Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
2404.09593
0
0
Abstract
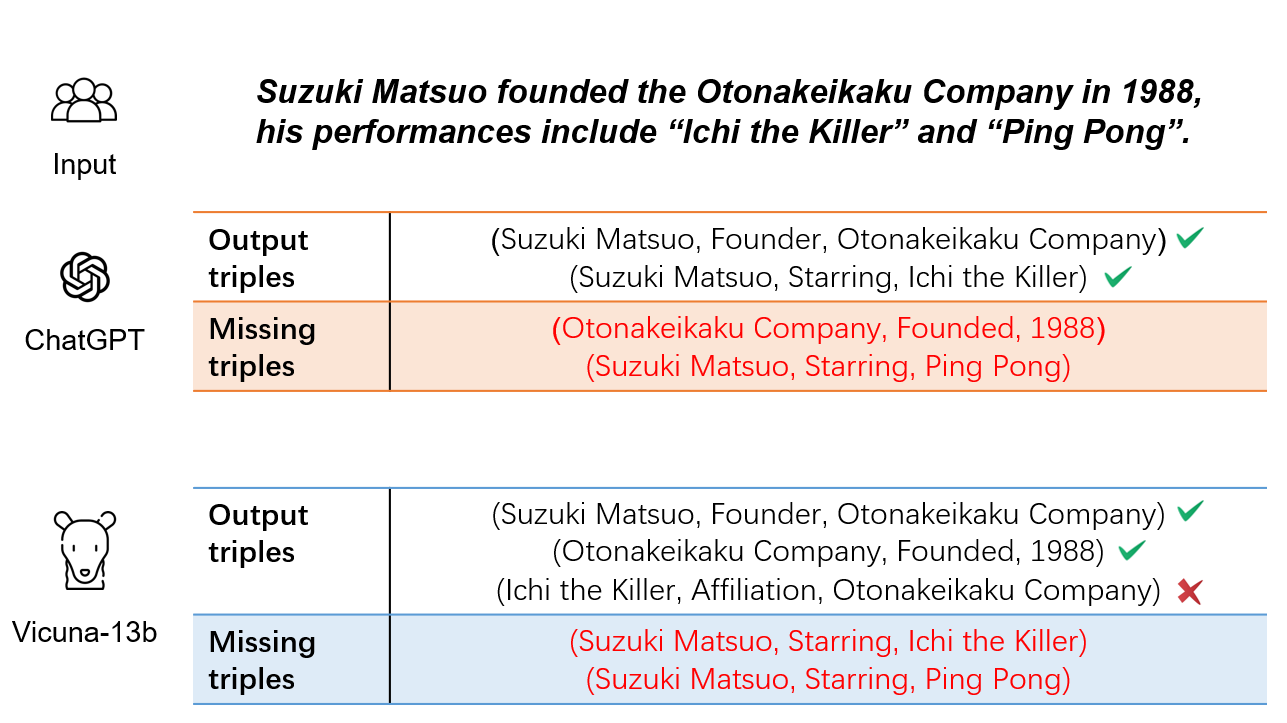
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
Create account to get full access
Overview
- This paper proposes a model collaboration approach to improve the recall of large language models for extracting relational triples from text.
- The key idea is to combine the strengths of multiple specialized models to achieve higher overall performance on this task.
- The authors experiment with different strategies for integrating the outputs of these specialized models and evaluate the impact on both precision and recall.
Plain English Explanation
Large language models, like GPT-3, are powerful tools that can be used for a variety of natural language processing tasks, including extracting information from text. However, these models can sometimes struggle with recalling specific details, which can limit their usefulness for certain applications.
The researchers who wrote this paper wanted to find a way to improve the recall of large language models when extracting relational triples - that is, identifying the relationships between entities mentioned in a piece of text. To do this, they developed a "model collaboration" approach, where they combined the outputs of multiple specialized models, each focused on a different aspect of the triple extraction task.
For example, one model might be better at identifying the entities in a sentence, while another might be better at determining the relationships between them. By combining the outputs of these models, the researchers were able to achieve higher overall recall without sacrificing too much precision.
The paper describes the different strategies they tested for integrating the outputs of the specialized models, and presents the results of their experiments. Overall, the model collaboration approach seems to be a promising way to enhance the capabilities of large language models and make them more useful for real-world applications.
Technical Explanation
The key technical innovation in this paper is the use of a "model collaboration" approach for relational triple extraction. The authors start with the observation that large language models like GPT-3 can struggle with recall on this task, meaning they may miss important relationships between entities in the text.
