ModelMix: A New Model-Mixup Strategy to Minimize Vicinal Risk across Tasks for Few-scribble based Cardiac Segmentation

0
Sign in to get full access
Overview
- Introduces a new model-mixup strategy called "ModelMix" for few-scribble based cardiac segmentation
- Aims to minimize the vicinal risk (risk of misclassification for samples near the decision boundary) across multiple tasks
- Uses a combination of generative and discriminative mixup techniques to augment the training data
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/pclmix-weakly-supervised-medical-image-segmentation-via">Weakly supervised learning</a> techniques like scribble annotations can be used to efficiently annotate medical images for segmentation tasks. However, the limited annotations can lead to high vicinal risk - the risk of misclassifying samples near the decision boundary.
The proposed <a href="https://aimodels.fyi/papers/arxiv/tailoring-mixup-to-data-calibration">ModelMix</a> strategy combines <a href="https://aimodels.fyi/papers/arxiv/mixup-augmentation-multiple-interpolations">generative and discriminative mixup approaches</a> to generate new training samples that help minimize this vicinal risk. By mixing both input images and their corresponding segmentation maps, the model learns robust features that generalize well to unseen data.
This technique can be particularly useful for <a href="https://aimodels.fyi/papers/arxiv/scribbleprompt-fast-flexible-interactive-segmentation-any-biomedical">few-scribble based cardiac segmentation</a>, where only limited annotations are available. The resulting model can accurately segment the heart structure from CT or MRI images with high reliability.
Technical Explanation
The key idea behind the <a href="https://aimodels.fyi/papers/arxiv/tailoring-mixup-to-data-calibration">ModelMix</a> strategy is to combine <a href="https://aimodels.fyi/papers/arxiv/mixup-augmentation-multiple-interpolations">generative and discriminative mixup techniques</a> to create new training samples that help the model learn robust features.
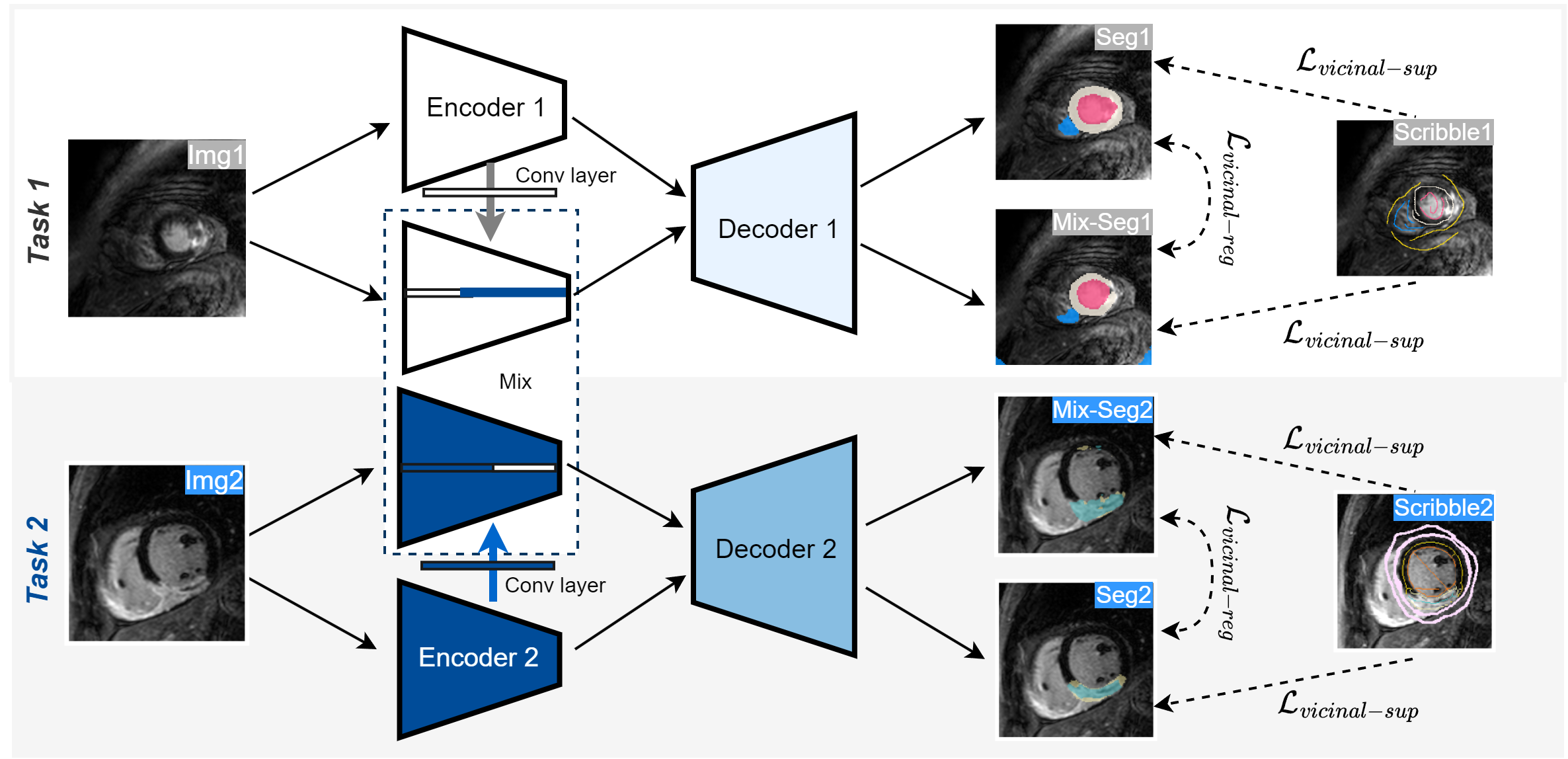
Generative mixup generates new images by linearly interpolating between pairs of input images. Discriminative mixup generates new segmentation maps by linearly interpolating between the corresponding segmentation maps. By applying these techniques together, the model learns to associate the intermediate features in the input images with the appropriate intermediate segmentation outputs.
This helps the model become more resilient to samples near the decision boundary, reducing the overall vicinal risk across multiple segmentation tasks. The authors demonstrate the effectiveness of ModelMix on a few-scribble based cardiac segmentation dataset, where it outperforms other state-of-the-art methods.
Critical Analysis
The authors acknowledge that the ModelMix strategy relies on the assumption that the intermediate feature representations and segmentation outputs can be linearly interpolated. This may not always hold true, especially for more complex medical images and segmentation tasks.
Additionally, the paper does not explore the impact of different mixup hyperparameters or the trade-offs between generative and discriminative mixup techniques. Further research could investigate these aspects to optimize the ModelMix approach for specific applications.
<a href="https://aimodels.fyi/papers/arxiv/genmix-combining-generative-mixture-data-augmentation-medical">Other data augmentation strategies</a> that combine generative and discriminative techniques could also be explored and compared to the ModelMix approach to understand its relative strengths and weaknesses.
Conclusion
The ModelMix strategy proposed in this paper provides a promising approach to improve the performance of few-scribble based medical image segmentation models. By leveraging a combination of generative and discriminative mixup techniques, the model can learn robust features that help minimize the vicinal risk across multiple segmentation tasks.
This work highlights the potential of using advanced data augmentation methods to address the challenges of limited annotations in medical imaging applications. Further research and refinement of the ModelMix approach could lead to even more robust and reliable segmentation models, with significant implications for clinical decision-making and patient care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ModelMix: A New Model-Mixup Strategy to Minimize Vicinal Risk across Tasks for Few-scribble based Cardiac Segmentation
Ke Zhang, Vishal M. Patel
Pixel-level dense labeling is both resource-intensive and time-consuming, whereas weak labels such as scribble present a more feasible alternative to full annotations. However, training segmentation networks with weak supervision from scribbles remains challenging. Inspired by the fact that different segmentation tasks can be correlated with each other, we introduce a new approach to few-scribble supervised segmentation based on model parameter interpolation, termed as ModelMix. Leveraging the prior knowledge that linearly interpolating convolution kernels and bias terms should result in linear interpolations of the corresponding feature vectors, ModelMix constructs virtual models using convex combinations of convolutional parameters from separate encoders. We then regularize the model set to minimize vicinal risk across tasks in both unsupervised and scribble-supervised way. Validated on three open datasets, i.e., ACDC, MSCMRseg, and MyoPS, our few-scribble guided ModelMix significantly surpasses the performance of the state-of-the-art scribble supervised methods.
Read more6/21/2024

