Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
2308.10783
0
0
⚙️
Abstract
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,606 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper examines the use of sentiment analysis, a technique that helps understand the emotions expressed in text, in low-resource languages like Bangla.
- It presents a large, manually annotated dataset of Bangla news tweets and Facebook comments, which can be used to train and evaluate language models.
- The study investigates the performance of several large language models, including Flan-T5, GPT-4, and Bloomz, in zero-shot and few-shot learning scenarios for Bangla sentiment analysis.
- The findings suggest that monolingual transformer-based models, which are trained on a specific language, outperform other models even in zero and few-shot settings.
Plain English Explanation
Sentiment analysis is a powerful tool that helps organizations understand the emotions and opinions expressed in text, such as customer reviews, social media posts, and news articles. This technology has become increasingly important across various industries, including marketing, politics, customer service, and healthcare.
However, while sentiment analysis has seen significant advancements for widely spoken languages, low-resource languages like Bangla have received less attention due to a lack of available data and resources. This study aims to address this gap by creating a large, manually annotated dataset of Bangla text, which can be used to train and evaluate language models for sentiment analysis.
The researchers investigate the performance of several large language models, including Flan-T5, GPT-4, and Bloomz, in zero-shot and few-shot learning scenarios for Bangla sentiment analysis. Zero-shot learning means the models are asked to perform a task without any prior training on that specific task, while few-shot learning involves providing the models with a small amount of training data.
The findings suggest that monolingual transformer-based models, which are trained specifically on the Bangla language, consistently outperform other models, even in these challenging zero and few-shot scenarios. This is an important result, as it shows that language models can be effectively adapted to low-resource languages with limited data, which has significant implications for the field of natural language processing and its applications.
Technical Explanation
The paper presents a comprehensive study on sentiment analysis for the Bangla language, a low-resource language that has received limited attention in the literature. The researchers created a large, manually annotated dataset of 33,606 Bangla news tweets and Facebook comments, which they plan to make publicly available to support further research in this area.
The study investigates the performance of several large language models, including Flan-T5, GPT-4, and Bloomz, in zero-shot and few-shot learning scenarios for Bangla sentiment analysis. The researchers compare the performance of these models against fine-tuned models, which are trained specifically on the Bangla dataset.
The results demonstrate that monolingual transformer-based models, such as those trained on the Bangla language, consistently outperform other models, even in zero-shot and few-shot settings. This finding is significant, as it suggests that large language models can be effectively adapted to low-resource languages with limited data, as described in this study.
The researchers also discuss the potential applications of their work in multimodal sentiment analysis and highlight the importance of continued exploration in this area to support the development of natural language processing solutions for underserved languages.
Critical Analysis
The study presents a valuable contribution to the field of sentiment analysis for low-resource languages, specifically Bangla. The creation of a large, manually annotated dataset is a significant achievement and will undoubtedly benefit the broader research community.
However, the paper does not delve into the potential limitations of the dataset, such as any biases or skewed representations within the corpus. It would be valuable to understand how the dataset was curated and whether steps were taken to ensure its diversity and representativeness.
Additionally, while the study compares the performance of various language models, it would be interesting to see a more in-depth analysis of the specific strengths and weaknesses of each model, as well as any insights into the underlying reasons for their performance differences.
Furthermore, the researchers mention the potential for exploring multimodal sentiment analysis, but do not provide any details on how this could be pursued or the challenges that may arise. Expanding on this direction could strengthen the paper's impact and inspire further research in this area.
Overall, the study presents valuable findings and resources that can drive progress in sentiment analysis for low-resource languages. However, a more comprehensive discussion of the dataset's limitations and the nuances of the model comparisons could further enhance the paper's contribution to the field.
Conclusion
This study makes a significant contribution to the field of sentiment analysis by creating a large, manually annotated dataset for the Bangla language and investigating the performance of several large language models in zero-shot and few-shot learning scenarios.
The key finding that monolingual transformer-based models consistently outperform other models, even in challenging low-resource settings, has important implications for the development of natural language processing solutions for underserved languages. This insight could inspire further research and innovation in this area, ultimately expanding the reach and impact of sentiment analysis technologies across diverse industries and applications.
By making the dataset and research tools publicly available, the researchers are fostering continued exploration and collaboration within the broader research community. This commitment to open science and data sharing is commendable and will undoubtedly accelerate progress in the field of sentiment analysis for low-resource languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Unraveling the Dominance of Large Language Models Over Transformer Models for Bangla Natural Language Inference: A Comprehensive Study
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Asif Iftekher Fahim, Pronay Debnath, Faisal Muhammad Shah
0
0
Natural Language Inference (NLI) is a cornerstone of Natural Language Processing (NLP), providing insights into the entailment relationships between text pairings. It is a critical component of Natural Language Understanding (NLU), demonstrating the ability to extract information from spoken or written interactions. NLI is mainly concerned with determining the entailment relationship between two statements, known as the premise and hypothesis. When the premise logically implies the hypothesis, the pair is labeled entailment. If the hypothesis contradicts the premise, the pair receives the contradiction label. When there is insufficient evidence to establish a connection, the pair is described as neutral. Despite the success of Large Language Models (LLMs) in various tasks, their effectiveness in NLI remains constrained by issues like low-resource domain accuracy, model overconfidence, and difficulty in capturing human judgment disagreements. This study addresses the underexplored area of evaluating LLMs in low-resourced languages such as Bengali. Through a comprehensive evaluation, we assess the performance of prominent LLMs and state-of-the-art (SOTA) models in Bengali NLP tasks, focusing on natural language inference. Utilizing the XNLI dataset, we conduct zero-shot and few-shot evaluations, comparing LLMs like GPT-3.5 Turbo and Gemini 1.5 Pro with models such as BanglaBERT, Bangla BERT Base, DistilBERT, mBERT, and sahajBERT. Our findings reveal that while LLMs can achieve comparable or superior performance to fine-tuned SOTA models in few-shot scenarios, further research is necessary to enhance our understanding of LLMs in languages with modest resources like Bengali. This study underscores the importance of continued efforts in exploring LLM capabilities across diverse linguistic contexts.
