Benchingmaking Large Langage Models in Biomedical Triple Extraction
2310.18463
0
0
⛏️
Abstract
Biomedical triple extraction systems aim to automatically extract biomedical entities and relations between entities. The exploration of applying large language models (LLM) to triple extraction is still relatively unexplored. In this work, we mainly focus on sentence-level biomedical triple extraction. Furthermore, the absence of a high-quality biomedical triple extraction dataset impedes the progress in developing robust triple extraction systems. To address these challenges, initially, we compare the performance of various large language models. Additionally, we present GIT, an expert-annotated biomedical triple extraction dataset that covers a wider range of relation types.
Create account to get full access
Overview
- This paper focuses on biomedical triple extraction, which aims to automatically extract biomedical entities and the relationships between them.
- The researchers explore the use of large language models (LLMs) for this task, as it is a relatively unexplored area.
- They also present a new dataset, GIT, which is an expert-annotated biomedical triple extraction dataset with a wider range of relation types.
Plain English Explanation
The paper explores the use of large language models to automatically extract information from biomedical texts. Specifically, the researchers are interested in extracting biomedical entities (e.g., drugs, diseases, genes) and the relationships between them (e.g., drug treats disease, gene causes disease).
This type of information extraction is important for advancing biomedical research and understanding complex relationships in the field. However, it can be challenging to do this automatically, as biomedical texts often contain specialized terminology and complex concepts.
To address these challenges, the researchers first compare the performance of various large language models on the task of biomedical triple extraction. This helps them understand which models work best for this specific application.
Additionally, the researchers present a new dataset called GIT, which is a collection of biomedical texts that have been carefully annotated by experts to identify the entities and relationships. This dataset can be used to train and evaluate biomedical triple extraction systems, and it covers a wider range of relationship types than previous datasets.
By exploring the use of large language models and creating a high-quality dataset, the researchers hope to improve the performance and robustness of biomedical triple extraction systems, which could have significant implications for biomedical research and discovery.
Technical Explanation
The paper evaluates the performance of various large language models on the task of sentence-level biomedical triple extraction. This involves identifying biomedical entities, such as drugs, diseases, and genes, and the relationships between them, such as "drug treats disease" or "gene causes disease."
To support this research, the authors introduce a new dataset called GIT (Genome Interaction Triplets), which is an expert-annotated biomedical triple extraction dataset. GIT covers a wider range of relation types compared to previous datasets, which the authors argue is an important step in developing robust triple extraction systems.
The researchers experiment with several large language models, including BERT, RoBERTa, and BioBERT, to assess their performance on the biomedical triple extraction task. They evaluate the models on various metrics, such as precision, recall, and F1 score, to understand their strengths and weaknesses.
The results of their experiments show that large language models can be effective for biomedical triple extraction, but there is still room for improvement. The authors discuss potential avenues for further research, such as exploring model collaboration strategies or incorporating domain-specific knowledge to enhance the performance of these systems.
Critical Analysis
The paper provides a valuable contribution to the field of biomedical information extraction by exploring the use of large language models for the specific task of biomedical triple extraction. The introduction of the GIT dataset is particularly noteworthy, as it addresses the lack of high-quality datasets that has been a significant barrier to progress in this area.
However, the paper does not delve into the potential limitations or biases of the large language models used in the study. It would be helpful to understand the specific challenges these models face when applied to biomedical texts, such as their ability to handle domain-specific terminology and complex relationships.
Additionally, the paper could have discussed the potential ethical implications of biomedical triple extraction systems, particularly around issues of data privacy and the responsible use of these technologies in healthcare and research settings. Incorporating ethical considerations is an important aspect of developing AI systems for sensitive domains.
Overall, the paper presents a promising approach to biomedical triple extraction and highlights the potential of large language models in this area. However, further research is needed to address the limitations and potential concerns raised, and to continue improving the performance and robustness of these systems.
Conclusion
This paper explores the use of large language models for the task of biomedical triple extraction, which involves automatically identifying biomedical entities and the relationships between them. The researchers introduce a new dataset called GIT, which is an expert-annotated collection of biomedical texts with a wide range of relation types.
The experimental results show that large language models can be effective for biomedical triple extraction, but there is still room for improvement. The authors discuss potential avenues for further research, such as exploring model collaboration strategies and incorporating domain-specific knowledge.
