Believing Anthropomorphism: Examining the Role of Anthropomorphic Cues on Trust in Large Language Models
2405.06079
0
0
Abstract
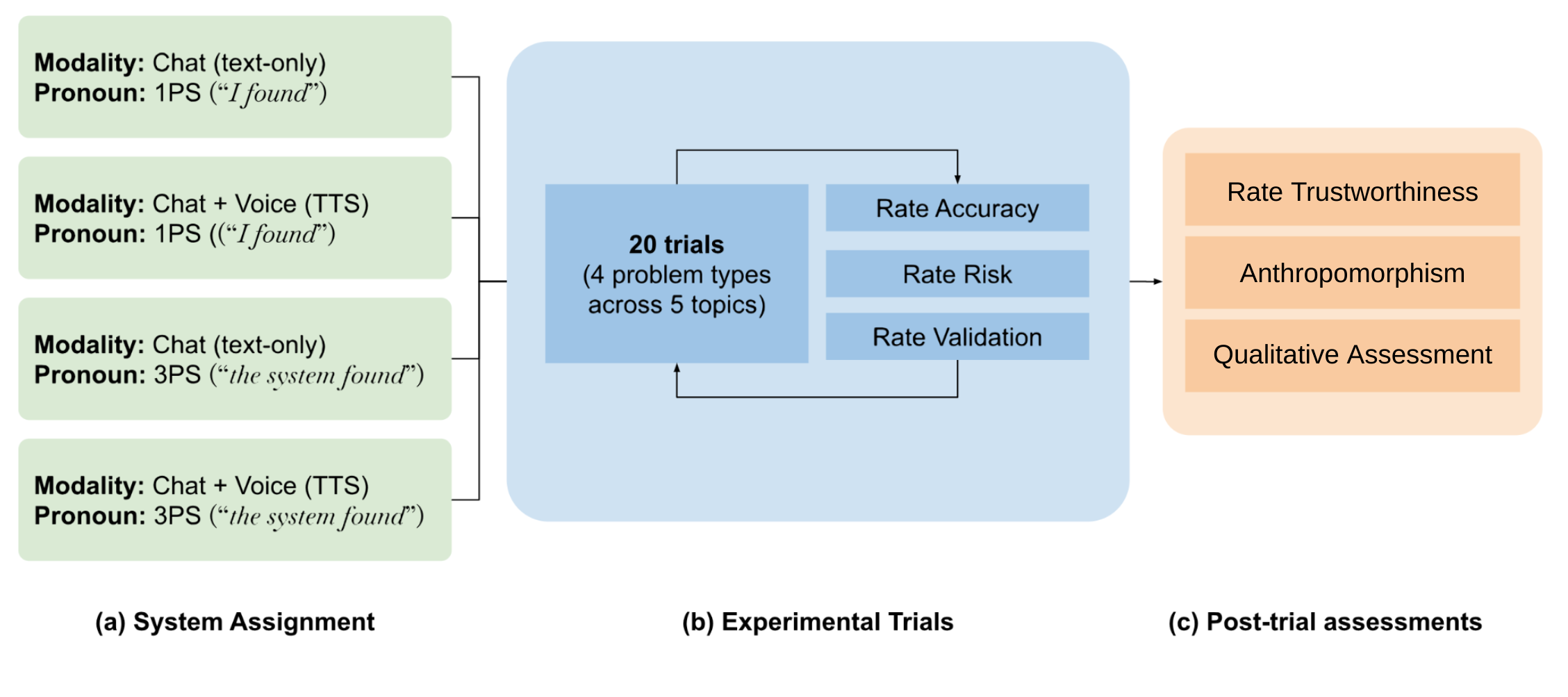
People now regularly interface with Large Language Models (LLMs) via speech and text (e.g., Bard) interfaces. However, little is known about the relationship between how users anthropomorphize an LLM system (i.e., ascribe human-like characteristics to a system) and how they trust the information the system provides. Participants (n=2,165; ranging in age from 18-90 from the United States) completed an online experiment, where they interacted with a pseudo-LLM that varied in modality (text only, speech + text) and grammatical person (I vs. the system) in its responses. Results showed that the speech + text condition led to higher anthropomorphism of the system overall, as well as higher ratings of accuracy of the information the system provides. Additionally, the first-person pronoun (I) led to higher information accuracy and reduced risk ratings, but only in one context. We discuss these findings for their implications for the design of responsible, human-generative AI experiences.
Create account to get full access
Overview
- This research paper examines the role of anthropomorphic cues, such as the use of the first-person pronoun "I", in influencing trust in large language models.
- The study investigates how anthropomorphic features impact user perceptions and interactions with these AI systems.
- The findings have implications for the design and deployment of large language models, particularly in areas where trust and transparency are crucial.
Plain English Explanation
Large language models are advanced AI systems that can understand and generate human-like text. These models are becoming increasingly prevalent in our daily lives, powering chatbots, virtual assistants, and other applications. However, the way these models are presented to users can significantly impact how much users trust them.