To address this, the researchers developed a system that combines the outputs of multiple specialized models, each focused on a different aspect of the triple extraction process. For example, one model might be optimized for entity recognition, while another focuses on relation classification. By integrating the results of these complementary models, the authors were able to achieve higher overall recall without sacrificing too much precision.
The paper explores several different strategies for combining the model outputs, including simple majority voting, weighted averaging, and more sophisticated attention-based approaches. The authors evaluate the performance of these different integration methods on standard benchmark datasets, comparing their results to both individual models and other state-of-the-art triple extraction systems.
The results show that the model collaboration approach can significantly improve recall, in some cases by over 10 percentage points, while maintaining competitive precision. The authors also provide detailed ablation studies to understand the contributions of the different specialized models and integration techniques.
Critical Analysis
One potential limitation of this work is that it relies on having access to multiple specialized models, which may not always be feasible in practice. The authors do not explore how their approach would scale if the number of available models was more limited.
Additionally, the paper does not delve deeply into the potential biases or errors that may be introduced by the individual specialized models. It would be valuable to understand how the model collaboration approach handles cases where the component models disagree or make systematic mistakes.
Further research could also explore whether the benefits of this approach extend beyond relational triple extraction, and whether similar techniques could be applied to improve the performance of large language models on other NLP tasks. The authors briefly mention potential extensions to other structured prediction problems, but do not provide a detailed analysis.
Overall, the model collaboration approach presented in this paper is a promising direction for enhancing the capabilities of large language models. The experimental results are compelling, and the underlying ideas could have broader implications for the field of natural language processing.
Conclusion
This paper introduces a novel model collaboration approach to improve the recall of large language models on the task of relational triple extraction. By combining the outputs of multiple specialized models, the researchers were able to achieve significant gains in recall without sacrificing too much precision.
The results of this work suggest that leveraging the complementary strengths of different models can be an effective strategy for overcoming the limitations of any single model. While the paper focuses on triple extraction, the general principles could potentially be applied to other structured prediction problems in NLP.
As large language models continue to grow in power and ubiquity, techniques like the one proposed in this paper will be increasingly important for unlocking their full potential and making them more reliable and useful in real-world applications. The critical analysis highlights some areas for further exploration, but overall, this research represents an important step forward in enhancing the capabilities of these transformative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Benchingmaking Large Langage Models in Biomedical Triple Extraction
Mingchen Li, Huixue Zhou, Rui Zhang
0
0
Biomedical triple extraction systems aim to automatically extract biomedical entities and relations between entities. The exploration of applying large language models (LLM) to triple extraction is still relatively unexplored. In this work, we mainly focus on sentence-level biomedical triple extraction. Furthermore, the absence of a high-quality biomedical triple extraction dataset impedes the progress in developing robust triple extraction systems. To address these challenges, initially, we compare the performance of various large language models. Additionally, we present GIT, an expert-annotated biomedical triple extraction dataset that covers a wider range of relation types.
4/17/2024
A Bi-consolidating Model for Joint Relational Triple Extraction
Xiaocheng Luo, Yanping Chen, Ruixue Tang, Ruizhang Huang, Yongbin Qin
0
0
Current methods to extract relational triples directly make a prediction based on a possible entity pair in a raw sentence without depending on entity recognition. The task suffers from a serious semantic overlapping problem, in which several relation triples may share one or two entities in a sentence. It is weak to learn discriminative semantic features relevant to a relation triple. In this paper, based on a two-dimensional sentence representation, a bi-consolidating model is proposed to address this problem by simultaneously reinforcing the local and global semantic features relevant to a relation triple. This model consists of a local consolidation component and a global consolidation component. The first component uses a pixel difference convolution to enhance semantic information of a possible triple representation from adjacent regions and mitigate noise in neighbouring neighbours. The second component strengthens the triple representation based a channel attention and a spatial attention, which has the advantage to learn remote semantic dependencies in a sentence. They are helpful to improve the performance of both entity identification and relation type classification in relation triple extraction. After evaluated on several publish datasets, it achieves competitive performance. Analytical experiments demonstrate the effectiveness of our model for relational triple extraction and give motivation for other natural language processing tasks.
