Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming
2406.09891
0
0
Abstract
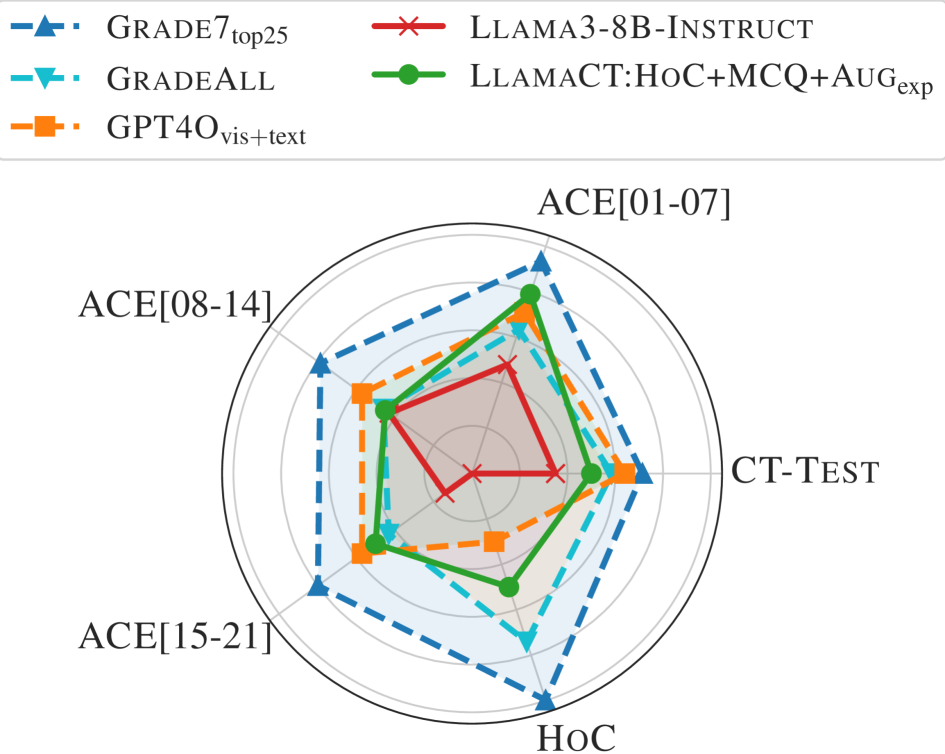
Generative models have demonstrated human-level proficiency in various benchmarks across domains like programming, natural sciences, and general knowledge. Despite these promising results on competitive benchmarks, they still struggle with seemingly simple problem-solving tasks typically carried out by elementary-level students. How do state-of-the-art models perform on standardized tests designed to assess computational thinking and problem-solving skills at schools? In this paper, we curate a novel benchmark involving computational thinking tests grounded in elementary visual programming domains. Our initial results show that state-of-the-art models like GPT-4o and Llama3 barely match the performance of an average school student. To further boost the performance of these models, we fine-tune them using a novel synthetic data generation methodology. The key idea is to develop a comprehensive dataset using symbolic methods that capture different skill levels, ranging from recognition of visual elements to multi-choice quizzes to synthesis-style tasks. We showcase how various aspects of symbolic information in synthetic data help improve fine-tuned models' performance. We will release the full implementation and datasets to facilitate further research on enhancing computational thinking in generative models.
Create account to get full access
Overview
- This paper investigates the performance of generative AI models on computational thinking tests in an elementary visual programming environment.
- The researchers evaluate how well language models like GPT-3 can solve coding challenges designed to assess logical reasoning and problem-solving skills.
- The goal is to better understand the capabilities and limitations of these AI systems when it comes to computational thinking, an important skill for education and problem-solving.
Plain English Explanation
The researchers wanted to see how well AI language models like GPT-3 could perform on coding challenges designed for young students learning to program. These challenges are meant to test computational thinking skills - the ability to break down problems, identify patterns, and create step-by-step solutions.
By having the AI models attempt these tasks, the researchers could get a sense of the models' capabilities when it comes to the kind of logical reasoning and problem-solving involved in programming. This could provide insights into how well these AI systems might be able to assist or even replace humans in certain educational or problem-solving contexts.
For example, language models trained on vast amounts of text data have shown impressive abilities to generate coherent code. But can they truly understand and apply the principles of computational thinking required for more complex coding challenges? The results of this study could help answer that question.
Technical Explanation
The researchers designed experiments to evaluate how well different generative language models, including GPT-3, could perform on a set of computational thinking tests in an elementary visual programming environment.
The tests were based on the Computational Thinking Test Suite and covered skills like pattern recognition, abstraction, and algorithm design. The models were prompted to generate code or step-by-step solutions to solve the challenges.
The researchers also explored the use of prompting techniques to help the models perform better on the tests, such as providing examples or guiding questions.
Furthermore, the paper introduces a symbolic framework for evaluating the models' reasoning and generalization abilities on the computational thinking tasks.
Critical Analysis
The paper provides a comprehensive and well-designed study on the capabilities of generative language models in the domain of computational thinking. The researchers have carefully constructed a set of relevant tests and explored various prompting strategies to assess the models' performance.
One potential limitation is the use of a relatively small set of computational thinking tests, which may not fully capture the breadth of skills involved. Additionally, the study focuses on visual programming environments, which could have different challenges compared to text-based programming.
Further research could explore a wider range of computational thinking tests, including those used in real-world educational settings. It would also be interesting to see how the models' performance compares to human students on these tasks.
Overall, this paper makes a valuable contribution to understanding the intersection of AI and computational thinking, an important area for both education and problem-solving applications.
