Bayesian Exploration Networks
2308.13049
0
0
🔍
Abstract
Bayesian reinforcement learning (RL) offers a principled and elegant approach for sequential decision making under uncertainty. Most notably, Bayesian agents do not face an exploration/exploitation dilemma, a major pathology of frequentist methods. However theoretical understanding of model-free approaches is lacking. In this paper, we introduce a novel Bayesian model-free formulation and the first analysis showing that model-free approaches can yield Bayes-optimal policies. We show all existing model-free approaches make approximations that yield policies that can be arbitrarily Bayes-suboptimal. As a first step towards model-free Bayes optimality, we introduce the Bayesian exploration network (BEN) which uses normalising flows to model both the aleatoric uncertainty (via density estimation) and epistemic uncertainty (via variational inference) in the Bellman operator. In the limit of complete optimisation, BEN learns true Bayes-optimal policies, but like in variational expectation-maximisation, partial optimisation renders our approach tractable. Empirical results demonstrate that BEN can learn true Bayes-optimal policies in tasks where existing model-free approaches fail.
Create account to get full access
Overview
- Bayesian reinforcement learning (RL) offers a principled approach for decision-making under uncertainty
- However, the theoretical understanding of model-free approaches in Bayesian RL has been lacking
- This paper introduces a novel Bayesian model-free formulation and shows that model-free approaches can yield Bayes-optimal policies
- The authors introduce the Bayesian Exploration Network (BEN), which uses normalizing flows to model both aleatoric and epistemic uncertainty in the Bellman operator
Plain English Explanation
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions in an uncertain environment in order to maximize a reward. Bayesian RL offers a principled way to do this by incorporating prior knowledge and uncertainty into the decision-making process.
One major challenge in RL is the exploration/exploitation dilemma - the agent has to balance trying new things (exploration) to gain more information versus sticking with what has worked well so far (exploitation). Bayesian agents do not face this dilemma, but the theoretical understanding of model-free Bayesian RL approaches has been limited.
This paper introduces a new Bayesian model-free formulation that can learn Bayes-optimal policies - policies that are the best possible given the agent's prior knowledge and uncertainty. The authors create a model called the Bayesian Exploration Network (BEN) that uses a technique called normalizing flows to estimate both the inherent randomness (aleatoric uncertainty) and the lack of knowledge (epistemic uncertainty) in the Bellman equation, which is a core part of RL.
By fully optimizing BEN, the agent can learn the true Bayes-optimal policy. But even with partial optimization, BEN outperforms existing model-free Bayesian RL approaches, which the paper shows make approximations that can lead to suboptimal policies.
Technical Explanation
The key technical contribution of this paper is a novel Bayesian model-free RL formulation that can provably learn Bayes-optimal policies. The authors show that existing model-free Bayesian RL approaches, such as Thompson sampling and variational inference, make approximations that can lead to policies that are arbitrarily far from Bayes-optimal.
To address this, the authors introduce the Bayesian Exploration Network (BEN), which uses normalizing flows to model both the aleatoric uncertainty (inherent randomness) and epistemic uncertainty (lack of knowledge) in the Bellman operator. In the limit of complete optimization, BEN is guaranteed to learn the true Bayes-optimal policy.
However, as with variational expectation-maximization, partial optimization of BEN is necessary to make the approach tractable. The empirical results demonstrate that even with partial optimization, BEN can learn Bayes-optimal policies in tasks where existing model-free Bayesian RL methods fail.
Critical Analysis
The authors provide a rigorous theoretical analysis showing the limitations of existing model-free Bayesian RL approaches and the potential advantages of their BEN formulation. However, the paper does not fully address the computational challenges of optimizing BEN in practice, particularly for large or complex environments.
While the empirical results are promising, the experiments are still relatively simple and it remains to be seen how well BEN would scale to more realistic, high-dimensional problems. Additionally, the paper does not discuss potential issues around distributional shift or model misspecification, which can be major challenges in real-world RL applications.
Further research is needed to better understand the practical limitations and tradeoffs of the BEN approach, as well as to explore ways of making the optimization more efficient and robust. Nonetheless, this paper represents an important step forward in the theoretical understanding of model-free Bayesian RL and provides a strong foundation for future work in this area.
Conclusion
This paper introduces a novel Bayesian model-free reinforcement learning formulation that can provably learn Bayes-optimal policies. By using normalizing flows to model both aleatoric and epistemic uncertainty, the Bayesian Exploration Network (BEN) overcomes limitations of existing model-free Bayesian RL approaches.
