Measuring Vision-Language STEM Skills of Neural Models
2402.17205
0
0

Abstract
We introduce a new challenge to test the STEM skills of neural models. The problems in the real world often require solutions, combining knowledge from STEM (science, technology, engineering, and math). Unlike existing datasets, our dataset requires the understanding of multimodal vision-language information of STEM. Our dataset features one of the largest and most comprehensive datasets for the challenge. It includes 448 skills and 1,073,146 questions spanning all STEM subjects. Compared to existing datasets that often focus on examining expert-level ability, our dataset includes fundamental skills and questions designed based on the K-12 curriculum. We also add state-of-the-art foundation models such as CLIP and GPT-3.5-Turbo to our benchmark. Results show that the recent model advances only help master a very limited number of lower grade-level skills (2.5% in the third grade) in our dataset. In fact, these models are still well below (averaging 54.7%) the performance of elementary students, not to mention near expert-level performance. To understand and increase the performance on our dataset, we teach the models on a training split of our dataset. Even though we observe improved performance, the model performance remains relatively low compared to average elementary students. To solve STEM problems, we will need novel algorithmic innovations from the community.
Create account to get full access
Overview
- The paper introduces a new benchmark called the STEM Benchmark to assess the vision-language skills of neural models in STEM (Science, Technology, Engineering, and Mathematics) domains.
- The benchmark includes a diverse dataset of STEM-related images and questions that test models' abilities to understand, reason about, and solve STEM-related problems.
- The authors evaluate several state-of-the-art vision-language models on the STEM Benchmark and provide insights into their strengths, weaknesses, and potential areas for improvement.
Plain English Explanation
The paper presents a new way to test the capabilities of AI models that combine visual and language understanding, specifically in the STEM (Science, Technology, Engineering, and Mathematics) fields. The researchers created a STEM Benchmark dataset with a variety of STEM-related images and questions that require the models to understand, reason about, and solve problems in these domains.
The authors then evaluated several state-of-the-art AI models that can process both images and text on this STEM Benchmark. This allowed them to see how well these models perform on tasks that involve both visual information and STEM-specific knowledge and skills. The results provide insights into the current capabilities and limitations of these vision-language models in STEM-related applications, which could help guide future research and development in this area.
Technical Explanation
The paper introduces the STEM Benchmark, a new dataset designed to assess the vision-language skills of neural models in STEM domains. The dataset consists of a diverse collection of STEM-related images, such as diagrams, illustrations, and photographs, along with associated questions that test the models' ability to understand, reason about, and solve STEM-related problems.
The authors evaluate several state-of-the-art vision-language models, including CLIP and LXMERT, on the STEM Benchmark. The models are tasked with answering questions about the STEM-related images, which require a combination of visual understanding, language comprehension, and STEM-specific knowledge and reasoning skills.
The results of the evaluation provide insights into the strengths, weaknesses, and potential areas for improvement of these vision-language models in STEM-related tasks. The authors discuss the implications of their findings for the development of more capable and robust multimodal AI systems that can effectively tackle STEM-related problems.
Critical Analysis
The STEM Benchmark presented in this paper is a valuable contribution to the field of multimodal AI research. By focusing on STEM-specific tasks, the benchmark fills an important gap in the existing evaluation frameworks for vision-language models. The diverse dataset and the range of STEM-related questions provide a more comprehensive assessment of these models' capabilities in real-world STEM applications.
However, the paper does mention some limitations of the STEM Benchmark, such as the potential bias in the dataset and the need for further expansion and refinement of the benchmark tasks. Additionally, the evaluation of the vision-language models is limited to a few selected models, and there may be other approaches or architectures that could perform differently on the STEM Benchmark.
Furthermore, the paper does not delve into the broader implications of the findings for the development of more capable and trustworthy AI systems in STEM fields. Addressing issues such as interpretability, robustness, and generalization would be crucial for the successful deployment of these technologies in real-world STEM-related applications.
Conclusion
The STEM Benchmark introduced in this paper represents an important step towards evaluating the vision-language skills of neural models in STEM domains. The comprehensive dataset and the insights gained from the model evaluations provide valuable guidance for the development of more capable and robust multimodal AI systems that can effectively tackle STEM-related problems.
