Balanced Data, Imbalanced Spectra: Unveiling Class Disparities with Spectral Imbalance

0
🌐
Sign in to get full access
Overview
- Classification models are expected to perform equally well across different classes, but often have large gaps in their performance.
- This issue of class bias is well-studied in datasets with sample imbalance, but less so in balanced datasets.
- The paper introduces the concept of "spectral imbalance" in features as a potential source of class disparities and explores its connections with class bias.
Plain English Explanation
Machine learning models are designed to treat all classes or categories equally, but in practice, they often perform much better on some classes than others. This problem of "class bias" is well-known when the training data is imbalanced, meaning there are many more examples of some classes than others. However, it can also occur even in datasets that are balanced, with equal numbers of examples per class.
The researchers in this paper propose that a key reason for this class bias is something they call "spectral imbalance" in the features used by the model. The "spectrum" refers to the range and distribution of values in the data's features, and if this spectrum is very different between classes, it can lead to the model struggling more with some classes.
To understand this better, the researchers develop a theoretical framework for studying class disparities, and apply it to analyze 11 different state-of-the-art machine learning models. They show how this framework can be used to compare the quality of different models, as well as evaluate and combine data augmentation strategies to help reduce the class bias problem.
Overall, this work sheds new light on how the underlying structure of the data can lead to unexpected biases in how machine learning models perform across different classes, even in seemingly balanced datasets. By understanding these spectral imbalances, researchers may be able to develop better techniques to adaptively adjust for class imbalances and improve the fairness of these models.
Technical Explanation
The paper introduces the concept of "spectral imbalance" in features as a potential source of class disparities in classification models. The researchers develop a theoretical framework to study the connections between spectral imbalance and class bias in both theory and practice.
Theoretical Framework: The paper derives exact expressions for the per-class error in a high-dimensional mixture model setting, relating class disparities to properties of the underlying feature distributions. This provides a principled way to understand the sources of class bias.
Empirical Analysis: The researchers apply this framework to analyze 11 different state-of-the-art pretrained encoders. They show how the framework can be used to compare the quality of encoders and evaluate data augmentation strategies to mitigate class bias.
The key findings are:
- Spectral imbalance in features is a significant source of class bias, even in balanced datasets.
- The proposed framework allows quantifying and diagnosing class-dependent effects of learning.
- It reveals unknown biases in state-of-the-art pretrained features that can be addressed through data augmentation.
Critical Analysis
The paper provides a novel and insightful theoretical framework for understanding class bias in classification models. By focusing on the role of spectral imbalance in features, it sheds light on an important but often overlooked source of bias.
However, the paper does not address some potential limitations of this framework. For example, it is unclear how sensitive the results are to the specific choice of mixture model or whether the conclusions would hold for other model architectures beyond the pretrained encoders studied.
Additionally, while the paper demonstrates the utility of the framework for evaluating data augmentation strategies, it does not provide a comprehensive solution for mitigating class bias. Further research may be needed to develop more robust and generalizable techniques for addressing this issue.
Overall, this work makes an important contribution by highlighting the limitations of data-driven spectral reconstruction and introducing a new perspective on how spectral cues may matter for contrast-based learning. It paves the way for future studies on class-dependent effects in machine learning and the development of more equitable and unbiased models.
Conclusion
This paper introduces the concept of spectral imbalance in features as a key source of class bias in classification models, even in balanced datasets. By developing a theoretical framework to study this phenomenon, the researchers provide new insights into how state-of-the-art machine learning models may have unknown biases that can be diagnosed through their feature spectra.