The theoretical analysis and empirical results demonstrate the potential of BEN to learn better policies in uncertain environments compared to previous model-free methods. While further research is needed to address practical challenges, this work represents a significant advance in the field of Bayesian reinforcement learning and could have important implications for decision-making under uncertainty in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Active Exploration in Bayesian Model-based Reinforcement Learning for Robot Manipulation
Carlos Plou, Ana C. Murillo, Ruben Martinez-Cantin
0
0
Efficiently tackling multiple tasks within complex environment, such as those found in robot manipulation, remains an ongoing challenge in robotics and an opportunity for data-driven solutions, such as reinforcement learning (RL). Model-based RL, by building a dynamic model of the robot, enables data reuse and transfer learning between tasks with the same robot and similar environment. Furthermore, data gathering in robotics is expensive and we must rely on data efficient approaches such as model-based RL, where policy learning is mostly conducted on cheaper simulations based on the learned model. Therefore, the quality of the model is fundamental for the performance of the posterior tasks. In this work, we focus on improving the quality of the model and maintaining the data efficiency by performing active learning of the dynamic model during a preliminary exploration phase based on maximize information gathering. We employ Bayesian neural network models to represent, in a probabilistic way, both the belief and information encoded in the dynamic model during exploration. With our presented strategies we manage to actively estimate the novelty of each transition, using this as the exploration reward. In this work, we compare several Bayesian inference methods for neural networks, some of which have never been used in a robotics context, and evaluate them in a realistic robot manipulation setup. Our experiments show the advantages of our Bayesian model-based RL approach, with similar quality in the results than relevant alternatives with much lower requirements regarding robot execution steps. Unlike related previous studies that focused the validation solely on toy problems, our research takes a step towards more realistic setups, tackling robotic arm end-tasks.
4/3/2024
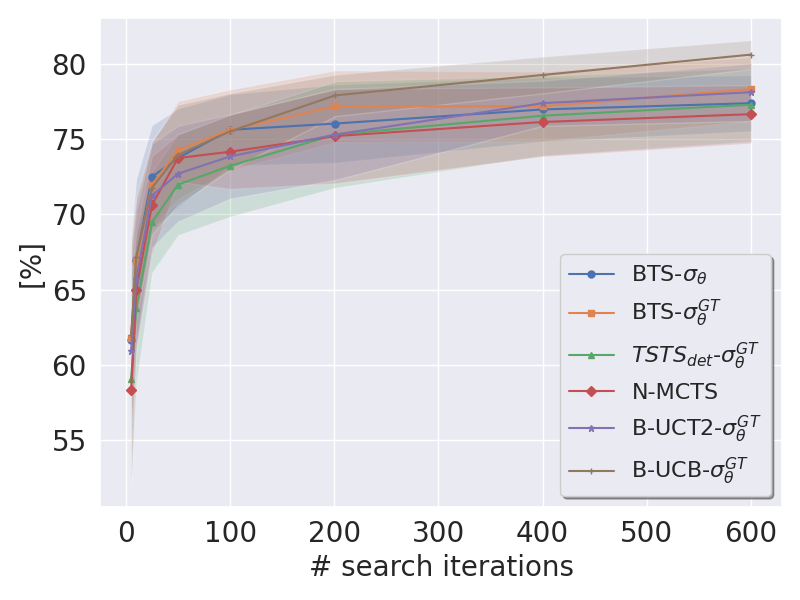
A Bayesian Approach to Online Planning
Nir Greshler, David Ben Eli, Carmel Rabinovitz, Gabi Guetta, Liran Gispan, Guy Zohar, Aviv Tamar
0
0
The combination of Monte Carlo tree search and neural networks has revolutionized online planning. As neural network approximations are often imperfect, we ask whether uncertainty estimates about the network outputs could be used to improve planning. We develop a Bayesian planning approach that facilitates such uncertainty quantification, inspired by classical ideas from the meta-reasoning literature. We propose a Thompson sampling based algorithm for searching the tree of possible actions, for which we prove the first (to our knowledge) finite time Bayesian regret bound, and propose an efficient implementation for a restricted family of posterior distributions. In addition we propose a variant of the Bayes-UCB method applied to trees. Empirically, we demonstrate that on the ProcGen Maze and Leaper environments, when the uncertainty estimates are accurate but the neural network output is inaccurate, our Bayesian approach searches the tree much more effectively. In addition, we investigate whether popular uncertainty estimation methods are accurate enough to yield significant gains in planning. Our code is available at: https://github.com/nirgreshler/bayesian-online-planning.