Conclusion
This study provides a rigorous evaluation of how well generative language models can perform on computational thinking tests in a visual programming environment. The results shed light on the capabilities and limitations of these AI systems when it comes to the logical reasoning and problem-solving skills required for coding and computer science education.
The findings have implications for the potential use of language models in educational contexts, as well as for developing AI systems that can truly understand and apply computational thinking principles. The researchers' introduction of a symbolic framework for evaluating these skills is also a notable contribution to the field.
While further research is needed, this paper represents an important step in exploring the intersection of AI and computational thinking, an area that will continue to grow in significance as technology plays an increasingly central role in education and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment
Chao Wen, Jacqueline Staub, Adish Singla
0
0
Large language and multimodal models have shown remarkable successes on various benchmarks focused on specific skills such as general-purpose programming, natural language understanding, math word problem-solving, and visual question answering. However, it is unclear how well these models perform on tasks that require a combination of these skills. In this paper, we curate a novel program synthesis benchmark based on the XLogoOnline visual programming environment. The benchmark comprises 85 real-world tasks from the Mini-level of the XLogoOnline environment, each requiring a combination of different skills such as spatial planning, basic programming, and logical reasoning. Our evaluation shows that current state-of-the-art models like GPT-4V and Llama3-70B struggle to solve these tasks, achieving only 20% and 2.35% success rates. Next, we develop a fine-tuning pipeline to boost the performance of models by leveraging a large-scale synthetic training dataset with over 80000 tasks. Moreover, we showcase how emulator-driven feedback can be used to design a curriculum over training data distribution. We showcase that a fine-tuned Llama3-8B drastically outperforms GPT-4V and Llama3-70B models, and provide an in-depth analysis of the models' expertise across different skill dimensions. We will publicly release the benchmark for future research on program synthesis in visual programming.
6/18/2024
📊
Beyond Generating Code: Evaluating GPT on a Data Visualization Course
Chen Zhu-Tian, Chenyang Zhang, Qianwen Wang, Jakob Troidl, Simon Warchol, Johanna Beyer, Nils Gehlenborg, Hanspeter Pfister
0
0
This paper presents an empirical evaluation of the performance of the Generative Pre-trained Transformer (GPT) model in Harvard's CS171 data visualization course. While previous studies have focused on GPT's ability to generate code for visualizations, this study goes beyond code generation to evaluate GPT's abilities in various visualization tasks, such as data interpretation, visualization design, visual data exploration, and insight communication. The evaluation utilized GPT-3.5 and GPT-4 to complete assignments of CS171, and included a quantitative assessment based on the established course rubrics, a qualitative analysis informed by the feedback of three experienced graders, and an exploratory study of GPT's capabilities in completing border visualization tasks. Findings show that GPT-4 scored 80% on quizzes and homework, and TFs could distinguish between GPT- and human-generated homework with 70% accuracy. The study also demonstrates GPT's potential in completing various visualization tasks, such as data cleanup, interaction with visualizations, and insight communication. The paper concludes by discussing the strengths and limitations of GPT in data visualization, potential avenues for incorporating GPT in broader visualization tasks, and the need to redesign visualization education.
5/14/2024

Measuring Vision-Language STEM Skills of Neural Models
Jianhao Shen, Ye Yuan, Srbuhi Mirzoyan, Ming Zhang, Chenguang Wang
0
0
We introduce a new challenge to test the STEM skills of neural models. The problems in the real world often require solutions, combining knowledge from STEM (science, technology, engineering, and math). Unlike existing datasets, our dataset requires the understanding of multimodal vision-language information of STEM. Our dataset features one of the largest and most comprehensive datasets for the challenge. It includes 448 skills and 1,073,146 questions spanning all STEM subjects. Compared to existing datasets that often focus on examining expert-level ability, our dataset includes fundamental skills and questions designed based on the K-12 curriculum. We also add state-of-the-art foundation models such as CLIP and GPT-3.5-Turbo to our benchmark. Results show that the recent model advances only help master a very limited number of lower grade-level skills (2.5% in the third grade) in our dataset. In fact, these models are still well below (averaging 54.7%) the performance of elementary students, not to mention near expert-level performance. To understand and increase the performance on our dataset, we teach the models on a training split of our dataset. Even though we observe improved performance, the model performance remains relatively low compared to average elementary students. To solve STEM problems, we will need novel algorithmic innovations from the community.
5/24/2024
⚙️
A Symbolic Framework for Evaluating Mathematical Reasoning and Generalisation with Transformers
Jordan Meadows, Marco Valentino, Damien Teney, Andre Freitas
0
0
This paper proposes a methodology for generating and perturbing detailed derivations of equations at scale, aided by a symbolic engine, to evaluate the generalisability of Transformers to out-of-distribution mathematical reasoning problems. Instantiating the framework in the context of sequence classification tasks, we compare the capabilities of GPT-4, GPT-3.5, and a canon of fine-tuned BERT models, exploring the relationship between specific operators and generalisation failure via the perturbation of reasoning aspects such as symmetry and variable surface forms. Surprisingly, our empirical evaluation reveals that the average in-distribution performance of fine-tuned models surpasses GPT-3.5, and rivals GPT-4. However, perturbations to input reasoning can reduce their performance by up to 80 F1 points. Overall, the results suggest that the in-distribution performance of smaller open-source models may potentially rival GPT by incorporating appropriately structured derivation dependencies during training, and highlight a shared weakness between BERT and GPT involving a relative inability to decode indirect references to mathematical entities. We release the full codebase, constructed datasets, and fine-tuned models to encourage future progress in the field.
4/9/2024