Human Simulacra: Benchmarking the Personification of Large Language Models

0

Sign in to get full access
Overview
- The paper presents the "Human Simulacra" dataset, which aims to create personalized profiles of individuals to help large language models (LLMs) become more personified and human-like.
- The dataset contains detailed information about individuals, including their personality traits, interests, and behaviors, to enable LLMs to simulate more authentic human interactions.
- The researchers argue that this dataset and approach can help address the limitations of LLMs in fully capturing the nuances of human behavior and psychology, as highlighted in related research (Limited Ability of LLMs to Simulate Human Psychological Processes) and (Concerns About Bias in Large Language Models When Creating Anthropomorphic Agents).
Plain English Explanation
The paper describes a new dataset called "Human Simulacra" that aims to help large language models (LLMs) become more human-like and personified. LLMs are AI systems that can generate human-like text, but they often struggle to fully capture the nuances of human behavior and psychology.
The Human Simulacra dataset contains detailed information about individual people, including their personality traits, interests, and behaviors. The researchers believe that by providing LLMs with this rich data, the models can better simulate authentic human interactions and become more personalized.
This approach is meant to address limitations of LLMs identified in related research, such as their limited ability to simulate human psychological processes and concerns about bias when creating anthropomorphic agents. By creating more personalized and human-like LLMs, the researchers hope to improve the quality and realism of AI-powered interactions.
Technical Explanation
The paper introduces the "Human Simulacra" dataset, which is designed to help large language models (LLMs) become more personified and human-like. The dataset contains detailed profiles of individuals, including information about their personality traits, interests, and behaviors.
The researchers argue that this dataset can help address limitations of LLMs identified in related research, such as their limited ability to simulate human psychological processes and concerns about bias when creating anthropomorphic agents. By providing LLMs with rich, personalized data about individuals, the models can better simulate authentic human interactions and become more realistic.
The paper details the process of creating the Human Simulacra dataset, including the sources of information used and the methods for compiling the individual profiles. The researchers also discuss the potential applications of this dataset, such as improving the personalization and realism of chatbots, virtual assistants, and other AI-powered interactions.
Critical Analysis
The paper presents a novel approach to addressing the limitations of large language models (LLMs) in capturing the nuances of human behavior and psychology. By creating the "Human Simulacra" dataset, the researchers aim to provide LLMs with more detailed and personalized information about individuals, which could help improve the realism and authenticity of AI-powered interactions.
However, the paper does not fully address the potential challenges and limitations of this approach. For example, it does not explore the difficulties of accurately capturing and representing the complexity of human personalities, or the potential for bias and inaccuracies in the dataset itself. Additionally, the paper does not discuss the ethical considerations of creating highly personalized AI agents, such as concerns about privacy, manipulation, and the anthropomorphization of technology (Believing in Anthropomorphism: Examining the Role of Anthropomorphic Cues in Cultivating User Trust).
Further research is needed to fully understand the implications and potential risks of this approach, as well as to explore alternative methods for improving the personalization and realism of LLMs without relying on detailed personal profiles. Nonetheless, the Human Simulacra dataset represents an interesting step towards the personification of LLMs and could lead to valuable insights in the field of AI development and human-computer interaction.
Conclusion
The "Human Simulacra" dataset presented in this paper is a novel approach to improving the personification and realism of large language models (LLMs). By providing LLMs with detailed profiles of individuals, including their personality traits, interests, and behaviors, the researchers aim to address the limitations of LLMs in fully capturing the nuances of human behavior and psychology.
While this approach has the potential to enhance the quality and authenticity of AI-powered interactions, it also raises important questions and concerns that require further exploration. Researchers and developers must carefully consider the ethical implications of creating highly personalized AI agents, as well as the potential for bias and inaccuracies in the underlying data.