0
MixPolyp: Integrating Mask, Box and Scribble Supervision for Enhanced Polyp Segmentation
Yiwen Hu, Jun Wei, Yuncheng Jiang, Haoyang Li, Shuguang Cui, Zhen Li, Song Wu
Limited by the expensive labeling, polyp segmentation models are plagued by data shortages. To tackle this, we propose the mixed supervised polyp segmentation paradigm (MixPolyp). Unlike traditional models relying on a single type of annotation, MixPolyp combines diverse annotation types (mask, box, and scribble) within a single model, thereby expanding the range of available data and reducing labeling costs. To achieve this, MixPolyp introduces three novel supervision losses to handle various annotations: Subspace Projection loss (L_SP), Binary Minimum Entropy loss (L_BME), and Linear Regularization loss (L_LR). For box annotations, L_SP eliminates shape inconsistencies between the prediction and the supervision. For scribble annotations, L_BME provides supervision for unlabeled pixels through minimum entropy constraint, thereby alleviating supervision sparsity. Furthermore, L_LR provides dense supervision by enforcing consistency among the predictions, thus reducing the non-uniqueness. These losses are independent of the model structure, making them generally applicable. They are used only during training, adding no computational cost during inference. Extensive experiments on five datasets demonstrate MixPolyp's effectiveness.
Read more9/26/2024
0
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Read more5/21/2024

0
From Few to More: Scribble-based Medical Image Segmentation via Masked Context Modeling and Continuous Pseudo Labels
Zhisong Wang, Yiwen Ye, Ziyang Chen, Minglei Shu, Yong Xia
Scribble-based weakly supervised segmentation techniques offer comparable performance to fully supervised methods while significantly reducing annotation costs, making them an appealing alternative. Existing methods often rely on auxiliary tasks to enforce semantic consistency and use hard pseudo labels for supervision. However, these methods often overlook the unique requirements of models trained with sparse annotations. Since the model must predict pixel-wise segmentation maps with limited annotations, the ability to handle varying levels of annotation richness is critical. In this paper, we adopt the principle of `from few to more' and propose MaCo, a weakly supervised framework designed for medical image segmentation. MaCo employs masked context modeling (MCM) and continuous pseudo labels (CPL). MCM uses an attention-based masking strategy to disrupt the input image, compelling the model's predictions to remain consistent with those of the original image. CPL converts scribble annotations into continuous pixel-wise labels by applying an exponential decay function to distance maps, resulting in continuous maps that represent the confidence of each pixel belonging to a specific category, rather than using hard pseudo labels. We evaluate MaCo against other weakly supervised methods using three public datasets. The results indicate that MaCo outperforms competing methods across all datasets, setting a new record in weakly supervised medical image segmentation.
Read more8/26/2024