Overall, this work represents an important step forward in the development of robust biomedical information extraction systems, which have the potential to significantly impact biomedical research and discovery. As the field continues to evolve, it will be crucial to address the limitations and ethical considerations raised in this paper to ensure these technologies are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
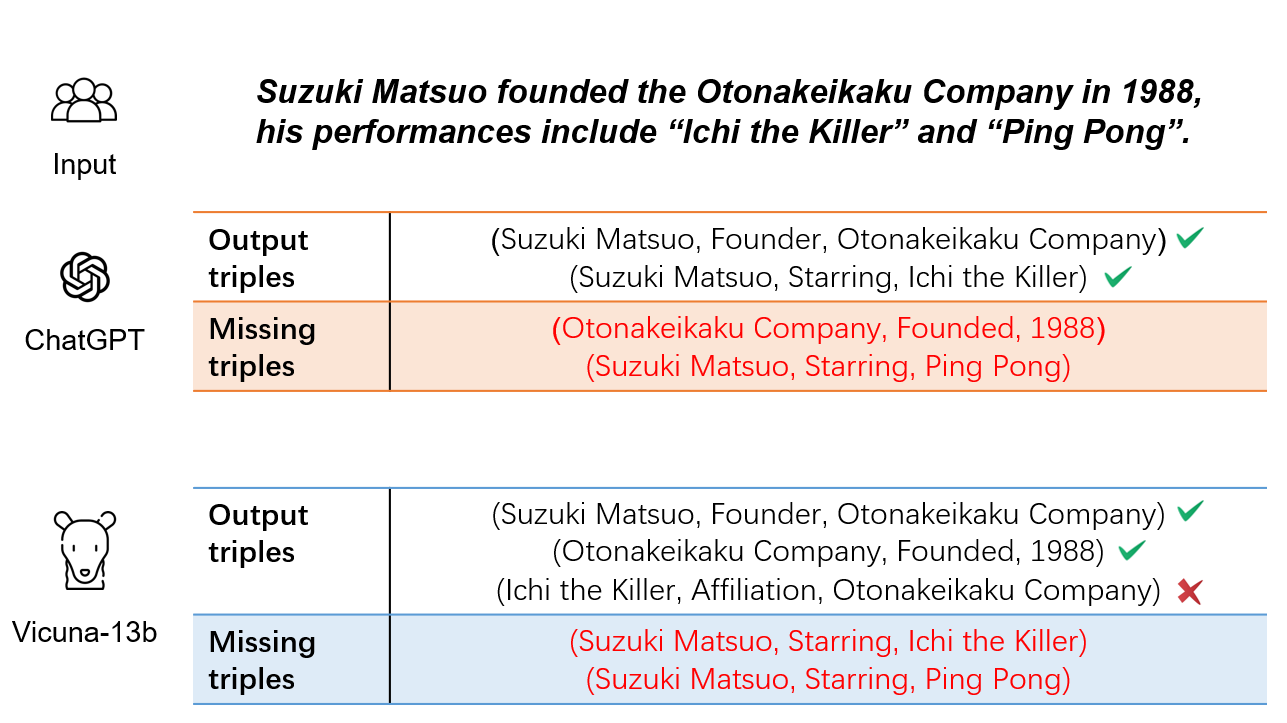
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
0
0
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
4/16/2024
Intent Detection and Entity Extraction from BioMedical Literature
Ankan Mullick, Mukur Gupta, Pawan Goyal
0
0
Biomedical queries have become increasingly prevalent in web searches, reflecting the growing interest in accessing biomedical literature. Despite recent research on large-language models (LLMs) motivated by endeavours to attain generalized intelligence, their efficacy in replacing task and domain-specific natural language understanding approaches remains questionable. In this paper, we address this question by conducting a comprehensive empirical evaluation of intent detection and named entity recognition (NER) tasks from biomedical text. We show that Supervised Fine Tuned approaches are still relevant and more effective than general-purpose LLMs. Biomedical transformer models such as PubMedBERT can surpass ChatGPT on NER task with only 5 supervised examples.
