Watermarking Counterfactual Explanations
2405.18671
0
0
Abstract
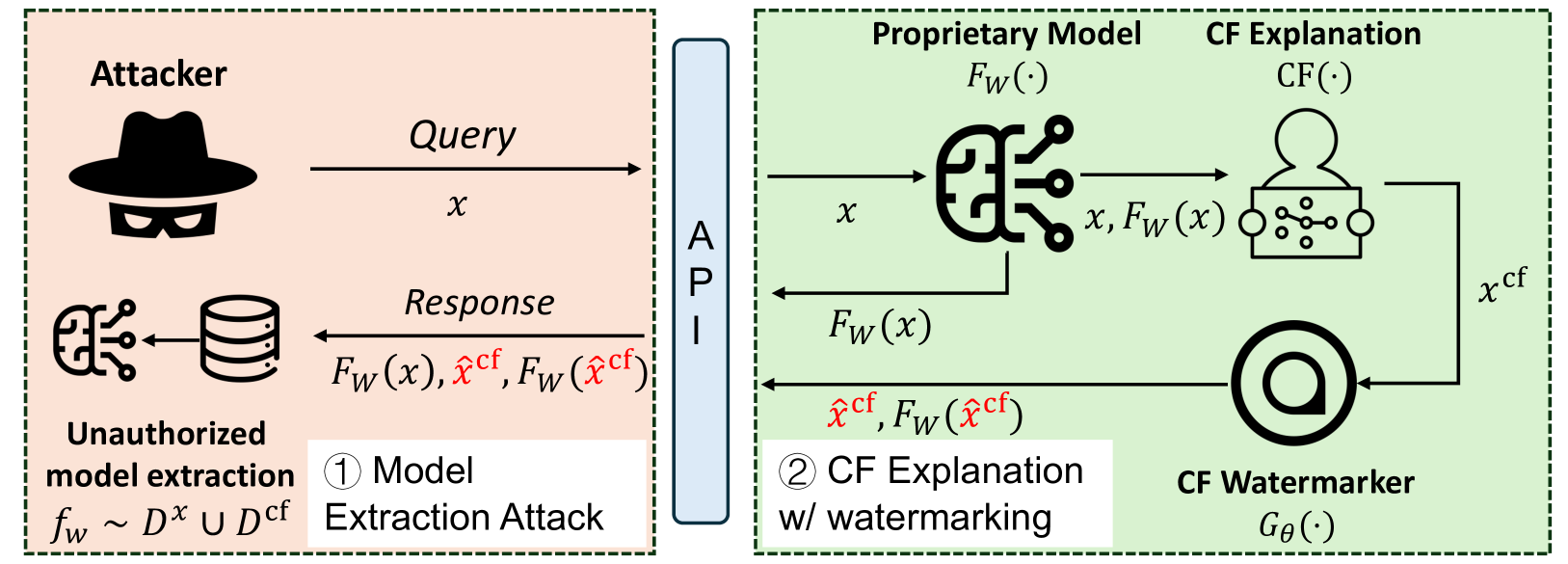
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
Create account to get full access
Overview
- This paper proposes a novel method for watermarking counterfactual explanations, which are a type of explanation for machine learning models that shows how the output would change if certain inputs were modified.
- The authors aim to protect the intellectual property of these counterfactual explanations by embedding a unique watermark in each explanation.
- The watermark is designed to be robust and imperceptible, allowing the explanations to be used normally while still enabling the original creator to be identified.
Plain English Explanation
Counterfactual explanations are a way to understand how machine learning models make decisions. They show what would happen if you changed certain inputs to the model. For example, a counterfactual explanation for a loan application might say "If your income was $5,000 higher, you would have been approved."
The problem is that these counterfactual explanations can be valuable intellectual property, and someone could try to copy or reuse them without permission. This paper proposes a solution to this by embedding a unique watermark into each counterfactual explanation.
Just like a watermark on a document, this watermark is invisible to the naked eye but can be detected to prove the origin of the explanation. This allows the creator to protect their work while still letting people use the explanations normally.
The key idea is to modify the counterfactual explanation in a very subtle way that doesn't change its meaning or usefulness, but does embed a unique identifier. This is done through careful mathematical techniques that ensure the watermark is robust and hard to remove.
Overall, this method gives creators a way to protect their intellectual property around these valuable counterfactual explanations, while still allowing them to be shared and used freely.
Technical Explanation
The paper first provides background on counterfactual explanations and the need to protect them as intellectual property. It then introduces the concept of watermarking these explanations to enable traceability.
The core technical approach involves modifying the optimization problem used to generate counterfactual explanations. Specifically, an additional term is added to the objective function that incentivizes the inclusion of a unique watermark pattern. This watermark is designed to be imperceptible to the end user but detectable by the original creator.
The authors evaluate their watermarking method across several datasets and machine learning models. They show that the watermarked explanations maintain high fidelity to the original explanations, while the watermarks can be reliably extracted even after various attack attempts to remove them.
Importantly, the paper also considers the security of this watermarking scheme, analyzing potential attacks and ways to make the watermarks more robust. The authors demonstrate that their approach can withstand common attacks like random noise injection or optimization-based removal.
