Bayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks

0
Sign in to get full access
Overview
- Bayesian Low-Rank Learning (Bella) is a practical approach to Bayesian neural networks.
- It aims to address limitations of existing Bayesian neural network methods by using low-rank structure and efficient optimization.
- The paper proposes a new Bayesian neural network framework and demonstrates its effectiveness on various tasks.
Plain English Explanation
Bayesian neural networks are a type of machine learning model that can quantify uncertainty in their predictions. This can be useful in applications where understanding uncertainty is important, like medical diagnosis. However, existing Bayesian neural network methods can be computationally expensive and difficult to use.
The Bella approach tries to make Bayesian neural networks more practical. It uses a special low-rank structure to reduce the number of parameters in the model. This makes the model faster and easier to train. Bella also uses an efficient optimization method to further improve training speed.
The paper shows that Bella can match or outperform standard neural networks on a variety of tasks, while also providing useful uncertainty estimates. This suggests Bella could be a valuable tool for applications that need both accurate predictions and an understanding of the model's confidence.
Technical Explanation
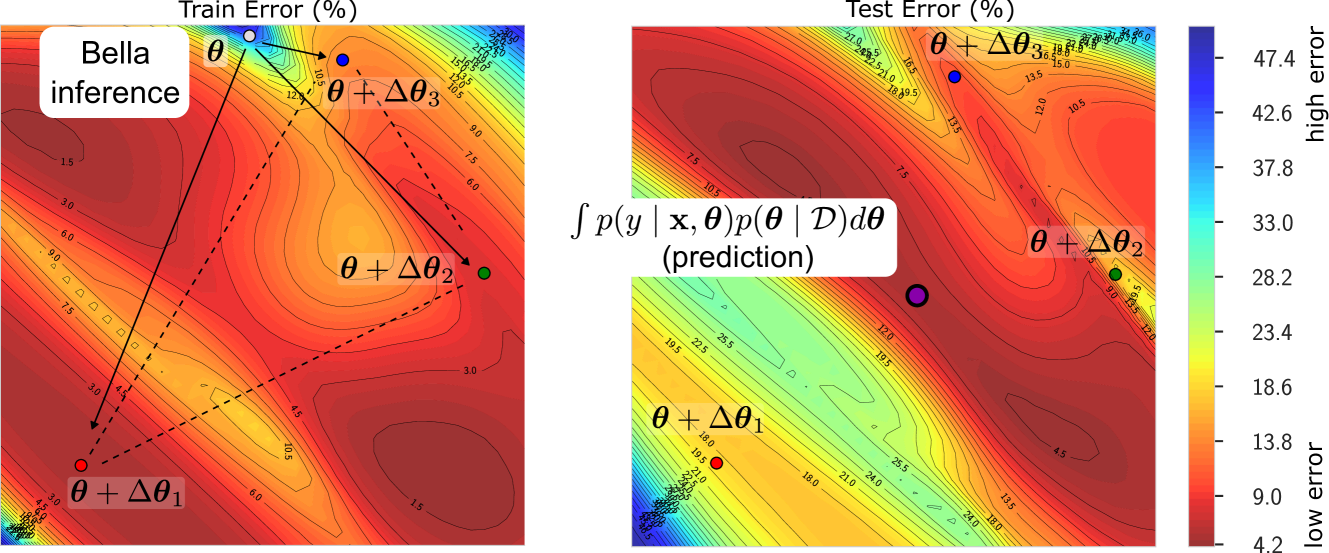
The Bella framework models the weights of a neural network using a low-rank Gaussian prior. This allows the full covariance matrix of the weights to be represented efficiently, enabling modeling of parameter uncertainty.
The paper proposes an optimization algorithm called Stochastic Riemannian Gradient Descent (SRGD) to train the Bella model. SRGD exploits the low-rank structure of the weight distributions to enable faster and more scalable training compared to standard Bayesian neural network methods.
Experiments on benchmark datasets show that Bella can achieve comparable or better predictive performance than standard neural networks, while also providing well-calibrated uncertainty estimates. The paper also demonstrates Bella's effectiveness on real-world applications like climate modeling and few-shot learning.
Critical Analysis
The paper provides a thorough empirical evaluation of Bella, but does not deeply explore the theoretical foundations or limitations of the approach. For example, the authors do not analyze the tightness of the variational approximation used in Bella or discuss potential biases introduced by the low-rank assumption.
Additionally, the computational complexity of SRGD is not fully characterized, and the authors do not compare its training time to other scalable Bayesian neural network methods like Variational Continual Learning or Blob-BNN.
Further research could explore the theoretical properties of Bella, as well as its performance on a wider range of applications, especially those requiring reliable uncertainty quantification. Comparisons to other state-of-the-art Bayesian neural network approaches would also help contextualize the strengths and limitations of the Bella framework.