This research paper explores the role of anthropomorphic cues, which are design features that make an AI system seem more human-like, in shaping user trust. The researchers specifically looked at the use of the first-person pronoun "I" in the language generated by the AI model. They wanted to see if this subtle linguistic cue would affect how much users trusted the model's capabilities and recommendations.
The researchers conducted experiments where participants interacted with different versions of a large language model, some of which used "I" while others did not. They found that the use of "I" did indeed increase users' trust in the model, even though the underlying capabilities of the system were the same.
This suggests that the way large language models are designed and presented to users can have a significant impact on how much users are willing to rely on them. Anthropomorphic features like the use of "I" can make the AI seem more human-like and trustworthy, which may be important in applications where trust is crucial, such as medical advice or financial recommendations.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of anthropomorphic cues on trust in large language models. They focused specifically on the use of the first-person pronoun "I" in the language generated by the AI system.
In the first experiment, participants interacted with a large language model that provided recommendations for books, movies, and restaurants. The model either used "I" in its responses (e.g., "I recommend this book because...") or did not use "I" (e.g., "This book is recommended because..."). The researchers found that participants rated the model as more trustworthy and competent when it used the "I" pronoun.
In the second experiment, the researchers expanded on these findings by exploring the mechanisms underlying the trust effect. They found that the use of "I" increased participants' perceptions of the model's anthropomorphism, which in turn led to higher levels of trust.
The third experiment examined the robustness of these findings by introducing a more challenging task, where participants had to judge the truthfulness of statements made by the large language model. Again, the researchers found that the use of "I" increased trust and the perceived accuracy of the model's responses.
Overall, the results of this study suggest that the design choices in how large language models are presented to users, such as the use of anthropomorphic cues like the first-person pronoun, can have a significant impact on user trust and reliance on these AI systems. This has important implications for the development and deployment of large language models in real-world applications.
Critical Analysis
The research presented in this paper provides valuable insights into the role of anthropomorphic cues in shaping user trust in large language models. The experimental design and methodology appear rigorous, and the findings are well-supported by the data.
One potential limitation of the study is the reliance on self-reported measures of trust and perceptions. While these are common approaches in psychological research, it would be interesting to see if the observed effects translate to more behavioral measures of trust, such as the willingness to follow the model's recommendations or the amount of time users spend interacting with the system.
Additionally, the study focused on a relatively narrow set of anthropomorphic cues, namely the use of the first-person pronoun "I". While this is a meaningful and well-studied linguistic feature, there may be other anthropomorphic design elements, such as the inclusion of images or the use of conversational language, that could also impact user trust and perceptions.
Finally, the study was conducted in a controlled laboratory setting, which may not fully capture the complex real-world contexts in which large language models are deployed. It would be valuable to explore the generalizability of these findings in more ecologically valid scenarios, where users interact with large language models in their daily lives.
Despite these potential limitations, the research presented in this paper makes an important contribution to our understanding of the human-AI interaction dynamics. As large language models become increasingly prevalent, it is crucial that we carefully consider the design choices that can influence user trust and reliance on these powerful AI systems.
Conclusion
This research paper provides compelling evidence that the design of large language models, specifically the inclusion of anthropomorphic cues like the use of the first-person pronoun "I", can have a significant impact on user trust and perceptions of the model's capabilities.
The findings suggest that the way these AI systems are presented to users is just as important as their underlying technical capabilities. By understanding the role of anthropomorphism in shaping trust, researchers and developers can work to create large language models that are not only powerful, but also transparent, trustworthy, and aligned with human values.
As large language models become increasingly integrated into our daily lives, it is crucial that we continue to explore the human-AI interaction dynamics and ensure that these systems are designed in a way that fosters trust, transparency, and responsible use. The insights provided by this research paper contribute to this important ongoing effort.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
From AI to Probabilistic Automation: How Does Anthropomorphization of Technical Systems Descriptions Influence Trust?
Nanna Inie, Stefania Druga, Peter Zukerman, Emily M. Bender
0
0
This paper investigates the influence of anthropomorphized descriptions of so-called AI (artificial intelligence) systems on people's self-assessment of trust in the system. Building on prior work, we define four categories of anthropomorphization (1. Properties of a cognizer, 2. Agency, 3. Biological metaphors, and 4. Properties of a communicator). We use a survey-based approach (n=954) to investigate whether participants are likely to trust one of two (fictitious) AI systems by randomly assigning people to see either an anthropomorphized or a de-anthropomorphized description of the systems. We find that participants are no more likely to trust anthropomorphized over de-anthropmorphized product descriptions overall. The type of product or system in combination with different anthropomorphic categories appears to exert greater influence on trust than anthropomorphizing language alone, and age is the only demographic factor that significantly correlates with people's preference for anthropomorphized or de-anthropomorphized descriptions. When elaborating on their choices, participants highlight factors such as lesser of two evils, lower or higher stakes contexts, and human favoritism as driving motivations when choosing between product A and B, irrespective of whether they saw an anthropomorphized or a de-anthropomorphized description of the product. Our results suggest that anthropomorphism in AI descriptions is an aggregate concept that may influence different groups differently, and provide nuance to the discussion of whether anthropomorphization leads to higher trust and over-reliance by the general public in systems sold as AI.