The findings have important implications for the development of fair and equitable machine learning systems. By understanding the role of spectral imbalance, researchers and practitioners may be able to design more robust data augmentation strategies and other techniques to mitigate class bias. This work represents an important step towards building machine learning models that perform equally well for all classes, regardless of the underlying data distribution.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Balanced Data, Imbalanced Spectra: Unveiling Class Disparities with Spectral Imbalance
Chiraag Kaushik, Ran Liu, Chi-Heng Lin, Amrit Khera, Matthew Y Jin, Wenrui Ma, Vidya Muthukumar, Eva L Dyer
Classification models are expected to perform equally well for different classes, yet in practice, there are often large gaps in their performance. This issue of class bias is widely studied in cases of datasets with sample imbalance, but is relatively overlooked in balanced datasets. In this work, we introduce the concept of spectral imbalance in features as a potential source for class disparities and study the connections between spectral imbalance and class bias in both theory and practice. To build the connection between spectral imbalance and class gap, we develop a theoretical framework for studying class disparities and derive exact expressions for the per-class error in a high-dimensional mixture model setting. We then study this phenomenon in 11 different state-of-the-art pretrained encoders and show how our proposed framework can be used to compare the quality of encoders, as well as evaluate and combine data augmentation strategies to mitigate the issue. Our work sheds light on the class-dependent effects of learning, and provides new insights into how state-of-the-art pretrained features may have unknown biases that can be diagnosed through their spectra.
Read more6/4/2024

0
Learning Confidence Bounds for Classification with Imbalanced Data
Matt Clifford, Jonathan Erskine, Alexander Hepburn, Ra'ul Santos-Rodr'iguez, Dario Garcia-Garcia
Class imbalance poses a significant challenge in classification tasks, where traditional approaches often lead to biased models and unreliable predictions. Undersampling and oversampling techniques have been commonly employed to address this issue, yet they suffer from inherent limitations stemming from their simplistic approach such as loss of information and additional biases respectively. In this paper, we propose a novel framework that leverages learning theory and concentration inequalities to overcome the shortcomings of traditional solutions. We focus on understanding the uncertainty in a class-dependent manner, as captured by confidence bounds that we directly embed into the learning process. By incorporating class-dependent estimates, our method can effectively adapt to the varying degrees of imbalance across different classes, resulting in more robust and reliable classification outcomes. We empirically show how our framework provides a promising direction for handling imbalanced data in classification tasks, offering practitioners a valuable tool for building more accurate and trustworthy models.