Critical Analysis
The key strength of this work is the novel application of watermarking techniques to the domain of counterfactual explanations. This addresses an important practical challenge around the intellectual property of these valuable model explanations.
That said, the paper does not deeply explore the potential trade-offs or unintended consequences of this watermarking approach. For example, it's unclear how the watermark might interact with other desirable properties of counterfactual explanations, such as plausibility or faithfulness.
Additionally, while the security analysis is promising, real-world attackers may develop more sophisticated techniques to remove or forge watermarks that are not considered here. Further research would be needed to fully understand the long-term viability and robustness of this approach.
Overall, this is a valuable contribution that tackles an important problem, but there are still open questions and potential pitfalls that merit further exploration. Readers should think critically about the broader implications and limitations of this watermarking technique for counterfactual explanations.
Conclusion
This paper presents a novel method for watermarking counterfactual explanations, which are a powerful tool for understanding and interpreting the decisions of machine learning models. By embedding a unique, imperceptible watermark in each explanation, the authors enable the original creators to protect their intellectual property while still allowing the explanations to be used freely.
While more research is needed to fully assess the long-term viability and potential trade-offs of this approach, this work represents an important step forward in balancing the needs of model transparency and intellectual property protection. As AI systems become more widely deployed, techniques like this will be crucial for ensuring the responsible development and use of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge Distillation-Based Model Extraction Attack using Private Counterfactual Explanations
Fatima Ezzeddine, Omran Ayoub, Silvia Giordano
0
0
In recent years, there has been a notable increase in the deployment of machine learning (ML) models as services (MLaaS) across diverse production software applications. In parallel, explainable AI (XAI) continues to evolve, addressing the necessity for transparency and trustworthiness in ML models. XAI techniques aim to enhance the transparency of ML models by providing insights, in terms of the model's explanations, into their decision-making process. Simultaneously, some MLaaS platforms now offer explanations alongside the ML prediction outputs. This setup has elevated concerns regarding vulnerabilities in MLaaS, particularly in relation to privacy leakage attacks such as model extraction attacks (MEA). This is due to the fact that explanations can unveil insights about the inner workings of the model which could be exploited by malicious users. In this work, we focus on investigating how model explanations, particularly Generative adversarial networks (GANs)-based counterfactual explanations (CFs), can be exploited for performing MEA within the MLaaS platform. We also delve into assessing the effectiveness of incorporating differential privacy (DP) as a mitigation strategy. To this end, we first propose a novel MEA methodology based on Knowledge Distillation (KD) to enhance the efficiency of extracting a substitute model of a target model exploiting CFs. Then, we advise an approach for training CF generators incorporating DP to generate private CFs. We conduct thorough experimental evaluations on real-world datasets and demonstrate that our proposed KD-based MEA can yield a high-fidelity substitute model with reduced queries with respect to baseline approaches. Furthermore, our findings reveal that the inclusion of a privacy layer impacts the performance of the explainer, the quality of CFs, and results in a reduction in the MEA performance.
4/5/2024
🤖
Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to User Objectives
Orfeas Menis Mastromichalakis, Jason Liartis, Giorgos Stamou
0
0
Explainable Artificial Intelligence (XAI) has emerged as a critical area of research aimed at enhancing the transparency and interpretability of AI systems. Counterfactual Explanations (CFEs) offer valuable insights into the decision-making processes of machine learning algorithms by exploring alternative scenarios where certain factors differ. Despite the growing popularity of CFEs in the XAI community, existing literature often overlooks the diverse needs and objectives of users across different applications and domains, leading to a lack of tailored explanations that adequately address the different use cases. In this paper, we advocate for a nuanced understanding of CFEs, recognizing the variability in desired properties based on user objectives and target applications. We identify three primary user objectives and explore the desired characteristics of CFEs in each case. By addressing these differences, we aim to design more effective and tailored explanations that meet the specific needs of users, thereby enhancing collaboration with AI systems.
4/16/2024
🎯
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
0
0
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
6/12/2024
Unifying Perspectives: Plausible Counterfactual Explanations on Global, Group-wise, and Local Levels
Patryk Wielopolski, Oleksii Furman, Jerzy Stefanowski, Maciej Zik{e}ba
0
0
Growing regulatory and societal pressures demand increased transparency in AI, particularly in understanding the decisions made by complex machine learning models. Counterfactual Explanations (CFs) have emerged as a promising technique within Explainable AI (xAI), offering insights into individual model predictions. However, to understand the systemic biases and disparate impacts of AI models, it is crucial to move beyond local CFs and embrace global explanations, which offer a~holistic view across diverse scenarios and populations. Unfortunately, generating Global Counterfactual Explanations (GCEs) faces challenges in computational complexity, defining the scope of global, and ensuring the explanations are both globally representative and locally plausible. We introduce a novel unified approach for generating Local, Group-wise, and Global Counterfactual Explanations for differentiable classification models via gradient-based optimization to address these challenges. This framework aims to bridge the gap between individual and systemic insights, enabling a deeper understanding of model decisions and their potential impact on diverse populations. Our approach further innovates by incorporating a probabilistic plausibility criterion, enhancing actionability and trustworthiness. By offering a cohesive solution to the optimization and plausibility challenges in GCEs, our work significantly advances the interpretability and accountability of AI models, marking a step forward in the pursuit of transparent AI.
5/29/2024