4/8/2024
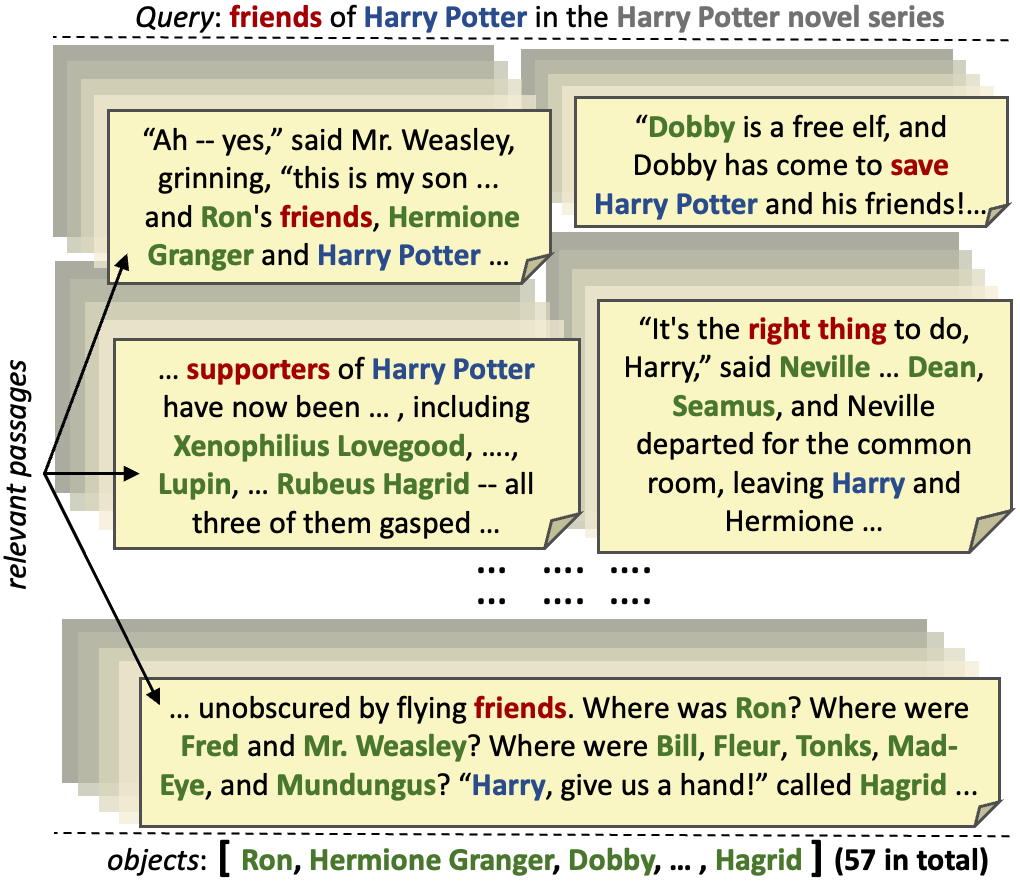
Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
Sneha Singhania, Simon Razniewski, Gerhard Weikum
0
0
Methods for relation extraction from text mostly focus on high precision, at the cost of limited recall. High recall is crucial, though, to populate long lists of object entities that stand in a specific relation with a given subject. Cues for relevant objects can be spread across many passages in long texts. This poses the challenge of extracting long lists from long texts. We present the L3X method which tackles the problem in two stages: (1) recall-oriented generation using a large language model (LLM) with judicious techniques for retrieval augmentation, and (2) precision-oriented scrutinization to validate or prune candidates. Our L3X method outperforms LLM-only generations by a substantial margin.
5/7/2024

Empirical Analysis of Dialogue Relation Extraction with Large Language Models
Guozheng Li, Zijie Xu, Ziyu Shang, Jiajun Liu, Ke Ji, Yikai Guo
0
0
Dialogue relation extraction (DRE) aims to extract relations between two arguments within a dialogue, which is more challenging than standard RE due to the higher person pronoun frequency and lower information density in dialogues. However, existing DRE methods still suffer from two serious issues: (1) hard to capture long and sparse multi-turn information, and (2) struggle to extract golden relations based on partial dialogues, which motivates us to discover more effective methods that can alleviate the above issues. We notice that the rise of large language models (LLMs) has sparked considerable interest in evaluating their performance across diverse tasks. To this end, we initially investigate the capabilities of different LLMs in DRE, considering both proprietary models and open-source models. Interestingly, we discover that LLMs significantly alleviate two issues in existing DRE methods. Generally, we have following findings: (1) scaling up model size substantially boosts the overall DRE performance and achieves exceptional results, tackling the difficulty of capturing long and sparse multi-turn information; (2) LLMs encounter with much smaller performance drop from entire dialogue setting to partial dialogue setting compared to existing methods; (3) LLMs deliver competitive or superior performances under both full-shot and few-shot settings compared to current state-of-the-art; (4) LLMs show modest performances on inverse relations but much stronger improvements on general relations, and they can handle dialogues of various lengths especially for longer sequences.
4/30/2024