LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
2405.03485
0
0
Abstract
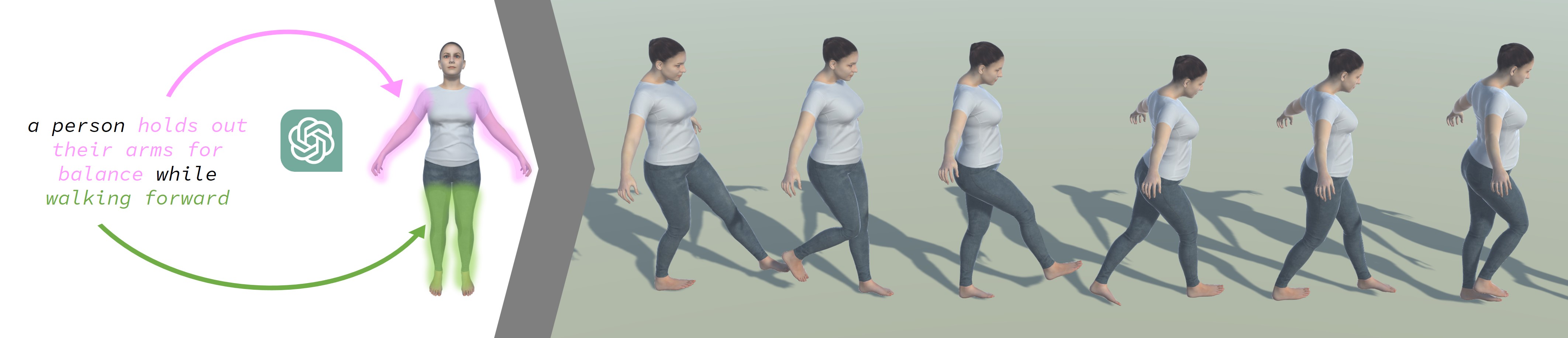
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
Create account to get full access
Overview
- This paper introduces LGTM, a novel diffusion-based model for generating human motion driven by textual descriptions.
- The model learns to synthesize realistic and diverse human motions by leveraging a two-stage architecture that captures both local and global motion patterns.
- LGTM is trained on a large dataset of motion capture data paired with text captions, enabling it to generate motions that align with user-provided descriptions.
Plain English Explanation
The LGTM model is a powerful tool for creating human motion animations based on text descriptions. It works by first learning the local, detailed movements of the body, and then combining those into larger, global motion patterns. This allows it to generate realistic and varied human motions that match the intent expressed in the text.
To train LGTM, the researchers used a large dataset of motion capture data, where real people's movements were recorded, paired with text descriptions of what the person was doing. By learning from this data, the model can now take a new text prompt, like "a person is dancing joyfully," and automatically synthesize an animation that brings that description to life in a natural and convincing way.
This text-driven motion generation has many potential applications, from creating animations for video games and movies to powering virtual assistants that can respond with appropriate body language. By bridging the gap between language and movement, LGTM represents an important step forward in making human-like animations more accessible and controllable.
Technical Explanation
The core of the LGTM model is a diffusion-based architecture that generates human motions in a two-stage process. The first stage focuses on learning the local, detailed movements of individual body parts, while the second stage combines these local patterns into a global, holistic motion.
Diffusion models work by progressively adding noise to the target data (in this case, motion capture sequences) and then learning to reverse that process to generate new samples. By conditioning the diffusion on the text descriptions, LGTM is able to align the generated motions with the semantic meaning expressed in the language.
The researchers evaluated LGTM on several benchmark datasets, demonstrating that it outperforms previous state-of-the-art text-driven motion synthesis models in terms of both objective metrics and human evaluation of the generated animations. The model was able to capture a wide range of motion styles, from walking and dancing to more expressive gestures, while maintaining coherence with the input text.
Critical Analysis
One potential limitation of the LGTM model is that it relies on a large dataset of motion capture data paired with text descriptions. Acquiring and annotating such a dataset can be a significant challenge, and the model's performance may be constrained by the quality and diversity of the training data.
Additionally, while LGTM demonstrates impressive results on standard benchmarks, its ability to generalize to real-world scenarios with complex, interacting characters and environmental contexts remains to be seen. Extending the model to handle more complex scenes and interactions would be an important area for future research.
Another concern is the potential for text-driven motion synthesis models like LGTM to be used for the creation of misleading or deceptive media, such as fake videos or animations. Careful consideration of the ethical implications and responsible development of such technologies will be crucial as they become more widely adopted.
Conclusion
The LGTM model represents a significant advancement in the field of text-driven motion synthesis, demonstrating the ability to generate realistic and diverse human animations that align with user-provided descriptions. By bridging the gap between language and movement, LGTM opens up new possibilities for applications in areas such as virtual assistants, interactive entertainment, and beyond.
