Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
2405.15374
0
0

Abstract
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.
Create account to get full access
Overview
- Leveraging large language models (LLMs) for semantic query processing in a scholarly knowledge graph
- Integrating LLMs with a knowledge graph to enhance query understanding and retrieval
- Exploring the benefits of combining LLMs and knowledge graphs for scholarly knowledge management
Plain English Explanation
This paper explores how large language models can be used to improve the way people search for and understand information in a scholarly knowledge graph. A knowledge graph is a way of organizing information, like a database, but one that focuses on the relationships between different pieces of information.
By combining the powerful natural language processing capabilities of large language models with the structured data in a knowledge graph, the researchers aimed to create a more intelligent and effective system for searching and understanding scholarly content. The key idea is that the language model can help interpret the meaning and context of a user's query, and then the knowledge graph can be used to find the most relevant information to answer that query.
This could be useful for researchers, students, or anyone trying to navigate the vast amount of scholarly literature and data available online. Instead of just searching for keywords, the system can understand the user's intent and provide more relevant and useful results. The researchers also explored ways to enhance the knowledge graph itself by using the language model to extract and organize new information from the underlying documents.
Overall, the paper investigates the synergies between large language models and knowledge graphs, and how this combination can be leveraged to improve scholarly knowledge management and information retrieval.
Technical Explanation
The paper presents a system that leverages large language models for semantic query processing in a scholarly knowledge graph. The key components of the system include:
-
Knowledge Graph: A structured representation of scholarly concepts, entities, and their relationships, built using RDF (Resource Description Framework) data.
-
Deep Document Model: A neural network-based model that encodes the semantic content of scholarly documents into the knowledge graph.
-
Query Processing: A large language model is used to understand the intent and context of user queries, which are then mapped to relevant concepts and entities in the knowledge graph.
-
Query Expansion: The language model is also used to expand user queries with relevant terms and phrases, improving the coverage and accuracy of the search results.
-
Knowledge Graph Enhancement: The language model is leveraged to extract new relationships and facts from the underlying documents, continuously expanding and refining the knowledge graph.
The researchers evaluate the system's performance on a range of scholarly search and question-answering tasks, comparing it to traditional keyword-based retrieval approaches. The results demonstrate the benefits of integrating large language models with knowledge graphs for enhanced semantic query processing and knowledge management in the scholarly domain.
Critical Analysis
The paper presents a well-designed and comprehensive system that effectively leverages the complementary strengths of large language models and knowledge graphs. However, a few potential limitations and areas for further research are worth noting:
-
Scalability: The researchers tested the system on a relatively small knowledge graph and corpus of scholarly documents. It remains to be seen how the approach would scale to handle the full breadth and depth of scholarly literature and knowledge.
-
Bias and Fairness: As with any language model-based system, there may be concerns about potential biases in the underlying data or model, which could impact the fairness and inclusiveness of the search results. Further research is needed to address these issues.
-
Explainability: The language model-based components of the system may be less interpretable than traditional knowledge-based approaches. Providing users with insights into the reasoning behind the system's responses could be an area for improvement.
-
Domain Generalization: The paper focuses on the scholarly domain, but it would be interesting to explore the application of this approach to other knowledge-intensive domains, such as healthcare or finance.
Overall, the paper presents a compelling and well-executed approach to leveraging the synergies between large language models and knowledge graphs for enhanced scholarly information retrieval and management. The results suggest promising avenues for further research and development in this area.
Conclusion
This paper demonstrates the potential of integrating large language models with knowledge graphs to improve semantic query processing and knowledge management in the scholarly domain. By combining the natural language understanding capabilities of LLMs with the structured knowledge representation of a knowledge graph, the researchers have developed a system that can more effectively interpret user queries and provide relevant, contextual information.
The findings suggest that this approach can enhance various scholarly tasks, such as searching for relevant literature, answering questions, and continuously expanding the knowledge base. While the current implementation is focused on the academic domain, the core principles could potentially be applied to other knowledge-intensive fields as well.