Overall, the Human Simulacra dataset represents an interesting step towards the personification of LLMs, and the insights gained from this research could have significant implications for the future development of AI systems that can more effectively engage with and understand human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Human Simulacra: Benchmarking the Personification of Large Language Models
Qiuejie Xie, Qiming Feng, Tianqi Zhang, Qingqiu Li, Linyi Yang, Yuejie Zhang, Rui Feng, Liang He, Shang Gao, Yue Zhang
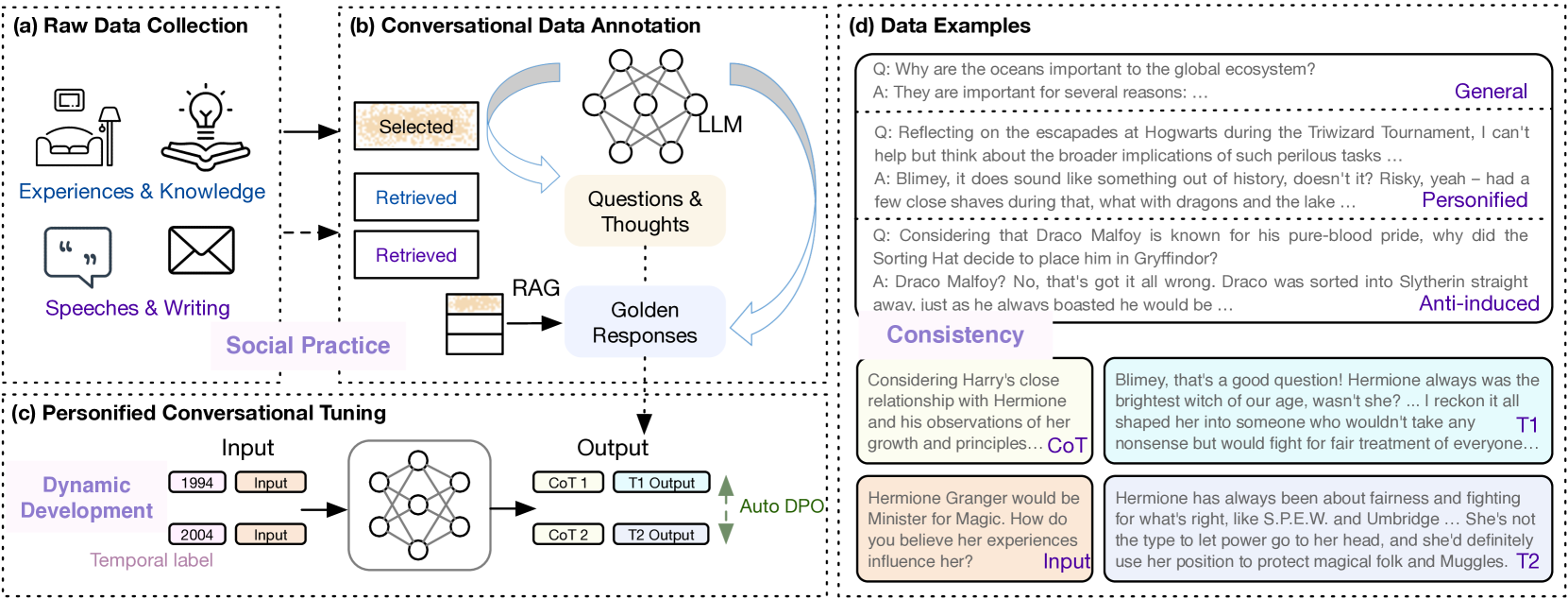
Large language models (LLMs) are recognized as systems that closely mimic aspects of human intelligence. This capability has attracted attention from the social science community, who see the potential in leveraging LLMs to replace human participants in experiments, thereby reducing research costs and complexity. In this paper, we introduce a framework for large language models personification, including a strategy for constructing virtual characters' life stories from the ground up, a Multi-Agent Cognitive Mechanism capable of simulating human cognitive processes, and a psychology-guided evaluation method to assess human simulations from both self and observational perspectives. Experimental results demonstrate that our constructed simulacra can produce personified responses that align with their target characters. Our work is a preliminary exploration which offers great potential in practical applications. All the code and datasets will be released, with the hope of inspiring further investigations.
