Bayesian Regret Minimization in Offline Bandits

0
🎲
Sign in to get full access
Overview
- The researchers explore how to make decisions that minimize Bayesian regret in offline linear bandits.
- They argue that the common approach of taking actions with the maximum lower confidence bound (LCB) on their reward is flawed.
- The researchers propose a new algorithm that directly minimizes upper bounds on the Bayesian regret using efficient conic optimization solvers.
- Their approach builds on connections to monetary risk measures and is shown to outperform the LCB approach.
Plain English Explanation
In the field of machine learning, the linear bandit problem involves making a series of decisions, each of which can lead to a certain reward. The goal is to minimize the "Bayesian regret" - the difference between the rewards of the chosen actions and the best possible actions.
The researchers argue that the standard approach of choosing actions with the highest "lower confidence bound" (LCB) on their reward is flawed in this setting. Instead, they propose a new algorithm that directly minimizes the upper bounds on the Bayesian regret. This approach leverages connections to monetary risk measures and can be efficiently implemented using conic optimization solvers.
By minimizing these upper bounds, the researchers show that their approach is guaranteed to outperform the LCB method. The key idea is to focus on bounding the worst-case performance, rather than relying on the average-case as the LCB approach does.
Technical Explanation
The researchers study the problem of offline linear bandits, where the goal is to make a sequence of decisions that minimize the Bayesian regret, given access to some historical data about the rewards.
Prior work has suggested that the optimal strategy is to take actions with the maximum lower confidence bound (LCB) on their reward. However, the researchers argue that this approach is inherently flawed in this setting. Instead, they propose a new algorithm that directly minimizes upper bounds on the Bayesian regret using efficient conic optimization solvers.
The key insight is to leverage new connections between Bayesian regret and monetary risk measures. This allows the researchers to derive tight upper bounds on the regret, which can then be efficiently minimized. Proving a matching lower bound, they show that their upper bounds are tight, and by minimizing them, they are guaranteed to outperform the LCB approach.
The researchers validate their approach through numerical experiments on synthetic domains, confirming that it indeed outperforms the standard LCB method.
Critical Analysis
The paper presents a compelling alternative to the standard LCB approach for offline linear bandits. The researchers make a strong case that the reliance on LCB is flawed, and their proposed algorithm, which directly minimizes upper bounds on Bayesian regret, is a significant improvement.
One potential limitation is the reliance on conic optimization, which may not be as widely accessible or efficient as other optimization techniques. Additionally, the paper focuses on the offline setting, and it would be valuable to understand how the approach might extend to the online case.
Further research could also explore the connections to monetary risk measures in more depth, and investigate whether these insights can be applied to other bandit or reinforcement learning problems. It would also be interesting to see how the method performs on real-world datasets, beyond the synthetic experiments presented in the paper.
Overall, the researchers have made an important contribution to the field of bandit optimization, and their work provides a solid foundation for future research in this area.
Conclusion
This paper presents a novel approach to minimizing Bayesian regret in offline linear bandits. By directly optimizing upper bounds on the regret, rather than relying on the standard lower confidence bound (LCB) method, the researchers demonstrate a significant improvement in performance.
The key insights are the connections to monetary risk measures and the use of efficient conic optimization techniques to minimize these bounds. The researchers prove that their upper bounds are tight, and by minimizing them, they are guaranteed to outperform the LCB approach.
This work has important implications for decision-making in a variety of domains, from recommender systems to financial portfolio optimization. The ability to make provably near-optimal decisions in the face of uncertainty is a valuable capability, and the techniques developed in this paper represent an important step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Bayesian Regret Minimization in Offline Bandits
Marek Petrik, Guy Tennenholtz, Mohammad Ghavamzadeh
We study how to make decisions that minimize Bayesian regret in offline linear bandits. Prior work suggests that one must take actions with maximum lower confidence bound (LCB) on their reward. We argue that the reliance on LCB is inherently flawed in this setting and propose a new algorithm that directly minimizes upper bounds on the Bayesian regret using efficient conic optimization solvers. Our bounds build heavily on new connections to monetary risk measures. Proving a matching lower bound, we show that our upper bounds are tight, and by minimizing them we are guaranteed to outperform the LCB approach. Our numerical results on synthetic domains confirm that our approach is superior to LCB.
