Benchmarking Counterfactual Interpretability in Deep Learning Models for Time Series Classification

0

Sign in to get full access
Overview
- This paper presents a benchmarking framework for evaluating the counterfactual interpretability of deep learning models for time series classification.
- Counterfactual explanations are important for interpretable AI, as they can help users understand how changes to input features would affect a model's predictions.
- The authors propose several metrics to assess the quality and diversity of counterfactual explanations generated by different interpretability methods.
Plain English Explanation
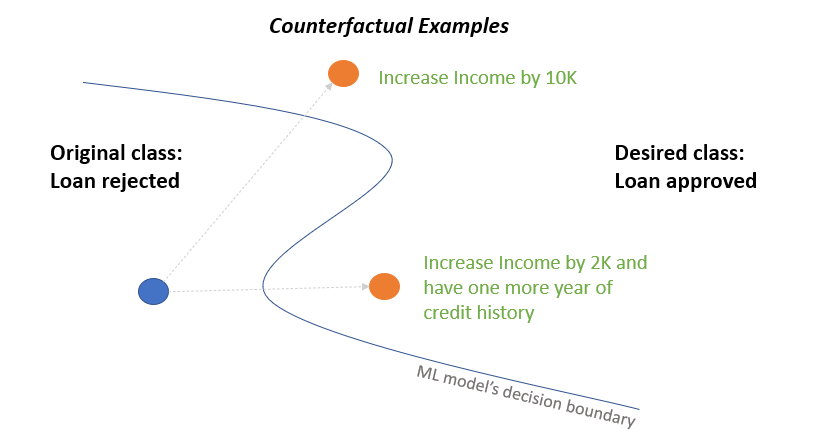
Interpreting how machine learning models make decisions is an important challenge, especially for sensitive applications like healthcare or finance. Counterfactual explanations can help with this by showing how changing the input to a model would change its output.
In this paper, the researchers developed a way to benchmark the quality of counterfactual explanations produced by different interpretability methods for deep learning models used in time series classification tasks. They proposed several metrics to measure things like how realistic the counterfactual examples are, how diverse they are, and how well they capture the model's decision-making process.
By applying these benchmarking techniques, the researchers hope to help advance the development of more interpretable deep learning models that can provide users with meaningful explanations for their predictions. This could increase trust and transparency in high-stakes applications of AI.
Technical Explanation
The paper focuses on evaluating counterfactual interpretability methods for deep learning models applied to time series classification tasks. Counterfactual explanations show how changes to the input features of a model would affect its output predictions. The authors propose several metrics to assess the quality and diversity of the counterfactual examples generated by different interpretability techniques:
- Plausibility: How realistic or similar to the original input are the counterfactual examples?
- Diversity: How different are the counterfactual examples from each other?
- Faithfulness: How well do the counterfactual examples capture the model's decision-making process?
- Stability: How consistent are the counterfactual examples across multiple runs of the interpretability method?
The authors apply these benchmarking techniques to evaluate several counterfactual interpretability algorithms on multiple time series datasets and model architectures. Their results provide insights into the strengths and limitations of these methods and highlight areas for future improvement.
Critical Analysis
The paper presents a well-designed benchmarking framework for assessing counterfactual interpretability in a rigorous, systematic way. The proposed metrics cover important aspects of explanation quality, and the experiments provide valuable empirical comparisons across a range of methods and datasets.
One potential limitation is that the benchmarking is focused solely on time series classification tasks. The transferability of these techniques to other domains, such as image or text classification, is not explicitly evaluated. Additionally, the paper does not delve into the computational efficiency or scalability of the different interpretability algorithms, which could be an important practical consideration.
Further research could explore the human interpretability and usability of the generated counterfactual explanations, as well as their impact on user trust and decision-making. Investigating the robustness of the counterfactual examples to adversarial perturbations could also be a valuable direction.
Conclusion
This paper presents a comprehensive benchmarking framework for evaluating the counterfactual interpretability of deep learning models for time series classification. By proposing several quality metrics and applying them to a range of interpretability methods, the authors provide important insights into the strengths and limitations of current approaches. This work represents a significant step forward in developing more interpretable and trustworthy AI systems, particularly for high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Counterfactual Interpretability in Deep Learning Models for Time Series Classification
Ziwen Kan, Shahbaz Rezaei, Xin liu
The popularity of deep learning methods in the time series domain boosts interest in interpretability studies, including counterfactual (CF) methods. CF methods identify minimal changes in instances to alter the model predictions. Despite extensive research, no existing work benchmarks CF methods in the time series domain. Additionally, the results reported in the literature are inconclusive due to the limited number of datasets and inadequate metrics. In this work, we redesign quantitative metrics to accurately capture desirable characteristics in CFs. We specifically redesign the metrics for sparsity and plausibility and introduce a new metric for consistency. Combined with validity, generation time, and proximity, we form a comprehensive metric set. We systematically benchmark 6 different CF methods on 20 univariate datasets and 10 multivariate datasets with 3 different classifiers. Results indicate that the performance of CF methods varies across metrics and among different models. Finally, we provide case studies and a guideline for practical usage.
Read more8/26/2024
🎯
0
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
Read more6/12/2024
0
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Kleopatra Markou, Dimitrios Tomaras, Vana Kalogeraki, Dimitrios Gunopulos
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.
Read more4/23/2024

0
Counterfactual Explanations for Multivariate Time-Series without Training Datasets
Xiangyu Sun, Raquel Aoki, Kevin H. Wilson
Machine learning (ML) methods have experienced significant growth in the past decade, yet their practical application in high-impact real-world domains has been hindered by their opacity. When ML methods are responsible for making critical decisions, stakeholders often require insights into how to alter these decisions. Counterfactual explanations (CFEs) have emerged as a solution, offering interpretations of opaque ML models and providing a pathway to transition from one decision to another. However, most existing CFE methods require access to the model's training dataset, few methods can handle multivariate time-series, and none can handle multivariate time-series without training datasets. These limitations can be formidable in many scenarios. In this paper, we present CFWoT, a novel reinforcement-learning-based CFE method that generates CFEs when training datasets are unavailable. CFWoT is model-agnostic and suitable for both static and multivariate time-series datasets with continuous and discrete features. Users have the flexibility to specify non-actionable, immutable, and preferred features, as well as causal constraints which CFWoT guarantees will be respected. We demonstrate the performance of CFWoT against four baselines on several datasets and find that, despite not having access to a training dataset, CFWoT finds CFEs that make significantly fewer and significantly smaller changes to the input time-series. These properties make CFEs more actionable, as the magnitude of change required to alter an outcome is vastly reduced.
Read more5/30/2024