Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment
2406.11334
0
0

Abstract
Large language and multimodal models have shown remarkable successes on various benchmarks focused on specific skills such as general-purpose programming, natural language understanding, math word problem-solving, and visual question answering. However, it is unclear how well these models perform on tasks that require a combination of these skills. In this paper, we curate a novel program synthesis benchmark based on the XLogoOnline visual programming environment. The benchmark comprises 85 real-world tasks from the Mini-level of the XLogoOnline environment, each requiring a combination of different skills such as spatial planning, basic programming, and logical reasoning. Our evaluation shows that current state-of-the-art models like GPT-4V and Llama3-70B struggle to solve these tasks, achieving only 20% and 2.35% success rates. Next, we develop a fine-tuning pipeline to boost the performance of models by leveraging a large-scale synthetic training dataset with over 80000 tasks. Moreover, we showcase how emulator-driven feedback can be used to design a curriculum over training data distribution. We showcase that a fine-tuned Llama3-8B drastically outperforms GPT-4V and Llama3-70B models, and provide an in-depth analysis of the models' expertise across different skill dimensions. We will publicly release the benchmark for future research on program synthesis in visual programming.
Create account to get full access
Overview
• This paper presents a program synthesis benchmark for visual programming in the XLogoOnline environment, which is a web-based platform for teaching and learning programming concepts through a visual programming language. • The benchmark aims to assess the ability of program synthesis models, including large language models, to generate code that solves a variety of programming tasks in the XLogoOnline environment. • The paper also discusses related work on benchmarking computational thinking and programming skills, as well as research on using large language models for programming tasks.
Plain English Explanation
The paper describes a new way to test how well different AI systems can write computer programs. The researchers created a set of programming challenges that use a visual programming language called XLogoOnline. XLogoOnline is a web-based tool that helps people learn programming by letting them drag and drop programming blocks to create programs, rather than typing out code.
The researchers want to see how well AI systems, including large language models like GPT-3, can generate the correct programming blocks to solve these XLogoOnline challenges. This could be useful for creating AI assistants that can help people learn to program or even write simple programs automatically.
The paper also discusses other research on testing people's computational thinking skills and using large language models for programming tasks. By creating this XLogoOnline benchmark, the researchers hope to advance the field of program synthesis, which is the process of automatically generating computer programs from high-level descriptions or examples.
Technical Explanation
The paper introduces a Program Synthesis Benchmark for Visual Programming in XLogoOnline Environment. This benchmark aims to assess the ability of program synthesis models, including large language models, to generate code that solves a variety of programming tasks in the XLogoOnline environment.
XLogoOnline is a web-based platform for teaching and learning programming concepts through a visual programming language. The benchmark consists of a set of programming challenges that users must solve by arranging visual programming blocks in the XLogoOnline environment.
The paper discusses related work on benchmarking computational thinking and programming skills and research on using large language models for programming tasks, including student modeling and program synthesis and guiding enumerative program synthesis with large language models.
Critical Analysis
The paper presents a novel benchmark for assessing program synthesis capabilities in a visual programming environment. This is a valuable contribution, as it provides a standardized way to evaluate the performance of AI systems on a specific set of programming tasks.
One potential limitation of the benchmark is that it may not capture the full complexity of real-world programming tasks, which often involve more than just arranging visual blocks. The paper acknowledges this and suggests that the benchmark could be extended to include more advanced programming concepts and constructs.
Additionally, the paper does not provide a comprehensive analysis of the performance of different program synthesis models on the benchmark. It would be interesting to see how various approaches, including large language models, perform on the tasks and what insights can be drawn from their successes and failures.
Conclusion
This paper introduces a program synthesis benchmark for visual programming in the XLogoOnline environment. The benchmark aims to assess the ability of AI systems, including large language models, to generate code that solves a variety of programming tasks in this visual programming environment.
The paper discusses related work on benchmarking computational thinking and programming skills, as well as research on using large language models for programming tasks. The introduction of this benchmark represents a valuable contribution to the field of program synthesis, as it provides a standardized way to evaluate the performance of AI systems on a specific set of programming challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Task Synthesis for Elementary Visual Programming in XLogoOnline Environment
Chao Wen, Ahana Ghosh, Jacqueline Staub, Adish Singla
0
0
In recent years, the XLogoOnline programming platform has gained popularity among novice learners. It integrates the Logo programming language with visual programming, providing a visual interface for learning computing concepts. However, XLogoOnline offers only a limited set of tasks, which are inadequate for learners to master the computing concepts that require sufficient practice. To address this, we introduce XLogoSyn, a novel technique for synthesizing high-quality tasks for varying difficulty levels. Given a reference task, XLogoSyn can generate practice tasks at varying difficulty levels that cater to the varied needs and abilities of different learners. XLogoSyn achieves this by combining symbolic execution and constraint satisfaction techniques. Our expert study demonstrates the effectiveness of XLogoSyn. We have also deployed synthesized practice tasks into XLogoOnline, highlighting the educational benefits of these synthesized practice tasks.