Read more6/11/2024
0
PersLLM: A Personified Training Approach for Large Language Models
Zheni Zeng, Jiayi Chen, Huimin Chen, Yukun Yan, Yuxuan Chen, Zhenghao Liu, Zhiyuan Liu, Maosong Sun
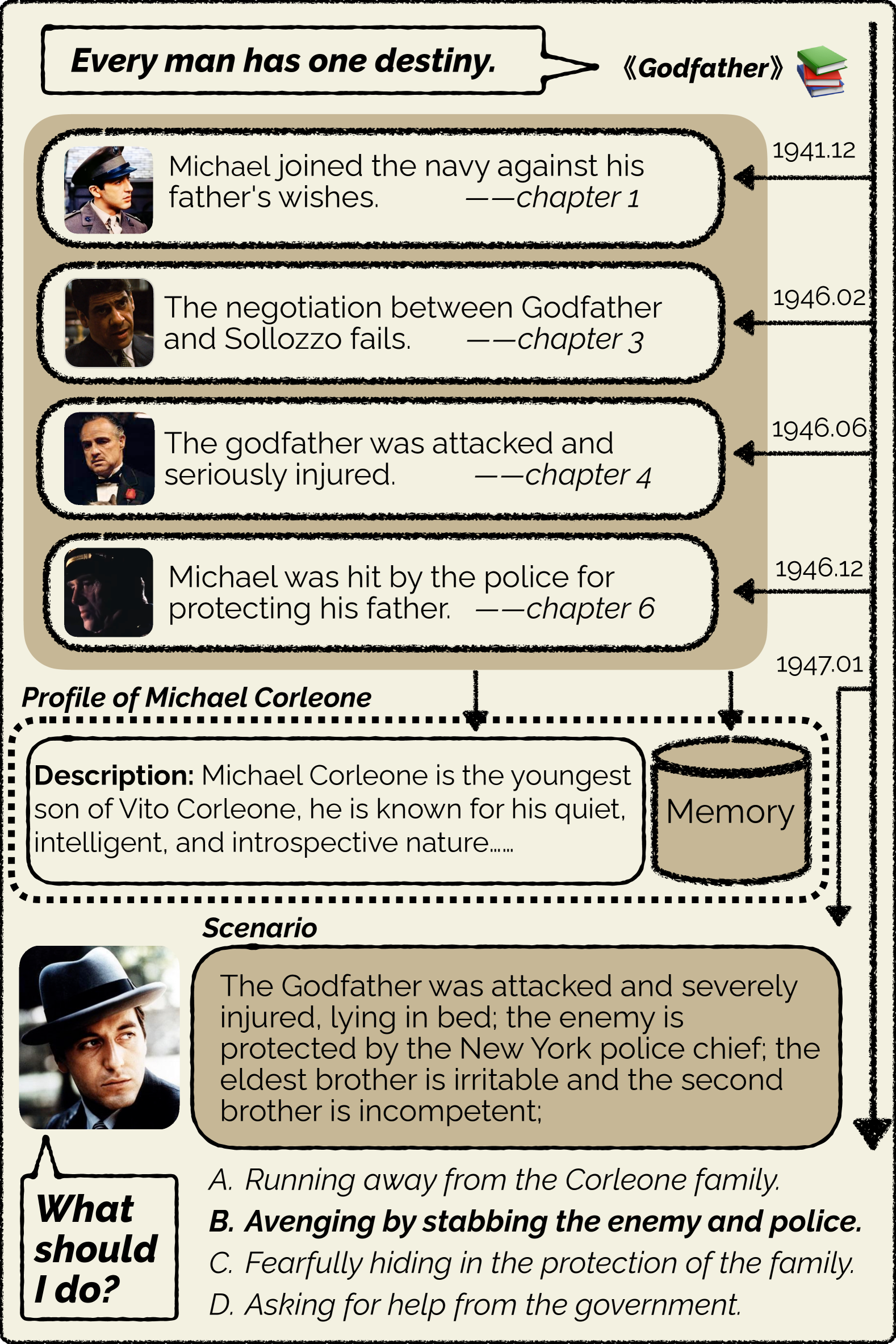
Large language models exhibit aspects of human-level intelligence that catalyze their application as human-like agents in domains such as social simulations, human-machine interactions, and collaborative multi-agent systems. However, the absence of distinct personalities, such as displaying ingratiating behaviors, inconsistent opinions, and uniform response patterns, diminish LLMs utility in practical applications. Addressing this, the development of personality traits in LLMs emerges as a crucial area of research to unlock their latent potential. Existing methods to personify LLMs generally involve strategies like employing stylized training data for instruction tuning or using prompt engineering to simulate different personalities. These methods only capture superficial linguistic styles instead of the core of personalities and are therefore not stable. In this study, we propose PersLLM, integrating psychology-grounded principles of personality: social practice, consistency, and dynamic development, into a comprehensive training methodology. We incorporate personality traits directly into the model parameters, enhancing the model's resistance to induction, promoting consistency, and supporting the dynamic evolution of personality. Single-agent evaluation validates our method's superiority, as it produces responses more aligned with reference personalities compared to other approaches. Case studies for multi-agent communication highlight its benefits in enhancing opinion consistency within individual agents and fostering collaborative creativity among multiple agents in dialogue contexts, potentially benefiting human simulation and multi-agent cooperation. Additionally, human-agent interaction evaluations indicate that our personified models significantly enhance interactive experiences, underscoring the practical implications of our research.
Read more7/29/2024
0
Character is Destiny: Can Large Language Models Simulate Persona-Driven Decisions in Role-Playing?
Rui Xu, Xintao Wang, Jiangjie Chen, Siyu Yuan, Xinfeng Yuan, Jiaqing Liang, Zulong Chen, Xiaoqing Dong, Yanghua Xiao