As the field of vision-language models continues to evolve, the STEM Benchmark can serve as a valuable tool for benchmarking and advancing the state of the art in this area, ultimately contributing to the broader goal of creating AI systems that can seamlessly integrate visual and linguistic understanding to solve complex problems in STEM fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating Large Vision-and-Language Models on Children's Mathematical Olympiads
Anoop Cherian, Kuan-Chuan Peng, Suhas Lohit, Joanna Matthiesen, Kevin Smith, Joshua B. Tenenbaum
0
0
Recent years have seen a significant progress in the general-purpose problem solving abilities of large vision and language models (LVLMs), such as ChatGPT, Gemini, etc.; some of these breakthroughs even seem to enable AI models to outperform human abilities in varied tasks that demand higher-order cognitive skills. Are the current large AI models indeed capable of generalized problem solving as humans do? A systematic analysis of AI capabilities for joint vision and text reasoning, however, is missing in the current scientific literature. In this paper, we make an effort towards filling this gap, by evaluating state-of-the-art LVLMs on their mathematical and algorithmic reasoning abilities using visuo-linguistic problems from children's Olympiads. Specifically, we consider problems from the Mathematical Kangaroo (MK) Olympiad, which is a popular international competition targeted at children from grades 1-12, that tests children's deeper mathematical abilities using puzzles that are appropriately gauged to their age and skills. Using the puzzles from MK, we created a dataset, dubbed SMART-840, consisting of 840 problems from years 2020-2024. With our dataset, we analyze LVLMs power on mathematical reasoning; their responses on our puzzles offer a direct way to compare against that of children. Our results show that modern LVLMs do demonstrate increasingly powerful reasoning skills in solving problems for higher grades, but lack the foundations to correctly answer problems designed for younger children. Further analysis shows that there is no significant correlation between the reasoning capabilities of AI models and that of young children, and their capabilities appear to be based on a different type of reasoning than the cumulative knowledge that underlies children's mathematics and logic skills.
6/26/2024
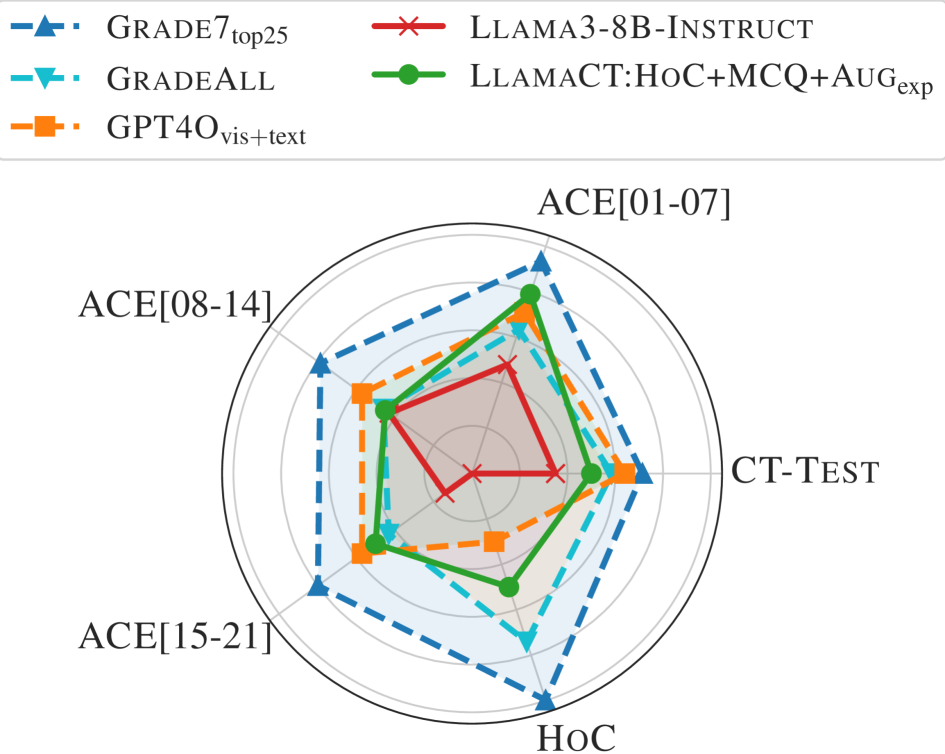
Benchmarking Generative Models on Computational Thinking Tests in Elementary Visual Programming
Victor-Alexandru Pu{a}durean, Adish Singla
0
0
Generative models have demonstrated human-level proficiency in various benchmarks across domains like programming, natural sciences, and general knowledge. Despite these promising results on competitive benchmarks, they still struggle with seemingly simple problem-solving tasks typically carried out by elementary-level students. How do state-of-the-art models perform on standardized tests designed to assess computational thinking and problem-solving skills at schools? In this paper, we curate a novel benchmark involving computational thinking tests grounded in elementary visual programming domains. Our initial results show that state-of-the-art models like GPT-4o and Llama3 barely match the performance of an average school student. To further boost the performance of these models, we fine-tune them using a novel synthetic data generation methodology. The key idea is to develop a comprehensive dataset using symbolic methods that capture different skill levels, ranging from recognition of visual elements to multi-choice quizzes to synthesis-style tasks. We showcase how various aspects of symbolic information in synthetic data help improve fine-tuned models' performance. We will release the full implementation and datasets to facilitate further research on enhancing computational thinking in generative models.