Conclusion
The Bella framework presents a promising approach to making Bayesian neural networks more practical and accessible. By leveraging low-rank structure and efficient optimization, Bella can achieve competitive predictive performance while also providing well-calibrated uncertainty estimates.
This could make Bella a valuable tool for applications that require both accurate predictions and an understanding of model uncertainty, such as medical diagnosis, climate modeling, and few-shot learning. Further research to improve the theoretical foundations and evaluate Bella on a broader range of tasks could help solidify its position as a practical Bayesian neural network method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Bao Gia Doan, Afshar Shamsi, Xiao-Yu Guo, Arash Mohammadi, Hamid Alinejad-Rokny, Dino Sejdinovic, Damith C. Ranasinghe, Ehsan Abbasnejad
Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.
Read more8/27/2024
0
Restricted Bayesian Neural Network
Sourav Ganguly, Saprativa Bhattacharjee
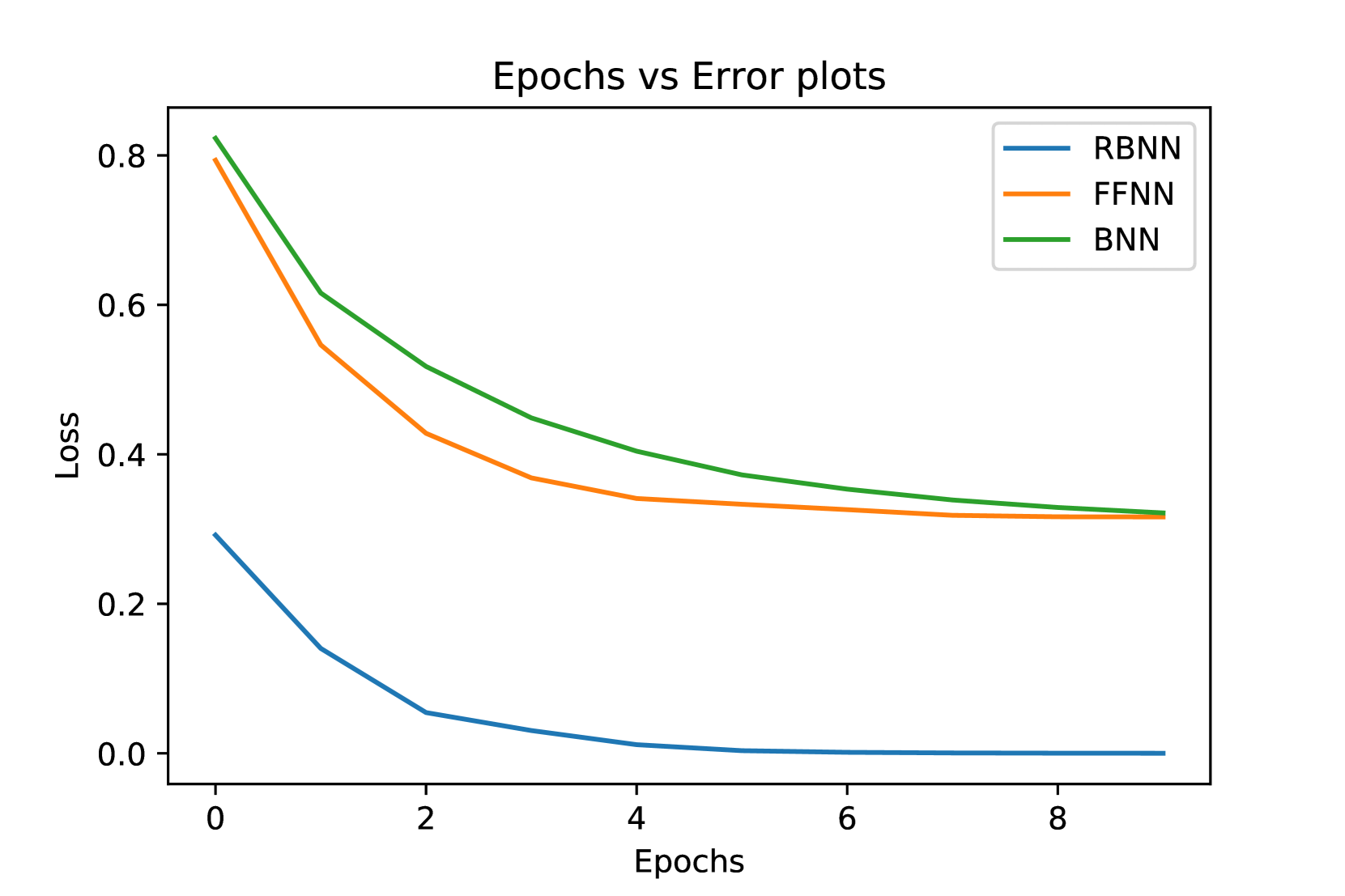
Modern deep learning tools are remarkably effective in addressing intricate problems. However, their operation as black-box models introduces increased uncertainty in predictions. Additionally, they contend with various challenges, including the need for substantial storage space in large networks, issues of overfitting, underfitting, vanishing gradients, and more. This study explores the concept of Bayesian Neural Networks, presenting a novel architecture designed to significantly alleviate the storage space complexity of a network. Furthermore, we introduce an algorithm adept at efficiently handling uncertainties, ensuring robust convergence values without becoming trapped in local optima, particularly when the objective function lacks perfect convexity.
