Bayesian Optimisation for Active Monitoring of Air Pollution

0
✨
Sign in to get full access
Overview
- Air pollution is a major global health issue, causing millions of deaths each year.
- Efficient monitoring of air pollution is crucial to measure exposure and enforce legal limits.
- New low-cost sensors can be deployed more widely, leading to the problem of efficient automated placement.
- Previous research suggests Bayesian optimization is a suitable method, but only considered satellite data aggregated over all altitudes.
- This paper improves on those results by using hierarchical models and evaluating the approach on urban pollution data in London.
Plain English Explanation
Air pollution is a significant problem around the world, causing many people to become ill and even die each year. Closely monitoring air quality is important to understand how much pollution people are exposed to and to enforce laws that limit pollution levels. New, inexpensive air quality sensors can be set up in many more locations, which raises the question of how to best place those sensors to get the most useful data.
Previous research has shown that Bayesian optimization is a good approach for automatically deciding where to put these sensors. However, that earlier work only looked at data collected from satellites, which measure air pollution at all different heights in the atmosphere. What really matters for human health is the pollution level close to the ground, where people breathe the air.
This new paper improves on the previous research by using more sophisticated statistical models, called hierarchical models, and by testing the approach using real-world air pollution data collected in the city of London. The results demonstrate that Bayesian optimization can be successfully applied to the problem of efficiently placing air quality sensors to measure the pollution that people actually experience.
Technical Explanation
The researchers in this paper aimed to build on previous work that used Bayesian optimization to automate the placement of air quality sensors. While that prior research showed promise, it was limited to using satellite data that aggregated pollution levels across all altitudes.
To better capture the pollution that humans actually breathe at ground level, the researchers in this paper developed hierarchical statistical models. These models can account for the complex spatial and temporal patterns in urban air pollution data. The team evaluated their approach using real-world data on nitrogen dioxide (NO2) levels collected across the city of London.
The results demonstrate that the hierarchical Bayesian optimization framework outperformed simpler approaches, such as randomly placing sensors or using machine learning algorithms for dust/aerosol detection. The method was able to efficiently identify locations that would provide the most informative data about ground-level air pollution exposure.
Critical Analysis
A key strength of this research is the use of hierarchical models, which can better capture the nuanced spatial and temporal dynamics of urban air pollution compared to simpler approaches. This is an important advancement over prior work that relied on satellite data aggregated across all altitudes.
However, the paper does not address potential limitations of the sensor data itself. The sensors used may have issues with accuracy, calibration, or representativeness that could impact the optimization process. Additionally, the evaluation was limited to a single pollutant (NO2) in one city (London). Further testing across a wider range of locations, pollutants, and sensor technologies would help strengthen the generalizability of the findings.
It would also be valuable to explore how this automated sensor placement approach could be integrated with other air quality forecasting and predictive modeling techniques to provide a more comprehensive air pollution monitoring and management system.
Conclusion
This research demonstrates that hierarchical Bayesian optimization can be an effective method for efficiently placing air quality sensors to monitor ground-level pollution that is most relevant to human health. By accounting for the complex spatial and temporal patterns in urban air pollution data, the approach outperformed simpler alternatives.
The findings have important implications for improving air pollution monitoring and enforcement of environmental regulations. Deploying low-cost sensor networks optimized using this technique could provide much more detailed, localized data to policymakers and the public. This could lead to better-informed decisions about pollution mitigation strategies and their impacts on population exposure.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Bayesian Optimisation for Active Monitoring of Air Pollution
Sigrid Passano Hellan, Christopher G. Lucas, Nigel H. Goddard
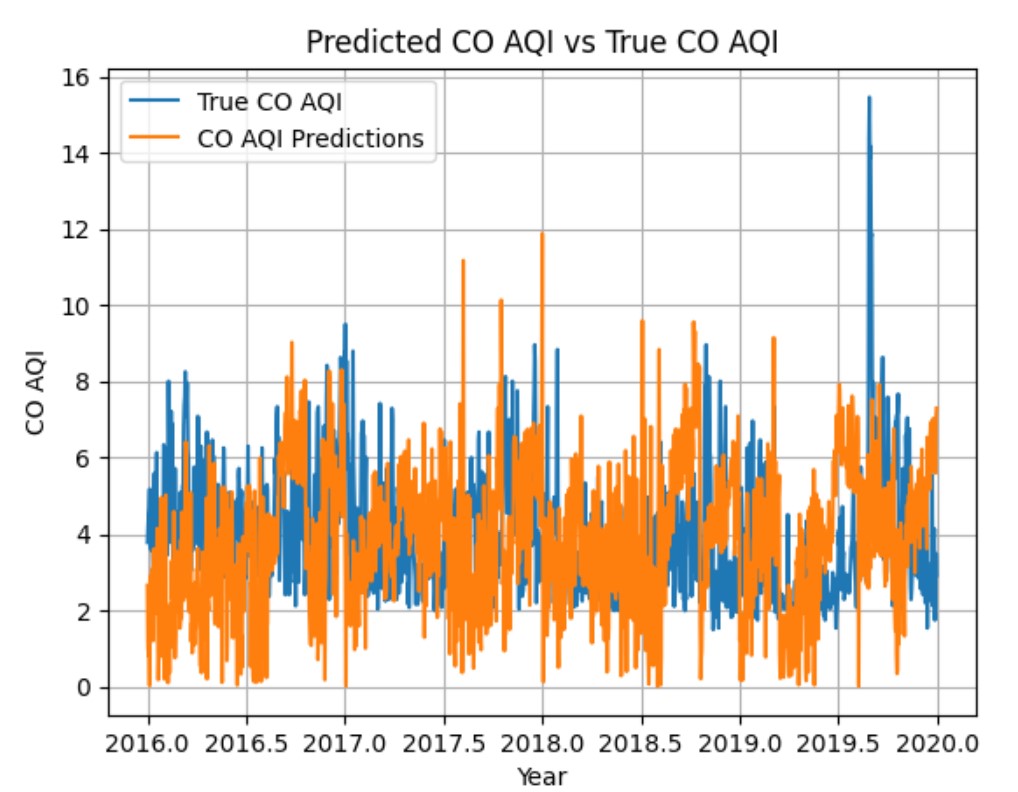
Air pollution is one of the leading causes of mortality globally, resulting in millions of deaths each year. Efficient monitoring is important to measure exposure and enforce legal limits. New low-cost sensors can be deployed in greater numbers and in more varied locations, motivating the problem of efficient automated placement. Previous work suggests Bayesian optimisation is an appropriate method, but only considered a satellite data set, with data aggregated over all altitudes. It is ground-level pollution, that humans breathe, which matters most. We improve on those results using hierarchical models and evaluate our models on urban pollution data in London to show that Bayesian optimisation can be successfully applied to the problem.