Read more7/4/2024
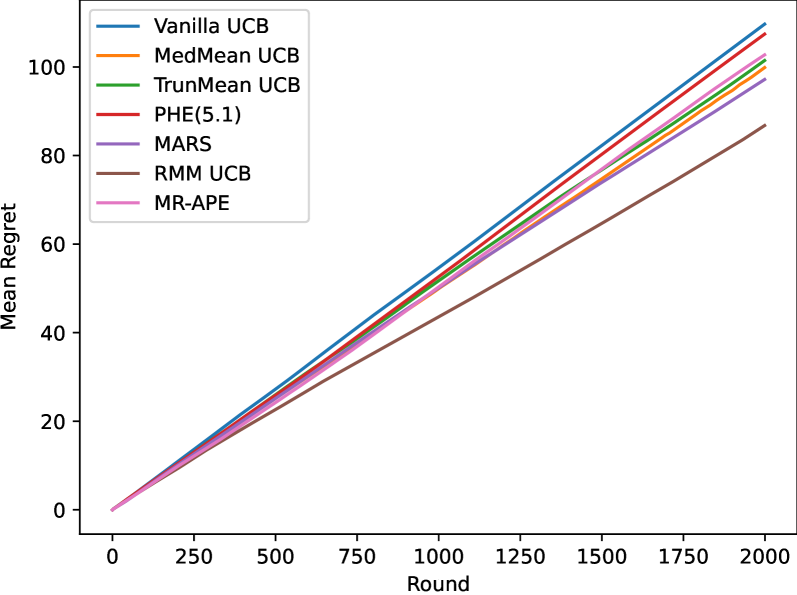
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024

0
Bayesian Bandit Algorithms with Approximate Inference in Stochastic Linear Bandits
Ziyi Huang, Henry Lam, Haofeng Zhang
Bayesian bandit algorithms with approximate Bayesian inference have been widely used in real-world applications. Nevertheless, their theoretical justification is less investigated in the literature, especially for contextual bandit problems. To fill this gap, we propose a general theoretical framework to analyze stochastic linear bandits in the presence of approximate inference and conduct regret analysis on two Bayesian bandit algorithms, Linear Thompson sampling (LinTS) and the extension of Bayesian Upper Confidence Bound, namely Linear Bayesian Upper Confidence Bound (LinBUCB). We demonstrate that both LinTS and LinBUCB can preserve their original rates of regret upper bound but with a sacrifice of larger constant terms when applied with approximate inference. These results hold for general Bayesian inference approaches, under the assumption that the inference error measured by two different $alpha$-divergences is bounded. Additionally, by introducing a new definition of well-behaved distributions, we show that LinBUCB improves the regret rate of LinTS from $tilde{O}(d^{3/2}sqrt{T})$ to $tilde{O}(dsqrt{T})$, matching the minimax optimal rate. To our knowledge, this work provides the first regret bounds in the setting of stochastic linear bandits with bounded approximate inference errors.
Read more6/21/2024
🌀
0
No-Regret is not enough! Bandits with General Constraints through Adaptive Regret Minimization
Martino Bernasconi, Matteo Castiglioni, Andrea Celli
In the bandits with knapsacks framework (BwK) the learner has $m$ resource-consumption (packing) constraints. We focus on the generalization of BwK in which the learner has a set of general long-term constraints. The goal of the learner is to maximize their cumulative reward, while at the same time achieving small cumulative constraints violations. In this scenario, there exist simple instances where conventional methods for BwK fail to yield sublinear violations of constraints. We show that it is possible to circumvent this issue by requiring the primal and dual algorithm to be weakly adaptive. Indeed, even in absence on any information on the Slater's parameter $rho$ characterizing the problem, the interplay between weakly adaptive primal and dual regret minimizers yields a self-bounding property of dual variables. In particular, their norm remains suitably upper bounded across the entire time horizon even without explicit projection steps. By exploiting this property, we provide best-of-both-worlds guarantees for stochastic and adversarial inputs. In the first case, we show that the algorithm guarantees sublinear regret. In the latter case, we establish a tight competitive ratio of $rho/(1+rho)$. In both settings, constraints violations are guaranteed to be sublinear in time. Finally, this results allow us to obtain new result for the problem of contextual bandits with linear constraints, providing the first no-$alpha$-regret guarantees for adversarial contexts.
Read more5/13/2024