BAMM: Bidirectional Autoregressive Motion Model
2403.19435
0
0

Abstract
Generating human motion from text has been dominated by denoising motion models either through diffusion or generative masking process. However, these models face great limitations in usability by requiring prior knowledge of the motion length. Conversely, autoregressive motion models address this limitation by adaptively predicting motion endpoints, at the cost of degraded generation quality and editing capabilities. To address these challenges, we propose Bidirectional Autoregressive Motion Model (BAMM), a novel text-to-motion generation framework. BAMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into discrete tokens in latent space, and (2) a masked self-attention transformer that autoregressively predicts randomly masked tokens via a hybrid attention masking strategy. By unifying generative masked modeling and autoregressive modeling, BAMM captures rich and bidirectional dependencies among motion tokens, while learning the probabilistic mapping from textual inputs to motion outputs with dynamically-adjusted motion sequence length. This feature enables BAMM to simultaneously achieving high-quality motion generation with enhanced usability and built-in motion editability. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that BAMM surpasses current state-of-the-art methods in both qualitative and quantitative measures. Our project page is available at https://github.com/exitudio/BAMM-page.
Create account to get full access
Overview
- This paper introduces a new Bidirectional Autoregressive Motion Model (BAMM) for generating realistic human motion sequences from text inputs.
- BAMM is a generative model that can translate natural language descriptions into corresponding 3D skeletal motion.
- The key innovation is the use of a bidirectional autoregressive architecture, which allows the model to capture complex dependencies in the motion data.
- Experiments show BAMM outperforming previous state-of-the-art text-to-motion models on benchmark datasets.
Plain English Explanation
BAMM is a new AI system that can take a written description of an action or movement and translate that into a realistic 3D animation of a human figure performing that action. For example, you could give it the text "the person is walking briskly down the street" and it would generate a smooth, natural-looking animation of a person walking in that way.
The core innovation in BAMM is its "bidirectional autoregressive" architecture. This means the model looks at the entire sequence of motion it's trying to generate, both forwards and backwards, to understand the complex relationships and dependencies between different parts of the movement. Previous text-to-motion models were more limited in their ability to capture these nuanced dynamics.
By modeling motion in this more sophisticated way, BAMM is able to produce significantly more realistic and natural-looking animations from text compared to prior approaches. This has exciting applications in areas like filmmaking, video game development, and human-computer interaction, where generating believable human movement from language is highly valuable.
Technical Explanation
BAMM is a deep learning model that takes in a text description as input and outputs a sequence of 3D skeletal poses representing the corresponding human motion. The key architectural elements are:
- Encoder: A transformer-based text encoder that encodes the input text description into a compact vector representation.
- Bidirectional Autoregressive Decoder: A recurrent neural network with long short-term memory (LSTM) cells that generates the motion sequence one pose at a time, looking at the entire sequence both forwards and backwards to capture complex dependencies.
- Masked Motion Model: During training, BAMM learns to predict missing motion frames in a sequence, forcing the model to learn a holistic understanding of the motion dynamics.
Experiments on public benchmark datasets show that BAMM outperforms previous state-of-the-art text-to-motion models in terms of quantitative metrics like joint position error and perceptual realism as judged by human evaluators. Ablation studies confirm the importance of the bidirectional autoregressive architecture and masked motion training.
Critical Analysis
The paper provides a thorough technical description of the BAMM architecture and rigorous experimental validation of its capabilities. However, some potential limitations and areas for future work are not discussed:
- The training and evaluation are limited to short motion sequences of around 20-30 frames. It's unclear how well BAMM would scale to generating longer, more complex motion trajectories.
- The model is only trained and evaluated on motion capture data of single characters. Extending it to handle multiple interacting characters or full-body animation with clothing/props would be an interesting next step.
- While BAMM outperforms prior methods, there is still room for improvement in terms of motion realism and coherence, especially for more nuanced or subtle movements.
- The paper does not address potential ethical concerns around the use of such text-to-motion technology, such as the creation of misleading "deepfake" animations.
Overall, BAMM represents a promising advance in text-to-motion generation, but further research is needed to fully realize the potential of this technology.
Conclusion
The Bidirectional Autoregressive Motion Model (BAMM) introduced in this paper is a significant step forward in the field of text-to-motion generation. By leveraging a sophisticated bidirectional autoregressive architecture, BAMM is able to generate substantially more realistic and natural-looking human motion from textual descriptions compared to previous state-of-the-art approaches.
This advancement has exciting implications for a variety of applications, from filmmaking and gaming to human-computer interaction and virtual reality. As the technology continues to improve, we may see text-to-motion systems become increasingly ubiquitous, transforming the way we create and interact with digital content.
However, the research also raises important questions about the ethical considerations of such generative technologies, particularly around the potential for misuse. Further work is needed to address these concerns and ensure that text-to-motion models are developed and deployed responsibly.