5/6/2024
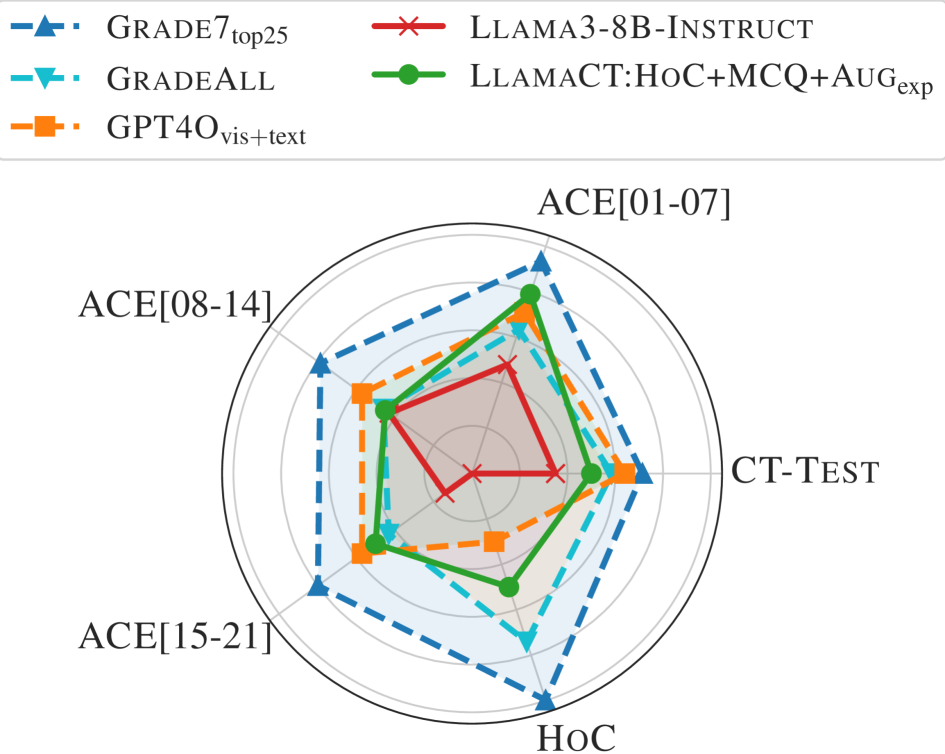
Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming
Victor-Alexandru Pu{a}durean, Adish Singla
0
0
Generative models have demonstrated human-level proficiency in various benchmarks across domains like programming, natural sciences, and general knowledge. Despite these promising results on competitive benchmarks, they still struggle with seemingly simple problem-solving tasks typically carried out by elementary-level students. How do state-of-the-art models perform on standardized tests designed to assess computational thinking and problem-solving skills at schools? In this paper, we curate a novel benchmark involving computational thinking tests grounded in elementary visual programming domains. Our initial results show that state-of-the-art models like GPT-4o and Llama3 barely match the performance of an average school student. To further boost the performance of these models, we fine-tune them using a novel synthetic data generation methodology. The key idea is to develop a comprehensive dataset using symbolic methods that capture different skill levels, ranging from recognition of visual elements to multi-choice quizzes to synthesis-style tasks. We showcase how various aspects of symbolic information in synthetic data help improve fine-tuned models' performance. We will release the full implementation and datasets to facilitate further research on enhancing computational thinking in generative models.
6/17/2024
Hints-In-Browser: Benchmarking Language Models for Programming Feedback Generation
Nachiket Kotalwar, Alkis Gotovos, Adish Singla
0
0
Generative AI and large language models hold great promise in enhancing programming education by generating individualized feedback and hints for learners. Recent works have primarily focused on improving the quality of generated feedback to achieve human tutors' quality. While quality is an important performance criterion, it is not the only criterion to optimize for real-world educational deployments. In this paper, we benchmark language models for programming feedback generation across several performance criteria, including quality, cost, time, and data privacy. The key idea is to leverage recent advances in the new paradigm of in-browser inference that allow running these models directly in the browser, thereby providing direct benefits across cost and data privacy. To boost the feedback quality of small models compatible with in-browser inference engines, we develop a fine-tuning pipeline based on GPT-4 generated synthetic data. We showcase the efficacy of fine-tuned Llama3-8B and Phi3-3.8B 4-bit quantized models using WebLLM's in-browser inference engine on three different Python programming datasets. We will release the full implementation along with a web app and datasets to facilitate further research on in-browser language models.
