Data-driven Prior Learning for Bayesian Optimisation
2311.14653
0
0
Abstract
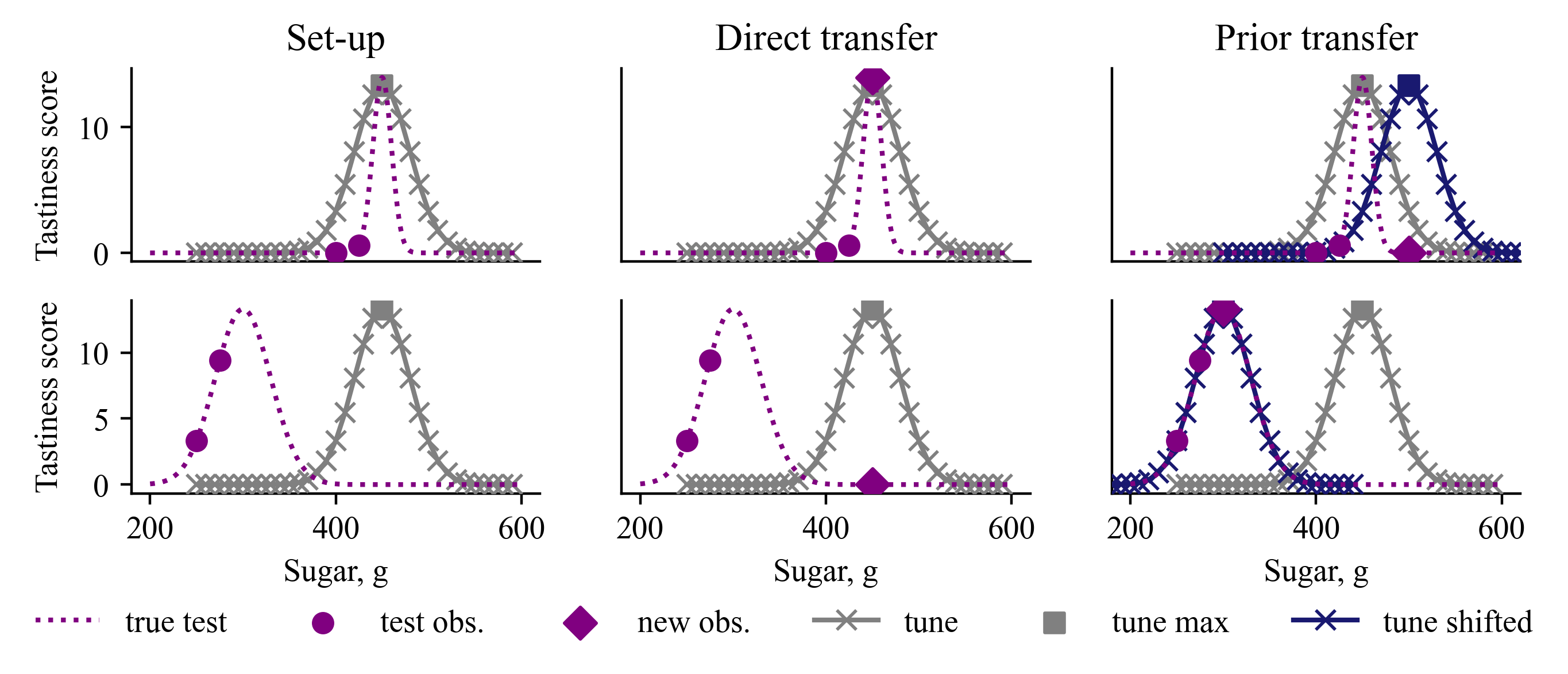
Transfer learning for Bayesian optimisation has generally assumed a strong similarity between optimisation tasks, with at least a subset having similar optimal inputs. This assumption can reduce computational costs, but it is violated in a wide range of optimisation problems where transfer learning may nonetheless be useful. We replace this assumption with a weaker one only requiring the shape of the optimisation landscape to be similar, and analyse the recent method Prior Learning for Bayesian Optimisation - PLeBO - in this setting. By learning priors for the hyperparameters of the Gaussian process surrogate model we can better approximate the underlying function, especially for few function evaluations. We validate the learned priors and compare to a breadth of transfer learning approaches, using synthetic data and a recent air pollution optimisation problem as benchmarks. We show that PLeBO and prior transfer find good inputs in fewer evaluations.
Create account to get full access
Overview
- Proposes a novel approach called "PLeBO" (Prior Learning for Bayesian Optimization) to improve the performance of Bayesian optimization by learning informative priors from past data
- Focuses on leveraging existing data and knowledge to guide the Bayesian optimization process and find optimal solutions more efficiently
- Demonstrates the effectiveness of PLeBO on a range of optimization problems, including synthetic benchmarks and real-world applications
Plain English Explanation
PLeBO is a technique that aims to make Bayesian optimization, a powerful method for optimizing complex functions, even more effective. Bayesian optimization is often used when the function being optimized is expensive to evaluate, such as in machine learning model tuning or scientific experiments.