Read more4/22/2024

0
Urban Air Pollution Forecasting: a Machine Learning Approach leveraging Satellite Observations and Meteorological Forecasts
Giacomo Blanco, Luca Barco, Lorenzo Innocenti, Claudio Rossi
Air pollution poses a significant threat to public health and well-being, particularly in urban areas. This study introduces a series of machine-learning models that integrate data from the Sentinel-5P satellite, meteorological conditions, and topological characteristics to forecast future levels of five major pollutants. The investigation delineates the process of data collection, detailing the combination of diverse data sources utilized in the study. Through experiments conducted in the Milan metropolitan area, the models demonstrate their efficacy in predicting pollutant levels for the forthcoming day, achieving a percentage error of around 30%. The proposed models are advantageous as they are independent of monitoring stations, facilitating their use in areas without existing infrastructure. Additionally, we have released the collected dataset to the public, aiming to stimulate further research in this field. This research contributes to advancing our understanding of urban air quality dynamics and emphasizes the importance of amalgamating satellite, meteorological, and topographical data to develop robust pollution forecasting models.
Read more5/31/2024
0
Novel Approach for Predicting the Air Quality Index of Megacities through Attention-Enhanced Deep Multitask Spatiotemporal Learning
Harun Khan, Joseph Tso, Nathan Nguyen, Nivaan Kaushal, Ansh Malhotra, Nayel Rehman
Air pollution remains one of the most formidable environmental threats to human health globally, particularly in urban areas, contributing to nearly 7 million premature deaths annually. Megacities, defined as cities with populations exceeding 10 million, are frequent hotspots of severe pollution, experiencing numerous weeks of dangerously poor air quality due to the concentration of harmful pollutants. In addition, the complex interplay of factors makes accurate air quality predictions incredibly challenging, and prediction models often struggle to capture these intricate dynamics. To address these challenges, this paper proposes an attention-enhanced deep multitask spatiotemporal machine learning model based on long-short-term memory networks for long-term air quality monitoring and prediction. The model demonstrates robust performance in predicting the levels of major pollutants such as sulfur dioxide and carbon monoxide, effectively capturing complex trends and fluctuations. The proposed model provides actionable information for policymakers, enabling informed decision making to improve urban air quality.
Read more7/17/2024
🖼️
0
How to predict on-road air pollution based on street view images and machine learning: a quantitative analysis of the optimal strategy
Hui Zhong, Di Chen, Pengqin Wang, Wenrui Wang, Shaojie Shen, Yonghong Liu, Meixin Zhu
On-road air pollution exhibits substantial variability over short distances due to emission sources, dilution, and physicochemical processes. Integrating mobile monitoring data with street view images (SVIs) holds promise for predicting local air pollution. However, algorithms, sampling strategies, and image quality introduce extra errors due to a lack of reliable references that quantify their effects. To bridge this gap, we employed 314 taxis to monitor NO, NO2, PM2.5 and PM10 dynamically and sampled corresponding SVIs, aiming to develop a reliable strategy. We extracted SVI features from ~ 382,000 streetscape images, which were collected at various angles (0{deg}, 90{deg}, 180{deg}, 270{deg}) and ranges (buffers with radii of 100m, 200m, 300m, 400m, 500m). Also, three machine learning algorithms alongside the linear land-used regression (LUR) model were experimented with to explore the influences of different algorithms. Four typical image quality issues were identified and discussed. Generally, machine learning methods outperform linear LUR for estimating the four pollutants, with the ranking: random forest > XGBoost > neural network > LUR. Compared to single-angle sampling, the averaging strategy is an effective method to avoid bias of insufficient feature capture. Therefore, the optimal sampling strategy is to obtain SVIs at a 100m radius buffer and extract features using the averaging strategy. This approach achieved estimation results for each aggregation location with absolute errors almost less than 2.5 {mu}g/m^2 or ppb. Overexposure, blur, and underexposure led to image misjudgments and incorrect identifications, causing an overestimation of road features and underestimation of human-activity features, contributing to inaccurate NO, NO2, PM2.5 and PM10 estimation.
Read more9/20/2024