4/26/2024

Why Would You Suggest That? Human Trust in Language Model Responses
Manasi Sharma, Ho Chit Siu, Rohan Paleja, Jaime D. Pe~na
0
0
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
6/5/2024

Human Simulacra: Benchmarking the Personification of Large Language Models
Qiuejie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, Yue Zhang
0
0
Large language models (LLMs) are recognized as systems that closely mimic aspects of human intelligence. This capability has attracted attention from the social science community, who see the potential in leveraging LLMs to replace human participants in experiments, thereby reducing research costs and complexity. In this paper, we introduce a framework for large language models personification, including a strategy for constructing virtual characters' life stories from the ground up, a Multi-Agent Cognitive Mechanism capable of simulating human cognitive processes, and a psychology-guided evaluation method to assess human simulations from both self and observational perspectives. Experimental results demonstrate that our constructed simulacra can produce personified responses that align with their target characters. Our work is a preliminary exploration which offers great potential in practical applications. All the code and datasets will be released, with the hope of inspiring further investigations.
6/11/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
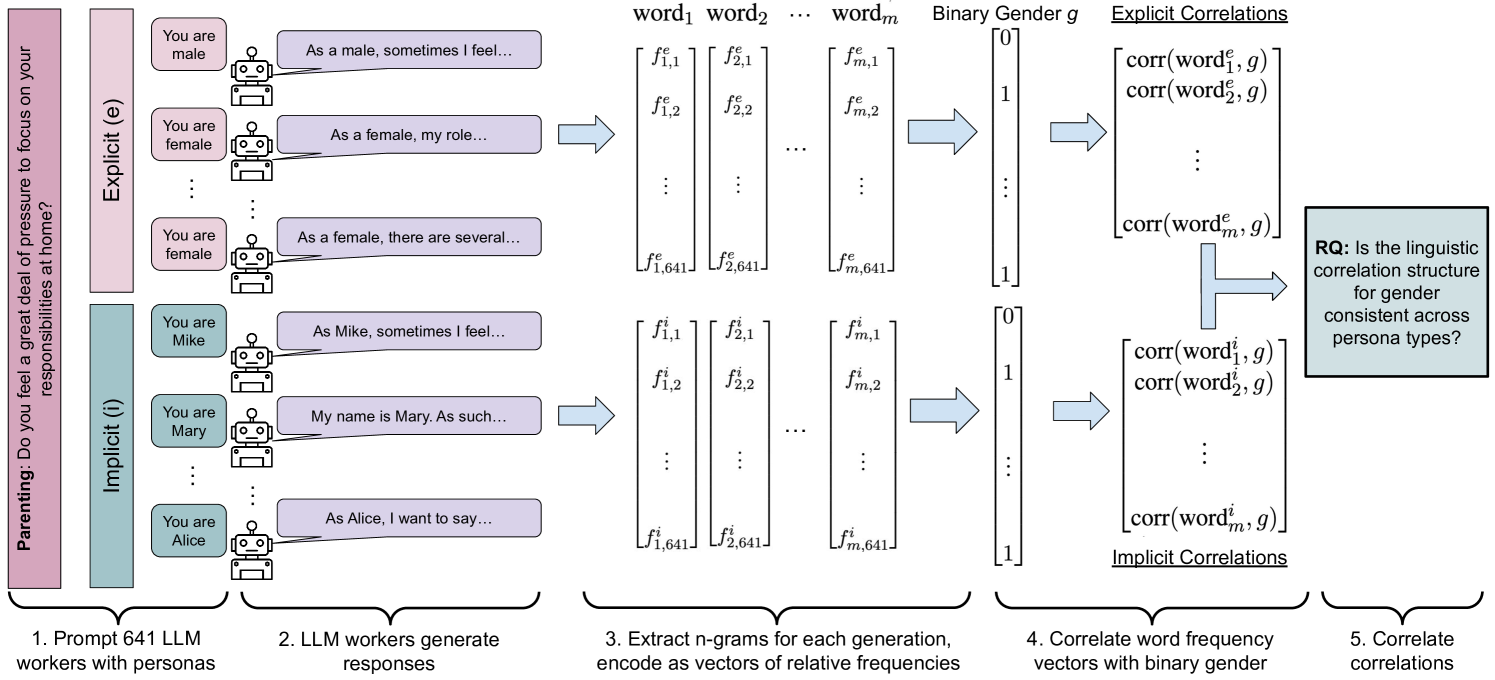
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024