4/5/2024
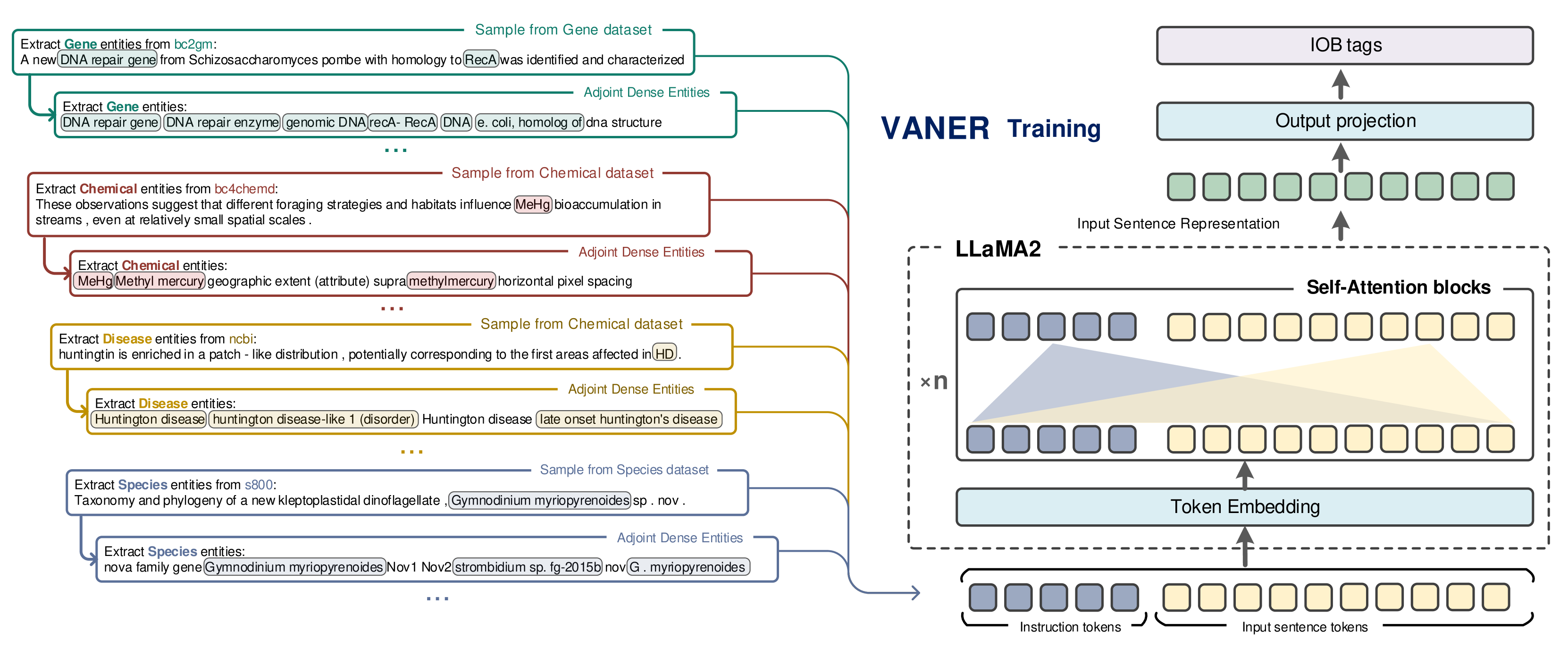
VANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Junyi Biana, Weiqi Zhai, Xiaodi Huang, Jiaxuan Zheng, Shanfeng Zhu
0
0
Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
4/30/2024
👁️
LLMs in Biomedicine: A study on clinical Named Entity Recognition
Masoud Monajatipoor, Jiaxin Yang, Joel Stremmel, Melika Emami, Fazlolah Mohaghegh, Mozhdeh Rouhsedaghat, Kai-Wei Chang
0
0
Large Language Models (LLMs) demonstrate remarkable versatility in various NLP tasks but encounter distinct challenges in biomedicine due to medical language complexities and data scarcity. This paper investigates the application of LLMs in the medical domain by exploring strategies to enhance their performance for the Named-Entity Recognition (NER) task. Specifically, our study reveals the importance of meticulously designed prompts in biomedicine. Strategic selection of in-context examples yields a notable improvement, showcasing ~15-20% increase in F1 score across all benchmark datasets for few-shot clinical NER. Additionally, our findings suggest that integrating external resources through prompting strategies can bridge the gap between general-purpose LLM proficiency and the specialized demands of medical NER. Leveraging a medical knowledge base, our proposed method inspired by Retrieval-Augmented Generation (RAG) can boost the F1 score of LLMs for zero-shot clinical NER. We will release the code upon publication.
4/12/2024