The key idea behind PLeBO is to learn informative priors, or initial beliefs, about the function being optimized from past data and knowledge. This allows the Bayesian optimization process to start with a better understanding of the problem, rather than having to explore the entire search space blindly. By incorporating this prior information, PLeBO can find optimal solutions more efficiently, saving time and resources.
The researchers demonstrate the benefits of PLeBO on a variety of optimization problems, including synthetic benchmarks and real-world applications. They show that PLeBO can outperform standard Bayesian optimization approaches, particularly in cases where relevant prior information is available.
Technical Explanation
Bayesian optimization is a powerful technique for optimizing complex, expensive-to-evaluate functions. It works by building a probabilistic model of the function, called a Gaussian process, and using this model to guide the search for the optimum.
The key innovation in PLeBO is the way it learns the prior distribution for the Gaussian process. Instead of using a generic, uninformative prior, PLeBO leverages existing data and knowledge about the problem domain to learn an informative prior that can significantly improve the optimization process.
The researchers propose several methods for learning these data-driven priors, including using meta-learning techniques to extract patterns from previous optimization tasks, and incorporating domain-specific information through feature engineering and expert knowledge.
In their experiments, the researchers compare PLeBO to standard Bayesian optimization approaches on a range of problems, including synthetic benchmarks and real-world applications such as machine learning model tuning and scientific experiments. The results demonstrate that PLeBO can significantly outperform standard Bayesian optimization, particularly in cases where relevant prior information is available.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. For example, they note that the effectiveness of PLeBO depends on the availability and quality of the prior data and knowledge, and that more research is needed to understand how to best leverage different types of prior information.
Additionally, the paper does not address the potential for negative transfer, where the prior information actually hinders the optimization process rather than helping it. This is an important consideration, as poorly chosen or irrelevant priors could potentially lead to suboptimal solutions.
Overall, the PLeBO approach is a promising step forward in making Bayesian optimization even more effective and efficient. However, further research is needed to fully understand the strengths, limitations, and best practices for incorporating prior knowledge into the optimization process.
Conclusion
PLeBO presents a novel approach to improving the performance of Bayesian optimization by leveraging existing data and knowledge to learn informative priors. By incorporating these data-driven priors, PLeBO can guide the optimization process more effectively, leading to faster convergence and better solutions.
The results demonstrate the potential of PLeBO to enhance a wide range of optimization problems, from machine learning model tuning to scientific experiments. As the field of Bayesian optimization continues to evolve, techniques like PLeBO that can harness the power of prior information will become increasingly important for unlocking the full potential of this powerful optimization method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Black-box Adversarial Attacks via Bayesian Optimization Guided by a Function Prior
Shuyu Cheng, Yibo Miao, Yinpeng Dong, Xiao Yang, Xiao-Shan Gao, Jun Zhu
0
0
This paper studies the challenging black-box adversarial attack that aims to generate adversarial examples against a black-box model by only using output feedback of the model to input queries. Some previous methods improve the query efficiency by incorporating the gradient of a surrogate white-box model into query-based attacks due to the adversarial transferability. However, the localized gradient is not informative enough, making these methods still query-intensive. In this paper, we propose a Prior-guided Bayesian Optimization (P-BO) algorithm that leverages the surrogate model as a global function prior in black-box adversarial attacks. As the surrogate model contains rich prior information of the black-box one, P-BO models the attack objective with a Gaussian process whose mean function is initialized as the surrogate model's loss. Our theoretical analysis on the regret bound indicates that the performance of P-BO may be affected by a bad prior. Therefore, we further propose an adaptive integration strategy to automatically adjust a coefficient on the function prior by minimizing the regret bound. Extensive experiments on image classifiers and large vision-language models demonstrate the superiority of the proposed algorithm in reducing queries and improving attack success rates compared with the state-of-the-art black-box attacks. Code is available at https://github.com/yibo-miao/PBO-Attack.
5/30/2024

MALIBO: Meta-learning for Likelihood-free Bayesian Optimization
Jiarong Pan, Stefan Falkner, Felix Berkenkamp, Joaquin Vanschoren
0
0
Bayesian optimization (BO) is a popular method to optimize costly black-box functions. While traditional BO optimizes each new target task from scratch, meta-learning has emerged as a way to leverage knowledge from related tasks to optimize new tasks faster. However, existing meta-learning BO methods rely on surrogate models that suffer from scalability issues and are sensitive to observations with different scales and noise types across tasks. Moreover, they often overlook the uncertainty associated with task similarity. This leads to unreliable task adaptation when only limited observations are obtained or when the new tasks differ significantly from the related tasks. To address these limitations, we propose a novel meta-learning BO approach that bypasses the surrogate model and directly learns the utility of queries across tasks. Our method explicitly models task uncertainty and includes an auxiliary model to enable robust adaptation to new tasks. Extensive experiments show that our method demonstrates strong anytime performance and outperforms state-of-the-art meta-learning BO methods in various benchmarks.