6/10/2024
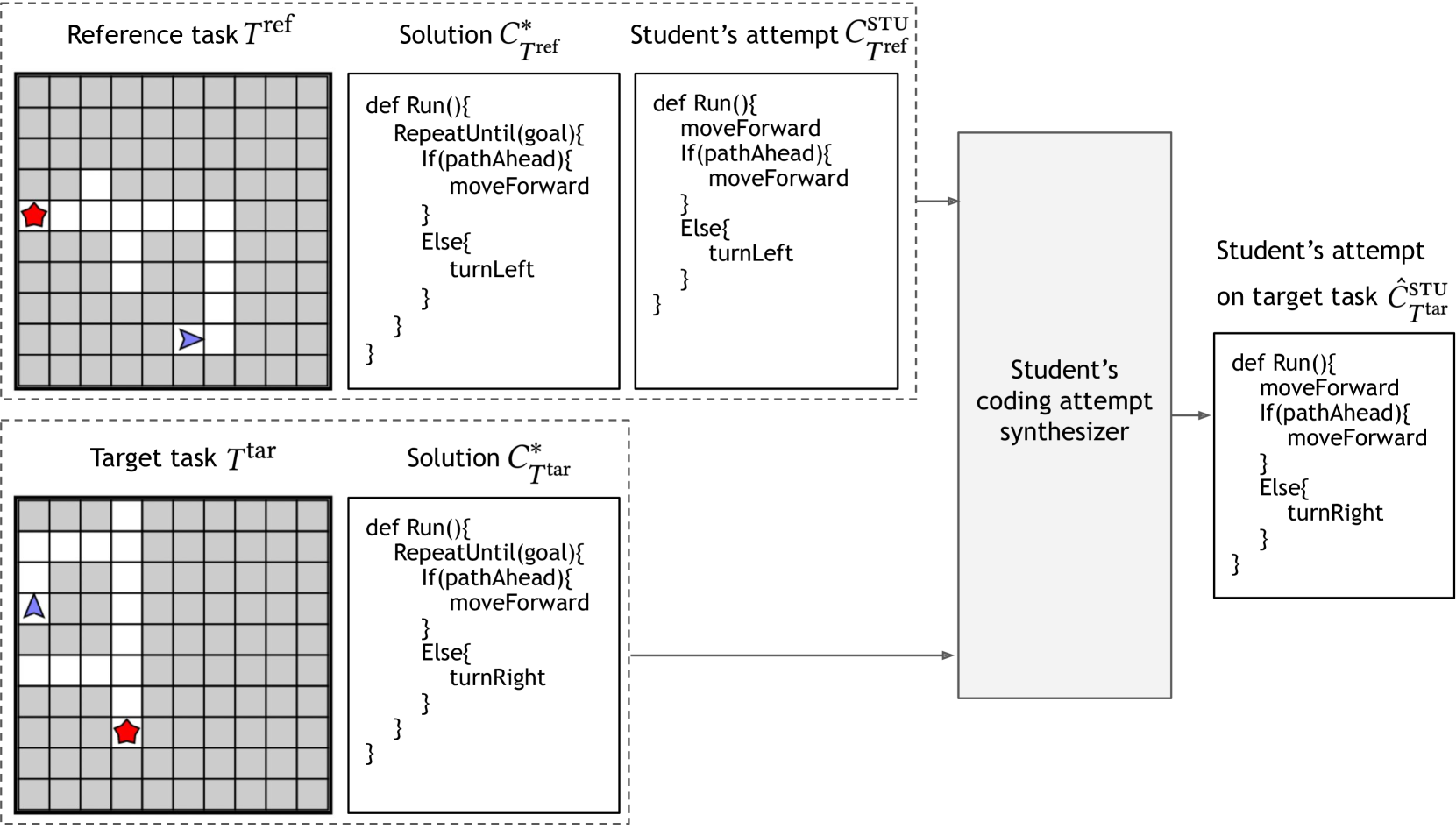
Large Language Models for In-Context Student Modeling: Synthesizing Student's Behavior in Visual Programming
Manh Hung Nguyen, Sebastian Tschiatschek, Adish Singla
0
0
Student modeling is central to many educational technologies as it enables predicting future learning outcomes and designing targeted instructional strategies. However, open-ended learning domains pose challenges for accurately modeling students due to the diverse behaviors and a large space of possible misconceptions. To approach these challenges, we explore the application of large language models (LLMs) for in-context student modeling in open-ended learning domains. More concretely, given a particular student's attempt on a reference task as observation, the objective is to synthesize the student's attempt on a target task. We introduce a novel framework, LLM for Student Synthesis (LLM-SS), that leverages LLMs for synthesizing a student's behavior. Our framework can be combined with different LLMs; moreover, we fine-tune LLMs to boost their student modeling capabilities. We instantiate several methods based on LLM-SS framework and evaluate them using an existing benchmark, StudentSyn, for student attempt synthesis in a visual programming domain. Experimental results show that our methods perform significantly better than the baseline method NeurSS provided in the StudentSyn benchmark. Furthermore, our method using a fine-tuned version of the GPT-3.5 model is significantly better than using the base GPT-3.5 model and gets close to human tutors' performance.
5/7/2024