Read more10/2/2024
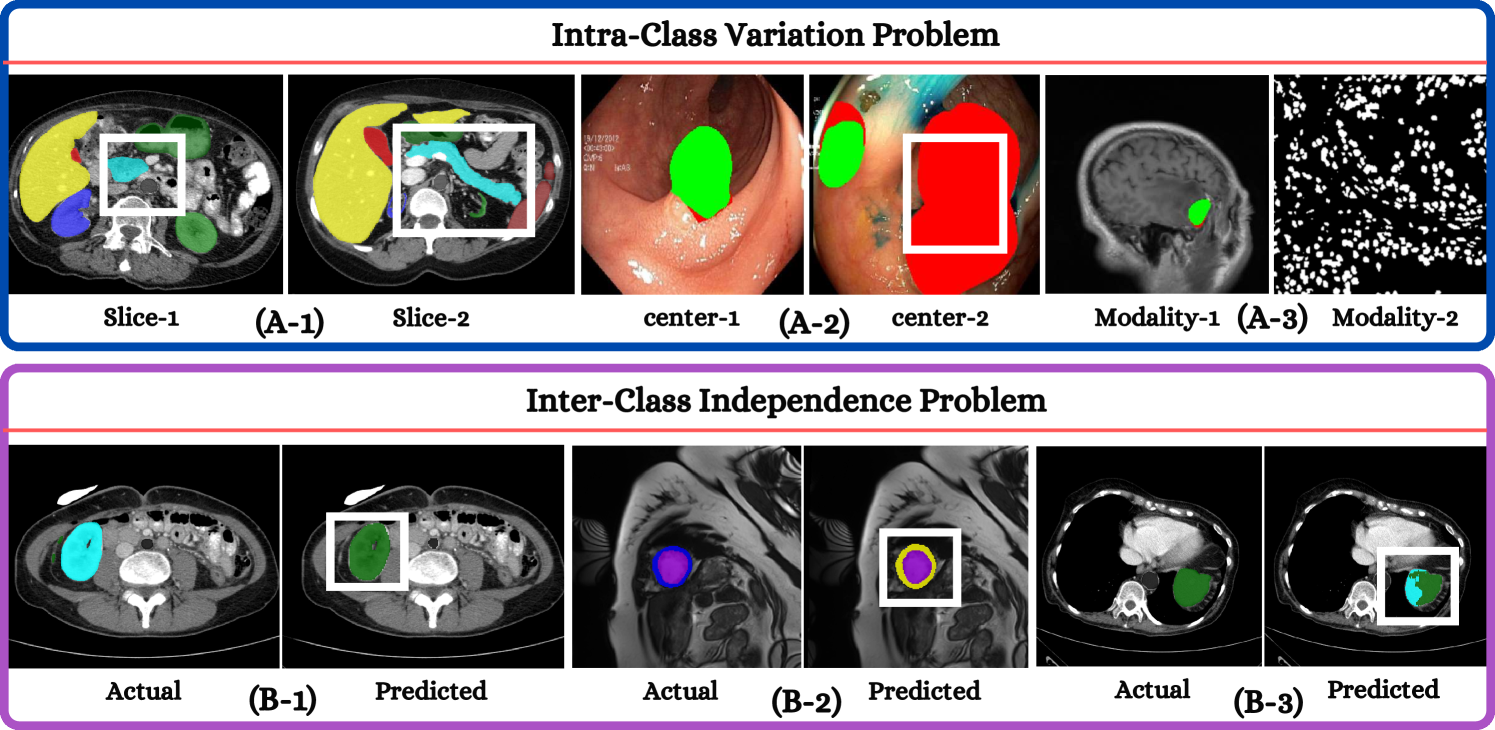
0
Harmonized Spatial and Spectral Learning for Robust and Generalized Medical Image Segmentation
Vandan Gorade, Sparsh Mittal, Debesh Jha, Rekha Singhal, Ulas Bagci
Deep learning has demonstrated remarkable achievements in medical image segmentation. However, prevailing deep learning models struggle with poor generalization due to (i) intra-class variations, where the same class appears differently in different samples, and (ii) inter-class independence, resulting in difficulties capturing intricate relationships between distinct objects, leading to higher false negative cases. This paper presents a novel approach that synergies spatial and spectral representations to enhance domain-generalized medical image segmentation. We introduce the innovative Spectral Correlation Coefficient objective to improve the model's capacity to capture middle-order features and contextual long-range dependencies. This objective complements traditional spatial objectives by incorporating valuable spectral information. Extensive experiments reveal that optimizing this objective with existing architectures like UNet and TransUNet significantly enhances generalization, interpretability, and noise robustness, producing more confident predictions. For instance, in cardiac segmentation, we observe a 0.81 pp and 1.63 pp (pp = percentage point) improvement in DSC over UNet and TransUNet, respectively. Our interpretability study demonstrates that, in most tasks, objectives optimized with UNet outperform even TransUNet by introducing global contextual information alongside local details. These findings underscore the versatility and effectiveness of our proposed method across diverse imaging modalities and medical domains.
Read more8/9/2024

0
Approaching Deep Learning through the Spectral Dynamics of Weights
David Yunis, Kumar Kshitij Patel, Samuel Wheeler, Pedro Savarese, Gal Vardi, Karen Livescu, Michael Maire, Matthew R. Walter
We propose an empirical approach centered on the spectral dynamics of weights -- the behavior of singular values and vectors during optimization -- to unify and clarify several phenomena in deep learning. We identify a consistent bias in optimization across various experiments, from small-scale ``grokking'' to large-scale tasks like image classification with ConvNets, image generation with UNets, speech recognition with LSTMs, and language modeling with Transformers. We also demonstrate that weight decay enhances this bias beyond its role as a norm regularizer, even in practical systems. Moreover, we show that these spectral dynamics distinguish memorizing networks from generalizing ones, offering a novel perspective on this longstanding conundrum. Additionally, we leverage spectral dynamics to explore the emergence of well-performing sparse subnetworks (lottery tickets) and the structure of the loss surface through linear mode connectivity. Our findings suggest that spectral dynamics provide a coherent framework to better understand the behavior of neural networks across diverse settings.
Read more8/22/2024