7/1/2024
🛠️
Pseudo-Bayesian Optimization
Haoxian Chen, Henry Lam
0
0
Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-based methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable randomized prior construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
6/21/2024
Cost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
Dong Bok Lee, Aoxuan Silvia Zhang, Byungjoo Kim, Junhyeon Park, Juho Lee, Sung Ju Hwang, Hae Beom Lee
0
0
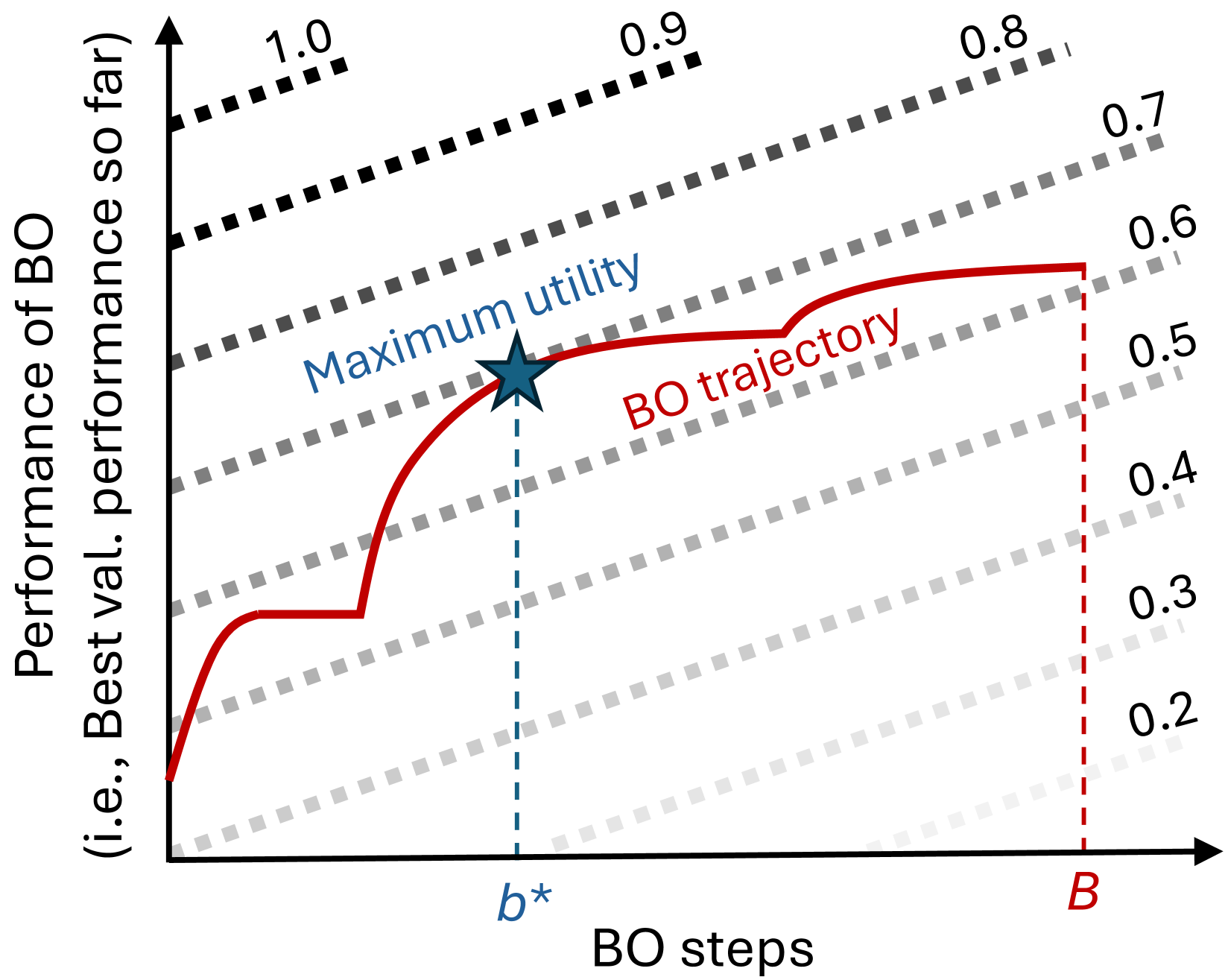
In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
5/29/2024