6/5/2024
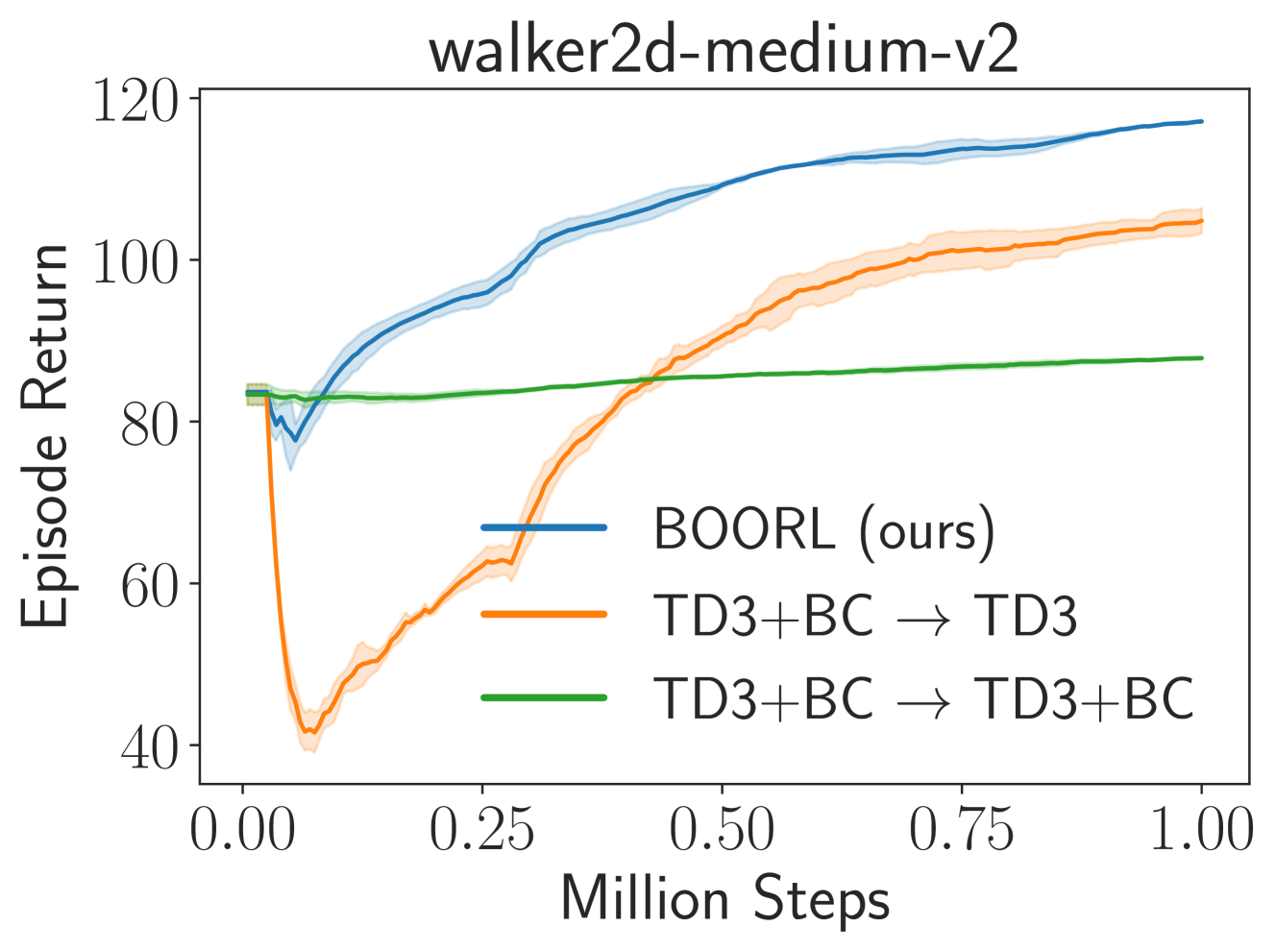
Bayesian Design Principles for Offline-to-Online Reinforcement Learning
Hao Hu, Yiqin Yang, Jianing Ye, Chengjie Wu, Ziqing Mai, Yujing Hu, Tangjie Lv, Changjie Fan, Qianchuan Zhao, Chongjie Zhang
0
0
Offline reinforcement learning (RL) is crucial for real-world applications where exploration can be costly or unsafe. However, offline learned policies are often suboptimal, and further online fine-tuning is required. In this paper, we tackle the fundamental dilemma of offline-to-online fine-tuning: if the agent remains pessimistic, it may fail to learn a better policy, while if it becomes optimistic directly, performance may suffer from a sudden drop. We show that Bayesian design principles are crucial in solving such a dilemma. Instead of adopting optimistic or pessimistic policies, the agent should act in a way that matches its belief in optimal policies. Such a probability-matching agent can avoid a sudden performance drop while still being guaranteed to find the optimal policy. Based on our theoretical findings, we introduce a novel algorithm that outperforms existing methods on various benchmarks, demonstrating the efficacy of our approach. Overall, the proposed approach provides a new perspective on offline-to-online RL that has the potential to enable more effective learning from offline data.
6/3/2024
🏅
A Bayesian Approach to Robust Inverse Reinforcement Learning
Ran Wei, Siliang Zeng, Chenliang Li, Alfredo Garcia, Anthony McDonald, Mingyi Hong
0
0
We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
4/9/2024