5/8/2024
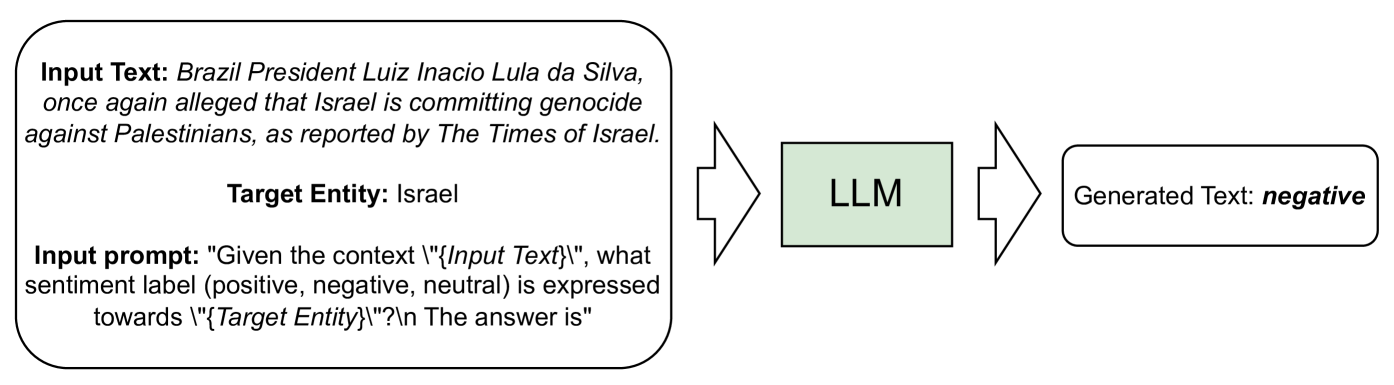
Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies
Alapan Kuila, Sudeshna Sarkar
0
0
Sentiment analysis plays a pivotal role in understanding public opinion, particularly in the political domain where the portrayal of entities in news articles influences public perception. In this paper, we investigate the effectiveness of Large Language Models (LLMs) in predicting entity-specific sentiment from political news articles. Leveraging zero-shot and few-shot strategies, we explore the capability of LLMs to discern sentiment towards political entities in news content. Employing a chain-of-thought (COT) approach augmented with rationale in few-shot in-context learning, we assess whether this method enhances sentiment prediction accuracy. Our evaluation on sentiment-labeled datasets demonstrates that LLMs, outperform fine-tuned BERT models in capturing entity-specific sentiment. We find that learning in-context significantly improves model performance, while the self-consistency mechanism enhances consistency in sentiment prediction. Despite the promising results, we observe inconsistencies in the effectiveness of the COT prompting method. Overall, our findings underscore the potential of LLMs in entity-centric sentiment analysis within the political news domain and highlight the importance of suitable prompting strategies and model architectures.
4/9/2024
💬
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
0
0
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
4/30/2024
Low-Resource Machine Translation through Retrieval-Augmented LLM Prompting: A Study on the Mambai Language
Raphael Merx, Aso Mahmudi, Katrina Langford, Leo Alberto de Araujo, Ekaterina Vylomova
0
0
This study explores the use of large language models (LLMs) for translating English into Mambai, a low-resource Austronesian language spoken in Timor-Leste, with approximately 200,000 native speakers. Leveraging a novel corpus derived from a Mambai language manual and additional sentences translated by a native speaker, we examine the efficacy of few-shot LLM prompting for machine translation (MT) in this low-resource context. Our methodology involves the strategic selection of parallel sentences and dictionary entries for prompting, aiming to enhance translation accuracy, using open-source and proprietary LLMs (LlaMa 2 70b, Mixtral 8x7B, GPT-4). We find that including dictionary entries in prompts and a mix of sentences retrieved through TF-IDF and semantic embeddings significantly improves translation quality. However, our findings reveal stark disparities in translation performance across test sets, with BLEU scores reaching as high as 21.2 on materials from the language manual, in contrast to a maximum of 4.4 on a test set provided by a native speaker. These results underscore the importance of diverse and representative corpora in assessing MT for low-resource languages. Our research provides insights into few-shot LLM prompting for low-resource MT, and makes available an initial corpus for the Mambai language.
4/9/2024