6/17/2024
👀
Evaluating ChatGPT-4 Vision on Brazil's National Undergraduate Computer Science Exam
Nabor C. Mendonc{c}a
0
0
The recent integration of visual capabilities into Large Language Models (LLMs) has the potential to play a pivotal role in science and technology education, where visual elements such as diagrams, charts, and tables are commonly used to improve the learning experience. This study investigates the performance of ChatGPT-4 Vision, OpenAI's most advanced visual model at the time the study was conducted, on the Bachelor in Computer Science section of Brazil's 2021 National Undergraduate Exam (ENADE). By presenting the model with the exam's open and multiple-choice questions in their original image format and allowing for reassessment in response to differing answer keys, we were able to evaluate the model's reasoning and self-reflecting capabilities in a large-scale academic assessment involving textual and visual content. ChatGPT-4 Vision significantly outperformed the average exam participant, positioning itself within the top 10 best score percentile. While it excelled in questions that incorporated visual elements, it also encountered challenges with question interpretation, logical reasoning, and visual acuity. The involvement of an independent expert panel to review cases of disagreement between the model and the answer key revealed some poorly constructed questions containing vague or ambiguous statements, calling attention to the critical need for improved question design in future exams. Our findings suggest that while ChatGPT-4 Vision shows promise in multimodal academic evaluations, human oversight remains crucial for verifying the model's accuracy and ensuring the fairness of high-stakes educational exams. The paper's research materials are publicly available at https://github.com/nabormendonca/gpt-4v-enade-cs-2021.
6/17/2024
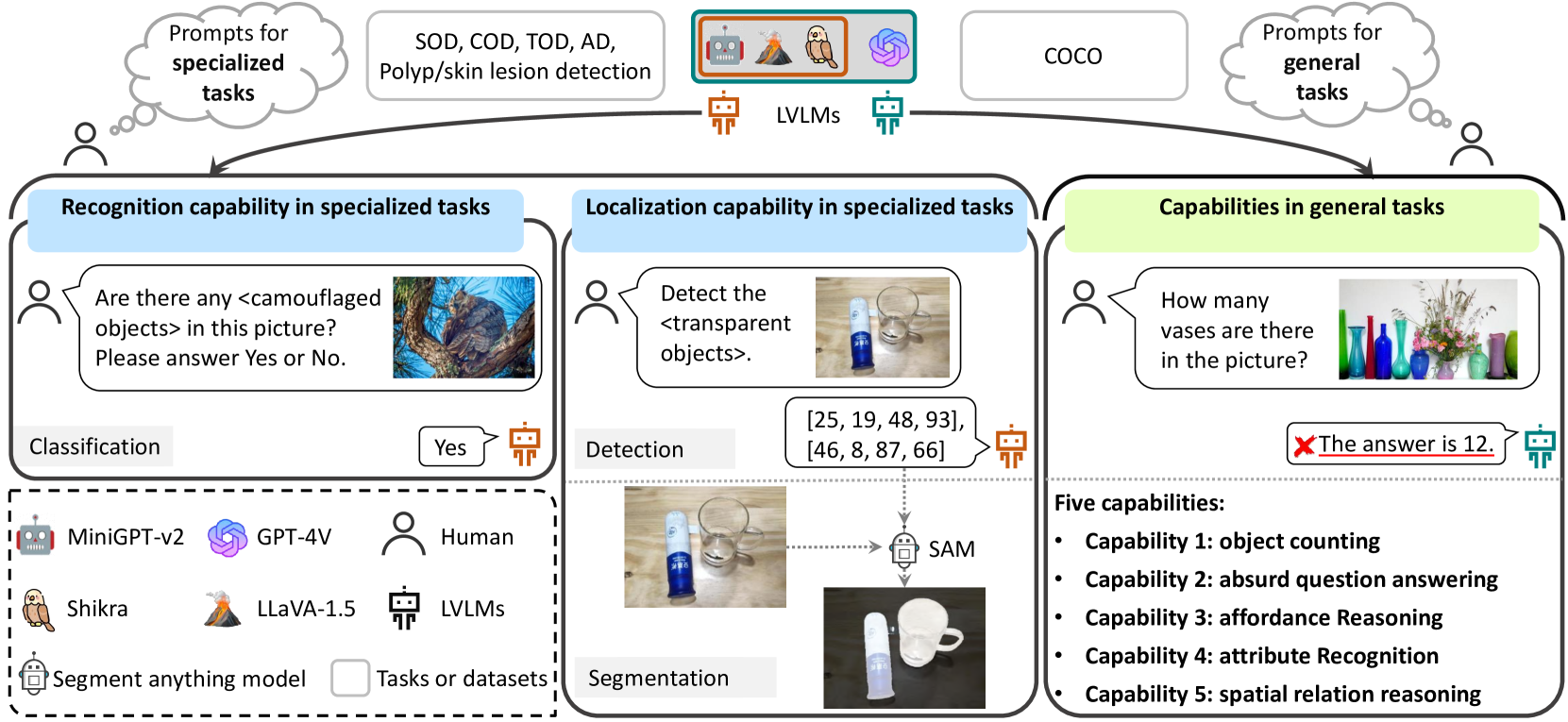
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
6/12/2024