with as few as 5% of segmentation labels. A loss weighting mechanism, wBackMix, is also proposed to increase the contribution of the augmented examples. We validate our method on both in-distribution and out-of-distribution datasets, demonstrating significant improvements in classification accuracy, region focus and generalisability. Our source code is available at: https://github.com/kitbransby/BackMix
Read more6/28/2024

0
Multi-Site Class-Incremental Learning with Weighted Experts in Echocardiography
Kit M. Bransby, Woo-jin Cho Kim, Jorge Oliveira, Alex Thorley, Arian Beqiri, Alberto Gomez, Agisilaos Chartsias
Building an echocardiography view classifier that maintains performance in real-life cases requires diverse multi-site data, and frequent updates with newly available data to mitigate model drift. Simply fine-tuning on new datasets results in catastrophic forgetting, and cannot adapt to variations of view labels between sites. Alternatively, collecting all data on a single server and re-training may not be feasible as data sharing agreements may restrict image transfer, or datasets may only become available at different times. Furthermore, time and cost associated with re-training grows with every new dataset. We propose a class-incremental learning method which learns an expert network for each dataset, and combines all expert networks with a score fusion model. The influence of ``unqualified experts'' is minimised by weighting each contribution with a learnt in-distribution score. These weights promote transparency as the contribution of each expert is known during inference. Instead of using the original images, we use learned features from each dataset, which are easier to share and raise fewer licensing and privacy concerns. We validate our work on six datasets from multiple sites, demonstrating significant reductions in training time while improving view classification performance.
Read more8/1/2024

0
Label Dropout: Improved Deep Learning Echocardiography Segmentation Using Multiple Datasets With Domain Shift and Partial Labelling
Iman Islam (King's College London), Esther Puyol-Ant'on (King's College London), Bram Ruijsink (King's College London), Andrew J. Reader (King's College London), Andrew P. King (King's College London)
Echocardiography (echo) is the first imaging modality used when assessing cardiac function. The measurement of functional biomarkers from echo relies upon the segmentation of cardiac structures and deep learning models have been proposed to automate the segmentation process. However, in order to translate these tools to widespread clinical use it is important that the segmentation models are robust to a wide variety of images (e.g. acquired from different scanners, by operators with different levels of expertise etc.). To achieve this level of robustness it is necessary that the models are trained with multiple diverse datasets. A significant challenge faced when training with multiple diverse datasets is the variation in label presence, i.e. the combined data are often partially-labelled. Adaptations of the cross entropy loss function have been proposed to deal with partially labelled data. In this paper we show that training naively with such a loss function and multiple diverse datasets can lead to a form of shortcut learning, where the model associates label presence with domain characteristics, leading to a drop in performance. To address this problem, we propose a novel label dropout scheme to break the link between domain characteristics and the presence or absence of labels. We demonstrate that label dropout improves echo segmentation Dice score by 62% and 25% on two cardiac structures when training using multiple diverse partially labelled datasets.