Overall, the BAMM paper represents an important contribution to the field of motion modeling and generation, with the potential to have a significant impact on how we create and experience digital content in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Bidirectional Autoregressive Diffusion Model for Dance Generation
Canyu Zhang, Youbao Tang, Ning Zhang, Ruei-Sung Lin, Mei Han, Jing Xiao, Song Wang
0
0
Dance serves as a powerful medium for expressing human emotions, but the lifelike generation of dance is still a considerable challenge. Recently, diffusion models have showcased remarkable generative abilities across various domains. They hold promise for human motion generation due to their adaptable many-to-many nature. Nonetheless, current diffusion-based motion generation models often create entire motion sequences directly and unidirectionally, lacking focus on the motion with local and bidirectional enhancement. When choreographing high-quality dance movements, people need to take into account not only the musical context but also the nearby music-aligned dance motions. To authentically capture human behavior, we propose a Bidirectional Autoregressive Diffusion Model (BADM) for music-to-dance generation, where a bidirectional encoder is built to enforce that the generated dance is harmonious in both the forward and backward directions. To make the generated dance motion smoother, a local information decoder is built for local motion enhancement. The proposed framework is able to generate new motions based on the input conditions and nearby motions, which foresees individual motion slices iteratively and consolidates all predictions. To further refine the synchronicity between the generated dance and the beat, the beat information is incorporated as an input to generate better music-aligned dance movements. Experimental results demonstrate that the proposed model achieves state-of-the-art performance compared to existing unidirectional approaches on the prominent benchmark for music-to-dance generation.
6/26/2024

Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
0
0
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
5/27/2024
🐍
Taming Diffusion Probabilistic Models for Character Control
Rui Chen, Mingyi Shi, Shaoli Huang, Ping Tan, Taku Komura, Xuelin Chen
0
0
We present a novel character control framework that effectively utilizes motion diffusion probabilistic models to generate high-quality and diverse character animations, responding in real-time to a variety of dynamic user-supplied control signals. At the heart of our method lies a transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the character's historical motion and can generate a range of diverse potential future motions conditioned on high-level, coarse user control. To meet the demands for diversity, controllability, and computational efficiency required by a real-time controller, we incorporate several key algorithmic designs. These include separate condition tokenization, classifier-free guidance on past motion, and heuristic future trajectory extension, all designed to address the challenges associated with taming motion diffusion probabilistic models for character control. As a result, our work represents the first model that enables real-time generation of high-quality, diverse character animations based on user interactive control, supporting animating the character in multiple styles with a single unified model. We evaluate our method on a diverse set of locomotion skills, demonstrating the merits of our method over existing character controllers. Project page and source codes: https://aiganimation.github.io/CAMDM/
4/24/2024
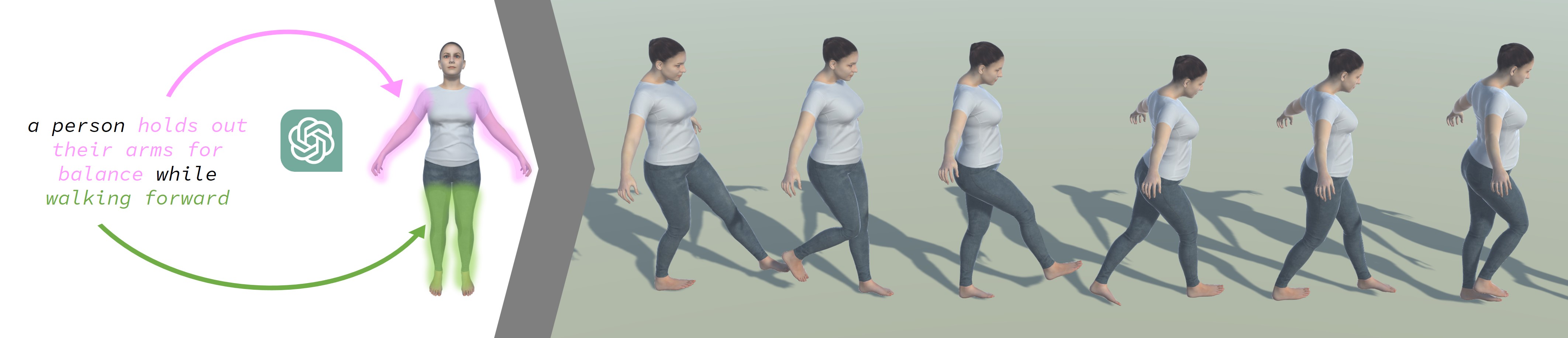
LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
Haowen Sun, Ruikun Zheng, Haibin Huang, Chongyang Ma, Hui Huang, Ruizhen Hu
0
0
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
5/7/2024