Can Large Language Models substitute humans in making important decisions? Recent research has unveiled the potential of LLMs to role-play assigned personas, mimicking their knowledge and linguistic habits. However, imitative decision-making requires a more nuanced understanding of personas. In this paper, we benchmark the ability of LLMs in persona-driven decision-making. Specifically, we investigate whether LLMs can predict characters' decisions provided with the preceding stories in high-quality novels. Leveraging character analyses written by literary experts, we construct a dataset LIFECHOICE comprising 1,401 character decision points from 395 books. Then, we conduct comprehensive experiments on LIFECHOICE, with various LLMs and methods for LLM role-playing. The results demonstrate that state-of-the-art LLMs exhibit promising capabilities in this task, yet there is substantial room for improvement. Hence, we further propose the CHARMAP method, which achieves a 6.01% increase in accuracy via persona-based memory retrieval. We will make our datasets and code publicly available.
Read more4/19/2024
💬
0
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, Jad Kabbara
Despite the many use cases for large language models (LLMs) in creating personalized chatbots, there has been limited research on evaluating the extent to which the behaviors of personalized LLMs accurately and consistently reflect specific personality traits. We consider studying the behavior of LLM-based agents which we refer to as LLM personas and present a case study with GPT-3.5 and GPT-4 to investigate whether LLMs can generate content that aligns with their assigned personality profiles. To this end, we simulate distinct LLM personas based on the Big Five personality model, have them complete the 44-item Big Five Inventory (BFI) personality test and a story writing task, and then assess their essays with automatic and human evaluations. Results show that LLM personas' self-reported BFI scores are consistent with their designated personality types, with large effect sizes observed across five traits. Additionally, LLM personas' writings have emerging representative linguistic patterns for personality traits when compared with a human writing corpus. Furthermore, human evaluation shows that humans can perceive some personality traits with an accuracy of up to 80%. Interestingly, the accuracy drops significantly when the annotators were informed of AI authorship.
Read more4/3/2024