As the research in this domain continues to evolve, it will be important to address the limitations and potential risks of these technologies, while also exploring ways to harness their power for positive societal impact. The LGTM paper lays an important foundation for further advancements in this exciting and rapidly-developing field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
0
0
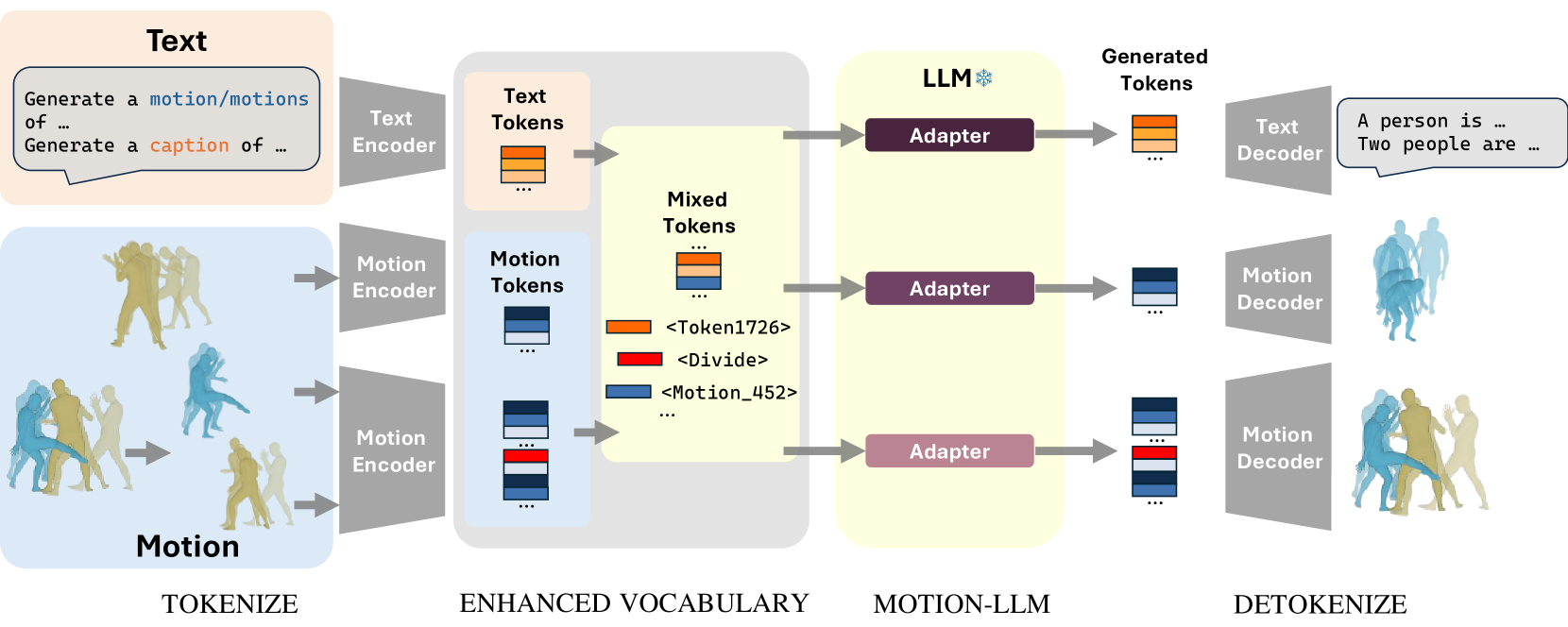
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
5/29/2024

FG-MDM: Towards Zero-Shot Human Motion Generation via Fine-Grained Descriptions
Xu Shi, Wei Yao, Chuanchen Luo, Junran Peng, Hongwen Zhang, Yunlian Sun
0
0
Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, generating motions beyond the distribution of original datasets remains challenging, i.e., zero-shot generation. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for zero-shot human motion generation. Specifically, we first parse previous vague textual annotations into fine-grained descriptions of different body parts by leveraging a large language model. We then use these fine-grained descriptions to guide a transformer-based diffusion model, which further adopts a design of part tokens. FG-MDM can generate human motions beyond the scope of original datasets owing to descriptions that are closer to motion essence. Our experimental results demonstrate the superiority of FG-MDM over previous methods in zero-shot settings. We will release our fine-grained textual annotations for HumanML3D and KIT.
4/24/2024

MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, Lei Zhang
0
0
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
5/31/2024
🛸
T2LM: Long-Term 3D Human Motion Generation from Multiple Sentences
Taeryung Lee, Fabien Baradel, Thomas Lucas, Kyoung Mu Lee, Gregory Rogez
0
0
In this paper, we address the challenging problem of long-term 3D human motion generation. Specifically, we aim to generate a long sequence of smoothly connected actions from a stream of multiple sentences (i.e., paragraph). Previous long-term motion generating approaches were mostly based on recurrent methods, using previously generated motion chunks as input for the next step. However, this approach has two drawbacks: 1) it relies on sequential datasets, which are expensive; 2) these methods yield unrealistic gaps between motions generated at each step. To address these issues, we introduce simple yet effective T2LM, a continuous long-term generation framework that can be trained without sequential data. T2LM comprises two components: a 1D-convolutional VQVAE, trained to compress motion to sequences of latent vectors, and a Transformer-based Text Encoder that predicts a latent sequence given an input text. At inference, a sequence of sentences is translated into a continuous stream of latent vectors. This is then decoded into a motion by the VQVAE decoder; the use of 1D convolutions with a local temporal receptive field avoids temporal inconsistencies between training and generated sequences. This simple constraint on the VQ-VAE allows it to be trained with short sequences only and produces smoother transitions. T2LM outperforms prior long-term generation models while overcoming the constraint of requiring sequential data; it is also competitive with SOTA single-action generation models.
6/4/2024