As large language models and knowledge graphs continue to evolve, further research in this area could yield even more powerful and versatile systems for organizing, accessing, and generating scholarly knowledge. This work represents an important step forward in leveraging the synergies between these two transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
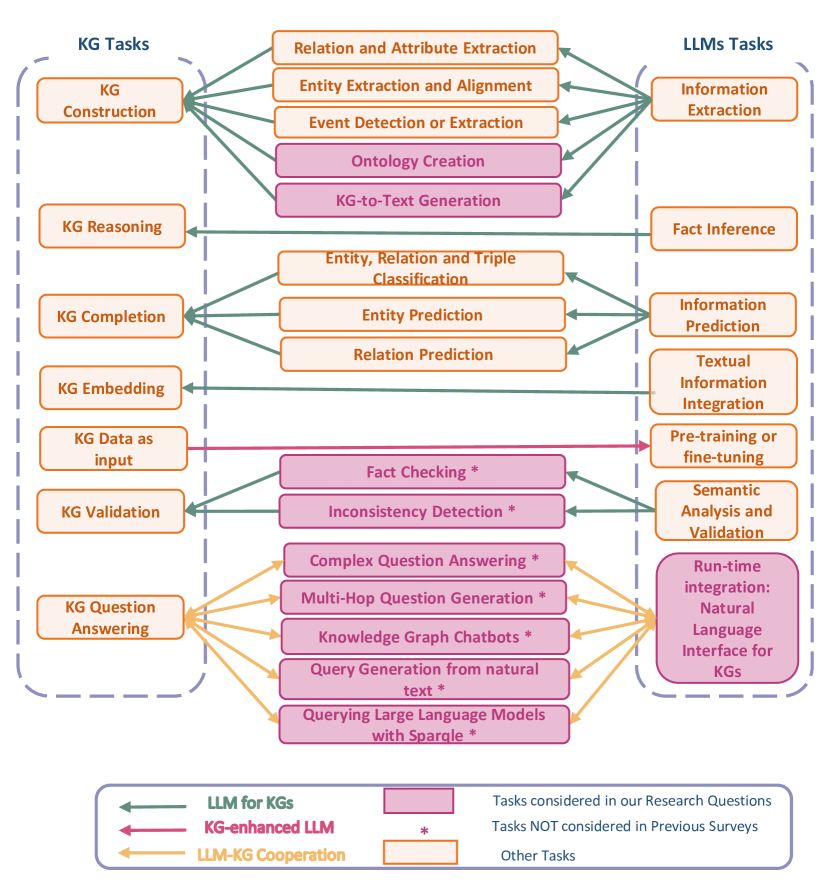
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
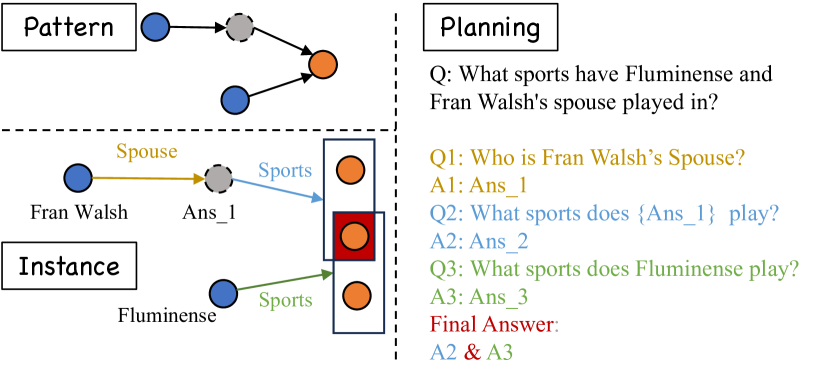
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
0
0
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
6/21/2024
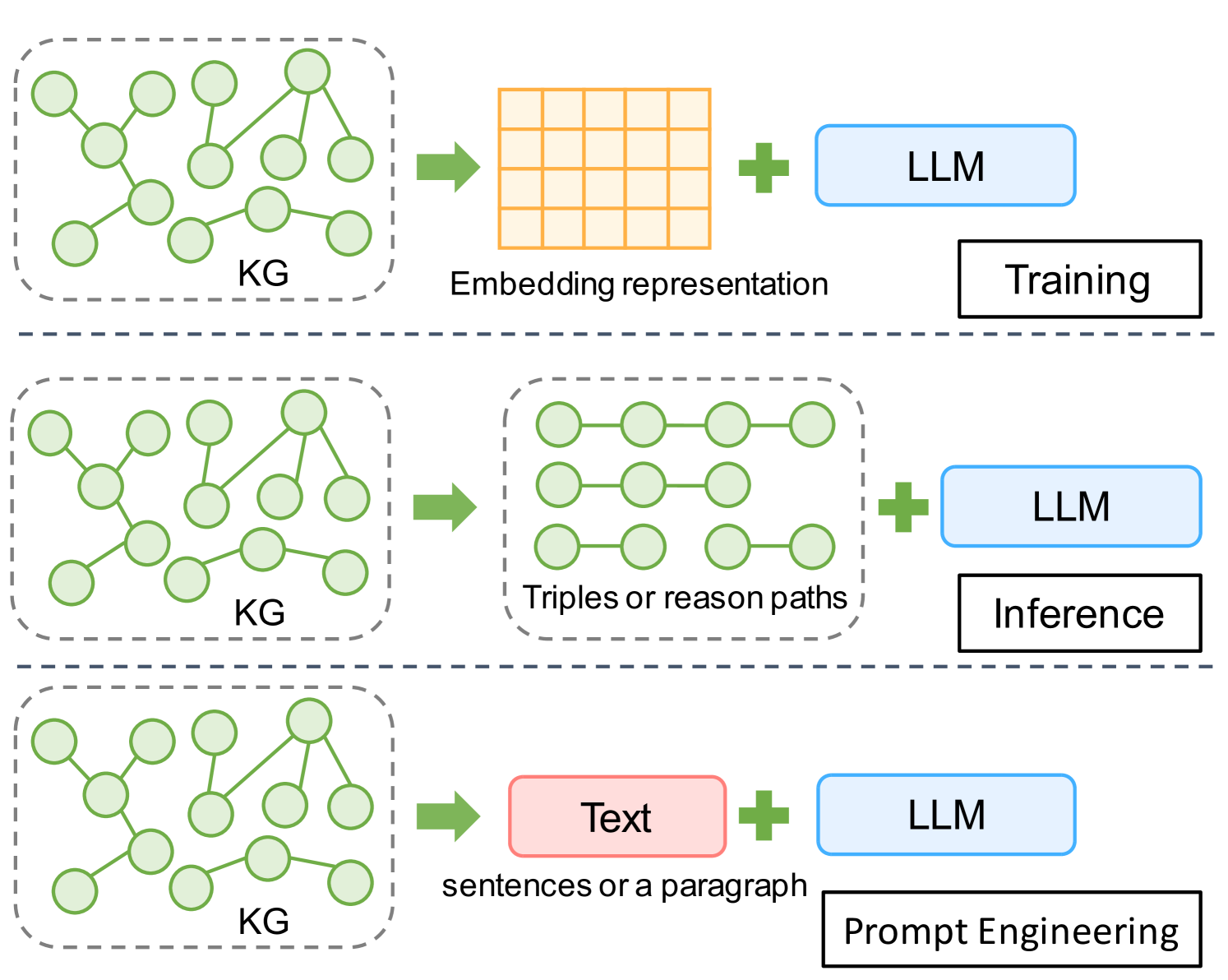
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024