Read more4/9/2024
0
BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models
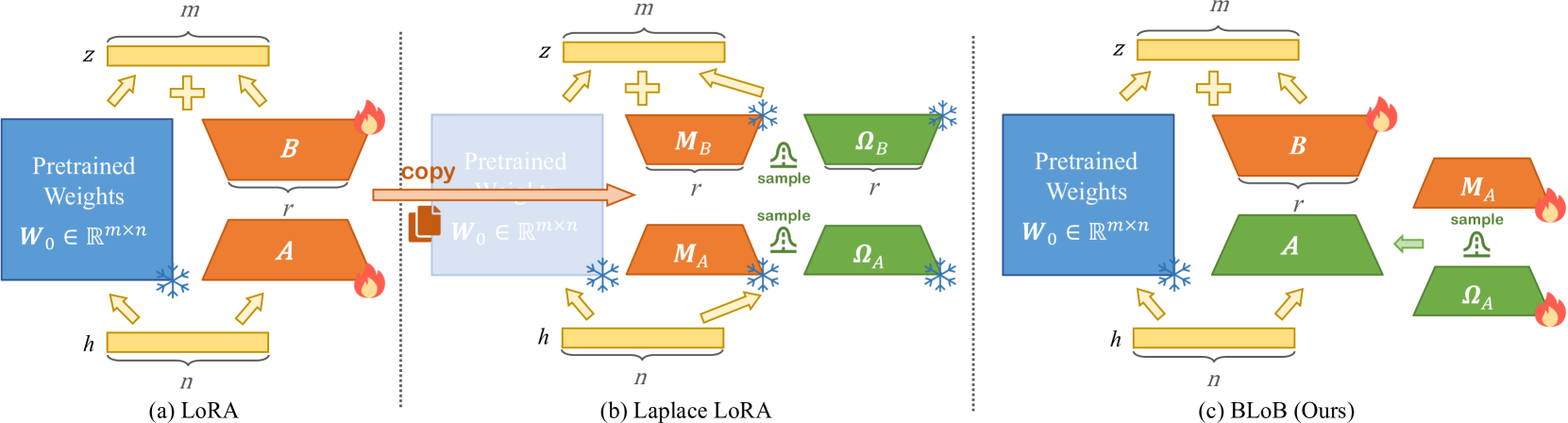
Yibin Wang, Haizhou Shi, Ligong Han, Dimitris Metaxas, Hao Wang
Large Language Models (LLMs) often suffer from overconfidence during inference, particularly when adapted to downstream domain-specific tasks with limited data. Previous work addresses this issue by employing approximate Bayesian estimation after the LLMs are trained, enabling them to quantify uncertainty. However, such post-training approaches' performance is severely limited by the parameters learned during training. In this paper, we go beyond post-training Bayesianization and propose Bayesian Low-Rank Adaptation by Backpropagation (BLoB), an algorithm that continuously and jointly adjusts both the mean and covariance of LLM parameters throughout the whole fine-tuning process. Our empirical results verify the effectiveness of BLoB in terms of generalization and uncertainty estimation, when evaluated on both in-distribution and out-of-distribution data.
Read more6/19/2024

0
Low-Budget Simulation-Based Inference with Bayesian Neural Networks
Arnaud Delaunoy, Maxence de la Brassinne Bonardeaux, Siddharth Mishra-Sharma, Gilles Louppe
Simulation-based inference methods have been shown to be inaccurate in the data-poor regime, when training simulations are limited or expensive. Under these circumstances, the inference network is particularly prone to overfitting, and using it without accounting for the computational uncertainty arising from the lack of identifiability of the network weights can lead to unreliable results. To address this issue, we propose using Bayesian neural networks in low-budget simulation-based inference, thereby explicitly accounting for the computational uncertainty of the posterior approximation. We design a family of Bayesian neural network priors that are tailored for inference and show that they lead to well-calibrated posteriors on tested benchmarks, even when as few as $O(10)$ simulations are available. This opens up the possibility of performing reliable simulation-based inference using very expensive simulators, as we demonstrate on a problem from the field of cosmology where single simulations are computationally expensive. We show that Bayesian neural networks produce informative and well-calibrated posterior estimates with only a few hundred simulations.
Read more8/28/2024