Read more8/16/2024
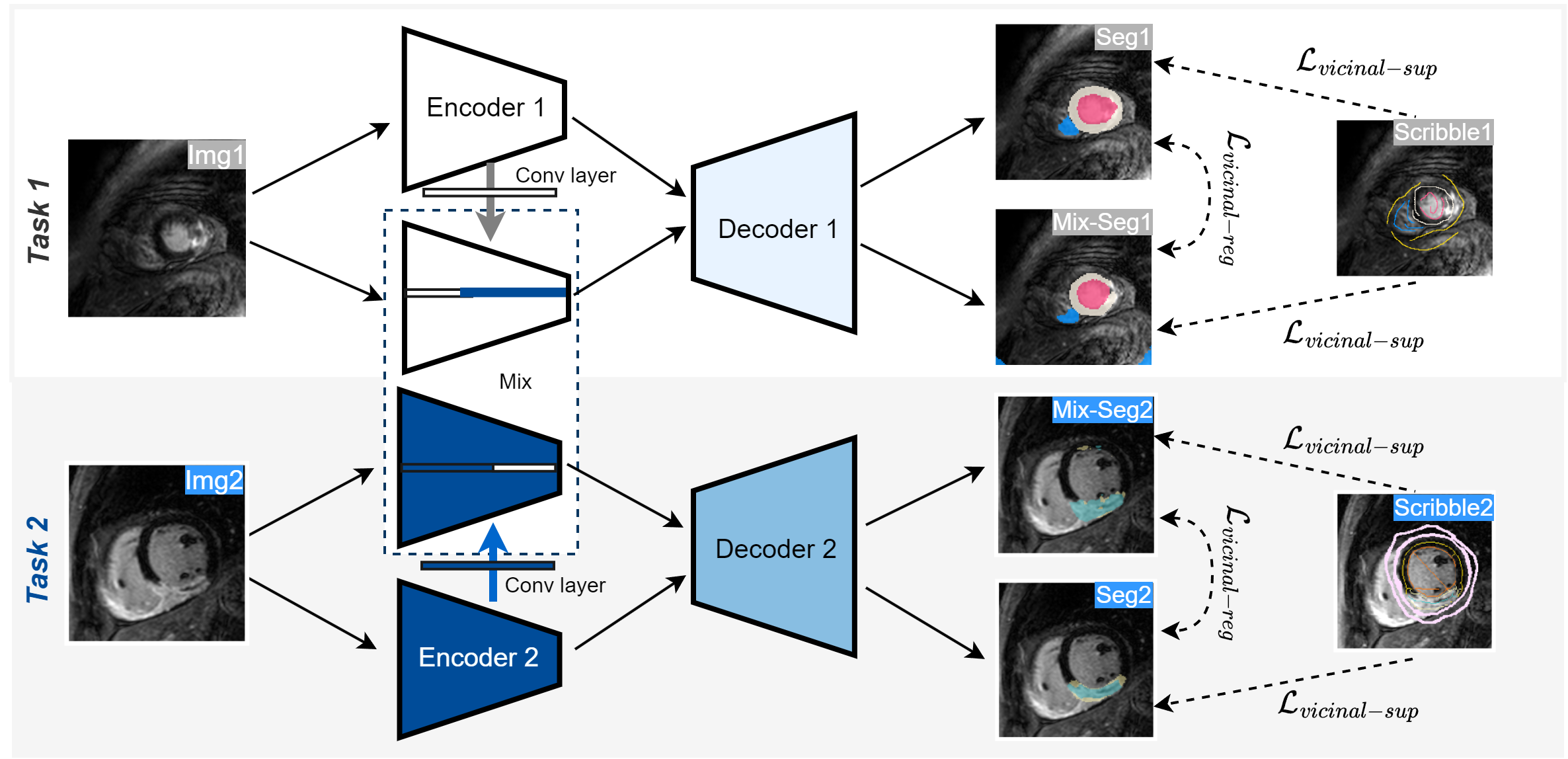
0
ModelMix: A New Model-Mixup Strategy to Minimize Vicinal Risk across Tasks for Few-scribble based Cardiac Segmentation
Ke Zhang, Vishal M. Patel
Pixel-level dense labeling is both resource-intensive and time-consuming, whereas weak labels such as scribble present a more feasible alternative to full annotations. However, training segmentation networks with weak supervision from scribbles remains challenging. Inspired by the fact that different segmentation tasks can be correlated with each other, we introduce a new approach to few-scribble supervised segmentation based on model parameter interpolation, termed as ModelMix. Leveraging the prior knowledge that linearly interpolating convolution kernels and bias terms should result in linear interpolations of the corresponding feature vectors, ModelMix constructs virtual models using convex combinations of convolutional parameters from separate encoders. We then regularize the model set to minimize vicinal risk across tasks in both unsupervised and scribble-supervised way. Validated on three open datasets, i.e., ACDC, MSCMRseg, and MyoPS, our few-scribble guided ModelMix significantly surpasses the performance of the state-of-the-art scribble supervised methods.
Read more6/21/2024